PANGU ULTRA MOE: HOW TO TRAIN YOUR BIG MOE ON ASCEND NPUS
효율성 2배 향상, 화웨이의 7천억 파라미터 MoE 모델 어센드 NPU 최적화 도전기
희소 대규모 언어 모델(LLM)이 인공지능 분야에서 주목받고 있는 가운데, 화웨이에서 어센드(Ascend) NPU를 활용해 7천억 파라미터급 MoE(Mixture of Experts) 모델인 판구 울트라 MoE(Pangu Ultra MoE)의 효율적인 훈련 방법을 공개했다. 화웨이 판구팀은 발표한 기술 보고서에서 대규모 MoE 모델 학습 시 발생하는 컴퓨팅 자원 활용 문제와 동적 희소 모델 구조에서의 성능 최적화 방안을 제시했다.
MoE 모델은 구조적 특성상 이론적으로 연산량을 10배 이상 줄일 수 있지만, 실제로 파라미터의 활성화 비율이 입력 토큰과 파라미터 상태에 따라 동적으로 결정되기 때문에 이런 감소 효과를 실제 하드웨어에서 구현하기 어렵다는 과제가 있었다. 화웨이 연구팀은 이러한 문제를 해결하기 위해 모델 아키텍처 설계와 시스템 최적화 두 가지 측면에서 접근했다. 연구팀은 “어센드 NPU에 효율적으로 지원될 수 있는 적절한 모델 구성을 찾고, 프로세서 간 메모리 통신과 NPU 간 통신 오버헤드를 줄이는 것이 핵심 목표였다”고 밝혔다. 이들은 비용이 많이 드는 실험을 반복하지 않고도 어센드 NPU에 적합한 모델 구성을 선택하기 위해 시뮬레이션 방법을 활용했다.
256개 전문가 네트워크 채택, 시뮬레이션으로 최적 모델 설계 시간 단축
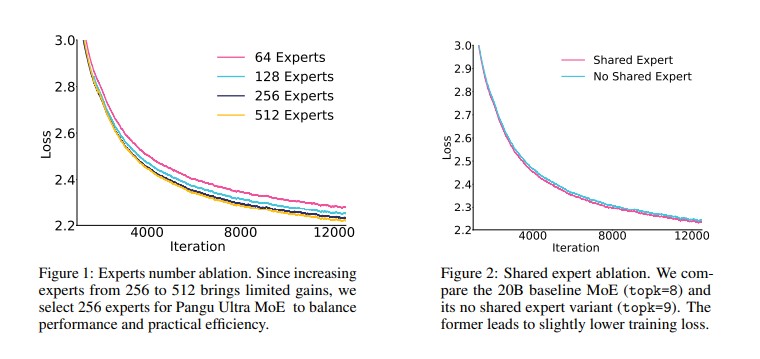
화웨이 연구팀은 대규모 MoE 모델의 설계를 위해 전문가 세분화(expert granularity)와 공유 전문가 수(shared experts)와 같은 MoE 블록 설계에 대한 파일럿 연구를 먼저 진행했다. 이어서 어센드 NPU에 최적화된 모델 구조를 찾기 위한 시뮬레이터를 개발했다. 연구팀은 전문가 수에 대한 실험에서 토큰당 활성화되는 파라미터 수를 일정하게 유지하면서 전문가 수를 64개에서 512개까지 증가시켜 테스트했다. 그 결과 256개의 전문가를 사용했을 때 64개나 128개보다 훨씬 낮은 학습 손실을 달성했으며, 512개로 늘렸을 때는 256개에 비해 미미한 성능 향상만 있었다.
또한 공유 전문가 아키텍처에 대한 실험을 통해 공유 전문가를 사용하는 모델이 그렇지 않은 모델보다 더 낮은 학습 손실을 달성한다는 것을 확인했다. 이러한 결과를 바탕으로 공유 전문가 아키텍처를 최종 모델에 채택했다. 화웨이 연구팀은 어센드 910B 플랫폼에서 모델 성능을 정확하게 시뮬레이션하기 위해 계산 능력, 대역폭, 지연 시간, 효율성 등의 파라미터를 고려한 네트워크의 모든 계산, 통신, 메모리 접근을 모델링했다. 이렇게 형성된 시뮬레이션 방법은 최종적으로 총 718억 파라미터를 가진 판구 울트라 MoE를 설계하는 데 사용되었다.
계층적 통신 구조로 병목 해소, 6천대 NPU 클러스터에서 통신 오버헤드 95% 제거
화웨이 연구팀은 대규모 MoE 모델 훈련 시 장치 통신 오버헤드, 높은 메모리 사용률, 불균형한 전문가 부하 등 세 가지 주요 병목 현상을 확인했다. 전통적인 전문가 병렬화에서의 All-to-All 통신은 노드 내부와 노드 간 트래픽을 구분하지 않아 대역폭 활용이 비효율적이고 통신 오버헤드가 증가하는 문제가 있었다. 이러한 문제를 해결하기 위해 연구팀은 계층적 EP(Expert Parallelism) All-to-All 통신을 도입했다. 이는 노드 간 Allgather와 노드 내 All-to-All 통신을 분리하여 대역폭 활용을 최적화하는 방식이다. 이 두 통신은 연구팀이 제안한 적응형 파이프 오버랩(Adaptive Pipe Overlap) 메커니즘을 통해 계산과 효과적으로 중첩된다.
또한 제한된 NPU 메모리 내에서 안정성을 보장하기 위해 연구팀은 세밀한 재계산(Fine-Grained Recomputation)과 텐서 스와핑(Tensor Swapping) 두 가지 기술을 통해 메모리 활용 효율성을 개선했다. 세밀한 재계산은 모든 활성화를 저장하거나 전체 레이어를 재계산하는 대신 특정 연산자의 중간 활성화를 선택적으로 재계산하는 방식이다. 텐서 스와핑은 활성화를 일시적으로 호스트로 오프로드하고 역전파 계산을 위해 미리 가져오는 방식으로, NPU에 저장하지 않고도 필요할 때 활용할 수 있게 한다. 전문가 로드 불균형 문제를 완화하기 위해 연구팀은 실시간 로드 전문가 예측과 NPU 간 적응형 전문가 배치를 활용한 동적 장치 수준 로드 밸런싱 접근 방식을 제안했다.
30% MFU 달성, 초당 146만 토큰 처리… 기존 대비 2.4배 성능 향상
화웨이 연구팀은 모델 선택 전략과 병렬 컴퓨팅 시스템 최적화를 통해 판구 울트라 MoE 훈련 시 딥시크 R1(DeepSeek R1)과 유사한 성능으로 6천대 어센드 NPU에서 30.0%의 모델 플롭스 활용률(MFU)과 초당 146만 토큰(TPS)을 달성했다. 이는 기준선인 4천대 어센드 NPU에서의 18.9% MFU와 초당 61만 토큰에 비해 크게 향상된 수치다. 특히 판구 울트라 MoE는 의료 벤치마크에서 뛰어난 성능을 보였으며, 연구팀은 MoE 구조를 포함한 모델 행동에 대한 연구를 통해 어센드 NPU에서 대규모 MoE 모델 훈련을 위한 추가 지침을 제공했다.
화웨이 연구팀이 구현한 다양한 최적화 전략은 시스템 활용도를 크게 향상시켰다. 세밀한 재계산과 스와핑을 통해 15.8%, 적응형 파이프 오버랩을 통해 28.6%, 호스트 최적화를 통해 49.2%, 융합 연산자를 통해 58.7%의 MFU 향상을 이루어냈다. 이 연구는 단순히 판구 울트라 MoE 모델을 소개하는 것을 넘어, 대규모 MoE 모델을 효율적으로 훈련할 수 있는 체계적인 방법론과 어센드 NPU에 최적화된 시스템 설계를 제공한다는 점에서 중요한 의미를 가진다.
FAQ
Q. MoE(Mixture of Experts) 모델이란 무엇인가요?
A: MoE 모델은 여러 개의 전문가 네트워크로 구성된 인공지능 구조로, 입력 데이터에 따라 특정 전문가만 선택적으로 활성화되는 희소 신경망 모델입니다. 일반적인 대규모 언어 모델보다 적은 계산량으로 더 많은 파라미터를 처리할 수 있어 효율적인 학습과 추론이 가능합니다.
Q. 화웨이의 판구 울트라 MoE가 다른 MoE 모델과 다른 점은 무엇인가요?
A: 판구 울트라 MoE는 아센드 NPU에 최적화된 718억 파라미터 규모의 MoE 모델로, 시뮬레이션 기반 설계와 다양한 시스템 최적화 기술을 적용했습니다. 특히 계층적 통신 방식, 메모리 최적화, 동적 로드 밸런싱 등을 통해 6천대 NPU에서 30%의 높은 모델 플롭스 활용률(MFU)을 달성했습니다.
Q. 이번 연구가 AI 산업에 미치는 영향은 무엇인가요?
A: 이 연구는 대규모 MoE 모델을 효율적으로 훈련하는 방법론을 제시함으로써, 계산 자원 한계로 인해 제약받던 AI 모델 개발에 새로운 가능성을 열었습니다. 또한 아센드 NPU와 같은 특정 하드웨어에 최적화된 AI 모델 설계 방법을 제시하여, 하드웨어-소프트웨어 공동 최적화의 중요성을 강조했습니다.
해당 기사에서 인용한 논문 원문은 링크에서 확인할 수 있다.
이미지 출처: PANGU ULTRA MOE: HOW TO TRAIN YOUR BIG MOE ON ASCEND NPUS
기사는 클로드와 챗GPT를 활용해 작성되었습니다.