
SYNTACTIC AND SEMANTIC CONTROL OF LARGE LANGUAGE MODELS VIA SEQUENTIAL MONTE CARLO
SMC 기술로 언어 모델 정밀 제어, 구문적·의미적 제약 준수하며 텍스트 생성 가능해져
대형 언어 모델(LLM)이 특정 제약조건을 준수하면서 텍스트를 생성하도록 하는 것은 많은 응용 분야에서 중요한 과제다. MIT, ETH 취리히, 맥길대학교 등이 참여한 연구팀은 대형 언어 모델의 출력을 정밀하게 제어할 수 있는 새로운 방법론을 개발했다. 연구진은 순차적 몬테카를로(Sequential Monte Carlo, SMC) 알고리즘을 활용한 프레임워크를 통해 언어 모델이 구문적, 의미적 제약을 준수하면서 텍스트를 생성하도록 했다.
이 연구에서 주목할 점은 기존 방식과 달리 제약 조건을 확률적 조건부 생성 문제로 정의하고, 효율적인 알고리즘을 통해 해결했다는 점이다. 연구팀은 “제약 조건을 확률적 관점에서 정의함으로써 자연스럽게 문제를 해결할 수 있었다”고 설명했다. 이런 접근법은 코드 생성, 텍스트-SQL 변환, 목표 추론, 분자 합성 등 다양한 영역에서 효과적임이 입증됐다.
8배 작은 모델도 대형 모델 성능 넘어서, SMC 적용한 라마 3.1 70B가 175B Codex-002 능가
가장 놀라운 발견은 SMC 프레임워크를 적용했을 때 상대적으로 작은 규모의 오픈소스 언어 모델이 8배 이상 큰 모델보다 더 좋은 성능을 보였다는 점이다. 이는 단순히 모델 크기를 키우는 것보다 효율적인 추론 알고리즘을 적용하는 것이 성능 향상에 더 효과적일 수 있음을 시사한다.
연구팀의 실험에 따르면, 데이터 과학 코드 생성 태스크(DS-1000)에서 SMC를 적용한 라마 3.1 70B 모델은 코딩 태스크에 특화된 175B 파라미터 규모의 Codex-002 모델보다 더 좋은 성능을 보였다. 특히 목표 추론, 분자 합성, 데이터 과학 세 영역에서 SMC를 적용한 Llama 3.1 8B 모델은 8배 더 큰 모델보다 우수한 성능을 달성했다. 또한 SMC 방식은 생성 마지막 단계에서만 제약을 적용하는 방식보다 5-10배 적은 파티클(계산 단위)만으로도 더 좋은 결과를 얻었다.
“계산 자원을 재할당하는 방식으로, 더 유망한 부분 시퀀스에 집중할 수 있게 해 계산 효율성을 크게 높였다”고 연구팀은 설명했다. 연구 결과에 따르면, 세 개 도메인(데이터 과학, 분자 합성, 텍스트-SQL)에서 SMC는 다른 방법론과 비교해 10분의 1의 파티클만으로도 동등하거나 더 나은 성능을 달성했다. 이는 제한된 컴퓨팅 자원을 가진 환경에서도 고품질의 언어 모델 출력을 얻을 수 있음을 의미한다.
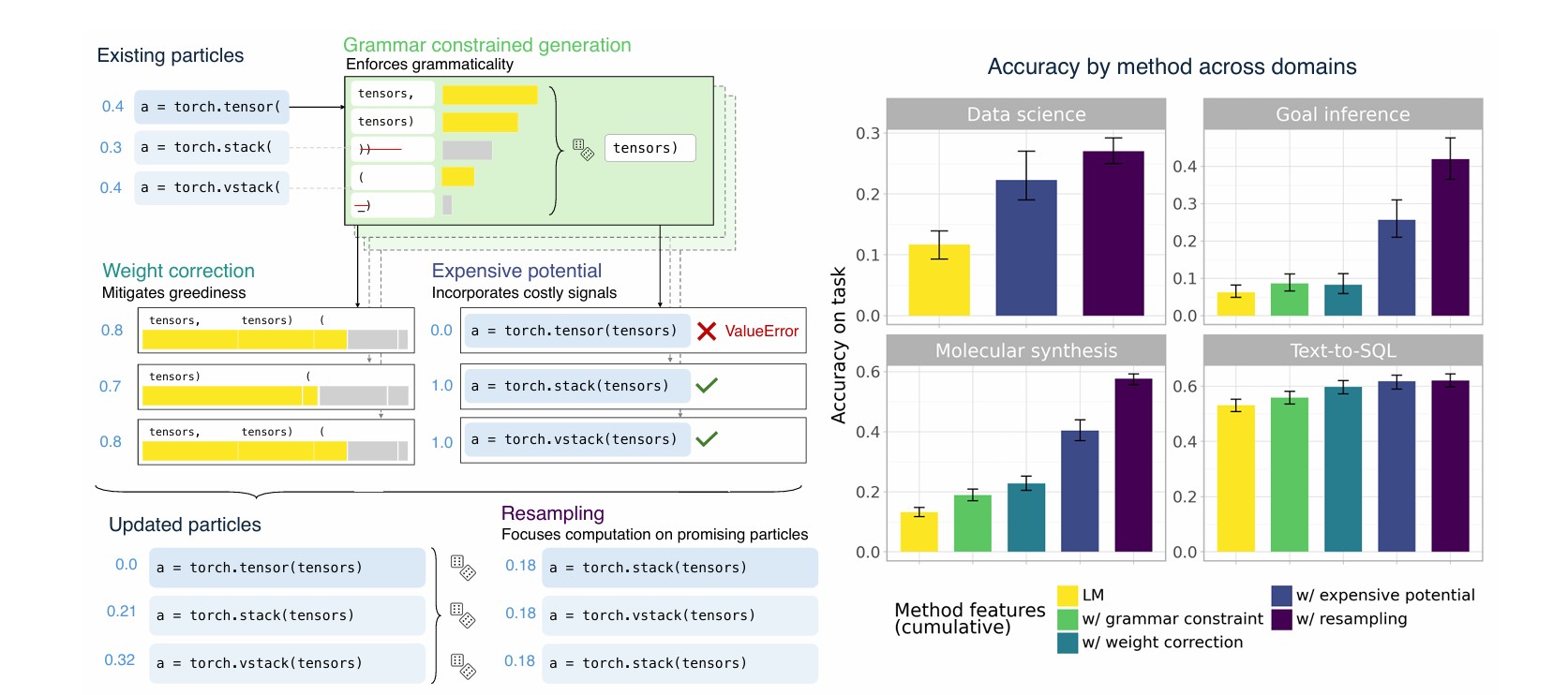
SMC의 3가지 핵심 기술이 성능 향상 견인: 가중치 보정, 비용 높은 잠재 함수, 적응형 리샘플링
연구팀이 개발한 SMC 프레임워크는 세 가지 핵심 알고리즘적 요소로 구성된다. 첫째, 가중치 보정(weight correction)은 지역적 제약 디코딩의 탐욕적 특성을 완화한다. 둘째, 비용 높은 잠재 함수(expensive potentials)는 로짓 마스크에 포함시키기 어려운 풍부한 정보를 인코딩한다. 셋째, 적응형 리샘플링(adaptive resampling)은 더 유망한 부분 시퀀스에 계산을 집중시킨다.
이 세 가지 요소가 모두 작동할 때 가장 좋은 성능을 보였다. 절대적 기여도 측면에서는 문맥에 따라 달랐는데, 비용 높은 잠재 함수가 목표 추론, 데이터 과학, 분자 합성 영역에서 가장 큰 성능 향상을 가져왔다. 논문의 실험 결과에 따르면, 이 세 영역에서 잠재 함수는 약 20%에서 40%의 성능 향상을 제공했다.
특히 연구팀이 사용한 확률적 관점의 타당성은 실험적으로도 확인되었다. KL 발산 추정을 통해 측정한 결과, 최고 성능을 보인 방법은 각 문제 인스턴스 내에서 글로벌 확률 분포에 더 가까운 출력을 생성했다. 또한, 목표 추론(0.793), 분자 합성(0.826), 데이터 과학(0.370), 텍스트-SQL(0.810) 영역에서 SMC 기법의 상대적 가중치와 정확도 점수 간 높은 상관관계를 보였다.
4가지 도전적 영역에서 검증된 SMC 기술, 분자 합성 분야에서 기존 방식 대비 1.5배 성능 향상
연구팀은 네 가지 도전적인 영역에서 실험을 진행했다. 데이터 과학을 위한 파이썬 코드 생성(DS-1000), 텍스트-SQL 변환(Spider), 목표 추론(Planetarium), 분자 합성(GDB-17) 분야에서 모두 SMC 방식이 다른 방법들보다 우수한 성능을 보였다.
가장 눈에 띄는 개선은 분자 합성 영역에서 나타났다. 기본 언어 모델(0.132)과 비교했을 때 전체 SMC 기법(0.577)은 약 4.4배, 문법 제약과 단순 잠재 함수(0.392)보다는 약 1.5배 높은 성능을 보였다. 목표 추론 영역에서도 기본 모델(0.063)과 비교해 SMC 기법(0.419)은 약 6.7배 높은 성능을 달성했다. 데이터 과학 영역에서는 기본 모델(0.213) 대비 SMC(0.407)가 약 1.9배 우수했다. 텍스트-SQL 변환에서는 기본 모델(0.531)보다 SMC(0.620)가 약 1.2배 높은 성능을 보였다.
특히 분자 합성 영역에서 SMC 기법은 다양성, 약물 유사성, 분자량 등 부가적인 품질 지표에서도 개선을 보였다. “도메인별 특성에 맞게 알고리즘을 세밀하게 조정할 수 있다는 점이 우리 프레임워크의 강점”이라고 연구팀은 강조했다. 이는 다양한 응용 분야에서 언어 모델의 활용도를 크게 높일 수 있는 가능성을 제시한다.
계산 오버헤드 미미한 SMC 기술, 토큰당 평균 처리 시간 30ms 이하로 실용적 활용 가능
SMC 프레임워크가 가져오는 성능 향상에는 물론 계산 비용이 따른다. 그러나 연구팀의 분석에 따르면, 이 오버헤드는 대부분의 응용 분야에서 수용 가능한 수준이다. SMC의 계산 오버헤드는 주로 두 가지 요소에서 발생한다. 리샘플링과 비용 높은 잠재 함수의 계산이다.
리샘플링의 비용은 무시할 수 있을 정도로 미미하며, 비용 높은 잠재 함수의 계산은 도메인에 따라 다르지만 대부분 토큰당 평균 30ms를 넘지 않는다. 목표 추론 영역에서는 토큰당 11ms, 분자 합성에서는 0.3ms, 데이터 과학에서는 7ms, 텍스트-SQL에서는 31ms의 추가 계산 시간이 소요된다.
추가적으로, 비용 높은 잠재 함수는 모든 토큰마다 계산할 필요 없이 의미론적으로 중요한 지점(SQL 절의 끝이나 파이썬 문장의 끝 등)에서만 실행되는 경우가 많아 평균 비용이 크게 줄어든다. 또한 대부분의 잠재 함수 계산은 GPU보다 비용이 저렴한 CPU에서 수행되어 비용 효율성이 더욱 높아진다.
FAQ
Q: 순차적 몬테카를로(SMC) 방식이 기존 언어 모델 제어 방식과 어떻게 다른가요?
A: 기존 방식은 주로 두 가지였습니다. 첫째, 토큰별 로짓 편향이나 마스킹을 사용하는 ‘지역적 제약 디코딩’은 모든 어휘에 대해 자주 평가해야 하며 분포를 왜곡할 수 있습니다. 둘째, 완전한 시퀀스를 생성한 후 재순위화하는 방식은 생성 과정에서 얻을 수 있는 점진적 정보를 활용하지 못합니다. SMC는 이 두 방식의 장점을 결합하여 생성 과정에서 점진적으로 정보를 활용하고 계산 자원을 더 유망한 후보로 재할당함으로써 더 정확한 결과를 얻습니다.
Q: 작은 모델이 더 큰 모델보다 좋은 성능을 보인다는 것이 실제로 가능한가요?
A: 네, 이 연구에서는 SMC 프레임워크를 적용했을 때 3개 도메인(데이터 과학, 분자 합성, 목표 추론)에서 상대적으로 작은 모델(Llama 3.1 8B)이 8배 이상 큰 모델보다 더 좋은 성능을 보였습니다. 데이터 과학 코드 생성에서는 SMC를 적용한 라마 3.1 70B가 175B 파라미터의 Codex-002보다 우수했습니다. 이는 단순히 모델 크기를 늘리는 것보다 효율적인 추론 알고리즘이 더 중요할 수 있음을 시사합니다. 특히 도메인 특화된 제약 조건과 알고리즘을 함께 사용할 때 이러한 효과가 두드러집니다.
Q: 이 기술이 일반 사용자들에게 어떤 영향을 미칠 수 있나요?
A: 이 기술은 코드 생성, 데이터베이스 쿼리 작성, 분자 설계와 같은 특수 도메인에서 AI 도구의 정확성과 성능을 크게 향상시킬 수 있습니다. 목표 추론에서 6.7배, 분자 합성에서 4.4배, 데이터 과학에서 1.9배의 성능 향상을 보인 만큼, 보다 정확하고 신뢰할 수 있는 AI 시스템을 만들 수 있습니다. 또한 계산 효율성이 높아 더 적은 자원으로 고품질 결과를 얻을 수 있어, 더 작고 효율적인 AI 모델의 개발로 이어질 수 있습니다. 이는 궁극적으로 더 저렴하고 접근성 높은 AI 서비스로 이어질 수 있습니다.
해당 기사에서 인용한 논문 원문은 링크에서 확인할 수 있다.
이미지 출처: 이디오그램 생성
기사는 클로드와 챗GPT를 활용해 작성되었습니다.





