A unified acoustic-to-speech-to-language embedding space captures the neural basis of natural language processing in everyday conversations
100시간 일상 대화 기록으로 밝혀낸 뇌와 AI의 처리 방식 일치성
자연스러운 일상 대화는 인간만이 가진 가장 특별한 능력 중 하나다. 네이처 휴먼 비헤이비어(Nature Human Behaviour)에 게재된 연구에서 과학자들은 인간 뇌가 실제 대화에서 언어를 처리하는 방식을 이해하기 위한 획기적인 접근법을 선보였다. 구글 리서치(Google Research) 소속의 아리엘 골드스타인 박사와 프린스턴 신경과학 연구소 소속의 우리 하손(Uri Hasson) 연구팀은 통합된 음향-음성-언어 임베딩 공간을 활용하여 인간 뇌의 자연어 처리 과정을 분석했다. 특히 주목할 점은 오픈AI의 음성 인식 모델인 ‘위스퍼(Whisper)’의 내부 표현이 뇌의 활동 패턴과 놀랍도록 일치한다는 사실이다.
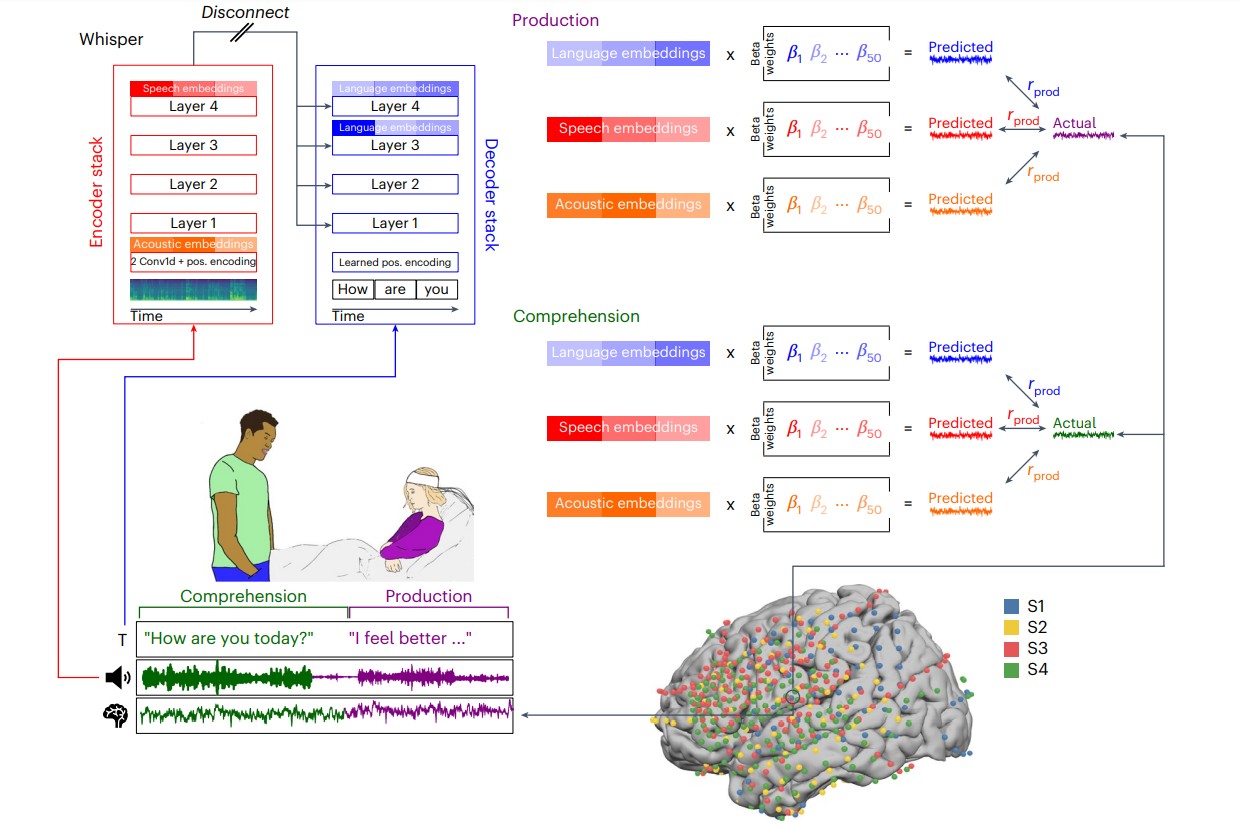
연구팀은 뇌전도(electrocorticography)를 사용해 4명의 환자가 약 100시간 동안 자연스러운 대화를 나누는 동안의 신경 신호를 기록했다. 이는 약 52만 단어에 해당하는 방대한 양의 데이터를 포함한다. 연구자들은 위스퍼 모델에서 추출한 임베딩(embedding)을 사용하여 뇌 활동을 예측하는 모델을 구축했다. 이 접근법은 기존의 언어학적 분석 방식과 달리, 인위적인 실험 환경이 아닌 실제 생활 속 자연스러운 대화를 분석했다는 점에서 큰 의의가 있다.
상측두회는 음성 처리, 하전두회는 언어 처리: AI 모델과 인간 뇌의 계층적 유사성
연구 결과, 위스퍼 모델의 내부 표현은 인간 뇌의 자연어 처리 계층 구조와 놀랍도록 잘 일치했다. 모델의 음성 임베딩은 상측두회(superior temporal gyrus)와 운동감각 영역과 같은 하위 수준의 지각 및 운동 영역의 활동을 더 잘 예측했다. 반면, 언어 임베딩은 하전두회(inferior frontal gyrus)와 각회(angular gyrus)와 같은 고차원 언어 영역의 활동을 더 잘 예측했다.
특히 주목할 만한 점은 위스퍼 모델이 음성 산출(발화) 전 약 300ms에서 언어-음성 인코딩의 시간적 순서를 정확히 포착했으며, 음성 이해 과정에서는 발화 후 음성-언어 인코딩의 역순을 포착했다는 점이다. 이런 결과는 인간 뇌와 AI 모델 사이의 유사성이 단순한 우연이 아니라, 언어 처리의 기본 원리를 반영한다는 것을 시사한다.
연구의 공동 저자인 아리엘 골드스타인(Ariel Goldstein)은 “위스퍼와 같은 모델의 내부 표현이 인간 뇌의 자연어 처리 과정과 상당히 일치한다는 사실이 놀랍다”고 말했다. 이는 신경과학과 AI의 교차점에서 새로운 통찰력을 제공하는 중요한 발견이다.
딥러닝 모델, 54~67% 정확도로 음소와 품사 예측하며 전통적 언어학 모델 압도
또 다른 중요한 발견은 위스퍼와 같은 딥 러닝 모델이 음소(phoneme), 품사(part of speech) 등 전통적인 상징적 언어학 모델보다 뇌 활동을 예측하는 데 훨씬 우수했다는 점이다. 연구팀은 상징적 언어 특성을 벡터화하여 비교했는데, 위스퍼의 임베딩이 모든 뇌 영역에서 뛰어난 예측력을 보였다.
위스퍼 모델이 명시적으로 음소나 품사와 같은 전통적인 언어학적 요소를 사용하여 학습되지 않았음에도 불구하고, 이러한 특성들이 모델 내부에서 자연스럽게 등장했다는 점도 주목할 만하다. 연구팀은 음성 임베딩에서 약 54%의 정확도로 음소를 분류할 수 있었고, 언어 임베딩에서는 약 67%의 정확도로 품사를 분류할 수 있었다. 이는 단순한 통계적 학습만으로도 의미 있는 언어학적 패턴이 자연스럽게 형성될 수 있음을 보여준다.
언어학의 패러다임 전환: 규칙 기반에서 통계적 학습 기반으로
이 연구는 자연어 처리에 대한 접근 방식에 큰 변화를 시사한다. 전통적인 언어학은 언어를 개별적인 하위 영역(음성학, 음운론, 형태론, 구문론, 의미론, 화용론 등)으로 나누어 연구하는 접근법을 취했다. 그러나 이러한 분할 정복 전략은 실제 대화에서 발생하는 미묘하고 비선형적인 상호작용을 설명하는 데 한계가 있었다.
이번 연구는 딥 러닝 기반의 통합된 계산 프레임워크가 인간의 자연어 처리 과정을 더 정확하게 모델링할 수 있음을 보여준다. 이는 “언어에 대한 상징적 접근법에서 통계적 학습과 고차원 임베딩 공간을 기반으로 한 모델로의 패러다임 전환”이라고 연구팀은 설명한다.
프린스턴 대학의 우리 하손(Uri Hasson) 교수는 “우리 연구는 상징적 규칙 기반 언어 모델에서 벗어나, 통계적 학습과 고차원 임베딩 공간에 기반한 새로운 모델 계열로의 전환을 제시한다”고 말했다. 이러한 모델은 자연스러운 대화의 풍부함과 다양성을 유지하면서도 실세계 데이터에서 언어 산출과 이해의 신경학적 기반을 설명할 수 있다.
FAQ
Q: 이 연구가 인공지능과 뇌과학에 어떤 의미가 있나요?
A: 이 연구는 AI 모델의 내부 작동 방식이 인간 뇌의 언어 처리 과정과 유사하다는 것을 보여줍니다. 이는 AI가 단순히 언어를 모방하는 것이 아니라, 인간의 언어 처리 메커니즘과 유사한 방식으로 작동할 수 있음을 시사합니다. 이런 유사성은 더 인간적인 AI 시스템 개발에 중요한 통찰력을 제공합니다.
Q: 위스퍼(Whisper) 모델이 무엇이며 이 연구에서 왜 중요한가요?
A: 위스퍼는 오픈AI가 개발한 음성 인식 모델로, 음향 신호를 텍스트로 변환하는 데 뛰어난 성능을 보입니다. 이 연구에서 위스퍼는 음향, 음성, 언어 수준의 정보를 모두 처리할 수 있는 통합 모델로 사용되었으며, 그 내부 표현이 인간 뇌의 활동 패턴과 놀랍도록 일치한다는 점이 밝혀졌습니다.
Q: 전통적인 언어학적 접근법과 딥 러닝 모델의 주요 차이점은 무엇인가요?
A: 전통적인 언어학은 음소, 품사와 같은 상징적 단위를 사용하여 언어를 분석합니다. 반면, 딥 러닝 모델은 이산적 상징 대신 다차원 벡터 표현(임베딩)을 사용합니다. 이 연구에 따르면, 딥 러닝 모델의 접근법이 실제 뇌 활동을 예측하는 데 더 효과적이며, 자연 언어의 복잡한 맥락 의존적 상호작용을 더 잘 포착할 수 있습니다.
해당 기사에서 인용한 논문 원문은 링크에서 확인할 수 있다.
이미지 출처: 이디오그램 생성
기사는 클로드와 챗GPT를 활용해 작성되었습니다.