
Don’t Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning
기존 통념을 뒤집는 발견: 짧은 추론이 34.5% 더 정확
복잡한 수학 문제를 해결하는 대형언어모델(LLM)에서 긴 추론 과정이 반드시 더 나은 성능을 보장하지 않는다는 연구 결과가 발표됐다. 메타(Meta)와 히브리대학교 공동 연구진이 발표한 논문에 따르면, 오히려 짧은 추론 과정이 최대 34.5% 더 정확한 결과를 도출하는 것으로 나타났다. 연구진은 3개의 주요 추론 LLM인 라마-3.3-네모트론-슈퍼-49B(Llama-3.3-Nemotron-Super-49B), R1-디스틸-콰인-32B(R1-Distill-Qwen-32B), QwQ-32B를 대상으로 실험을 진행했다. 각 모델에 동일한 수학 문제를 20회씩 풀게 한 뒤, 가장 짧은 답안과 가장 긴 답안의 정확도를 비교 분석했다.
실험 결과는 놀라웠다. 가장 짧은 추론 과정을 거친 답안이 무작위로 선택한 답안보다 최대 18.8% 더 높은 정확도를 보였으며, 가장 긴 추론 과정을 거친 답안보다는 무려 34.5% 더 정확했다. 특히 짧은 추론 과정은 무작위 선택 대비 50%, 긴 추론 대비 67% 더 적은 토큰을 사용하면서도 이런 성과를 달성했다.
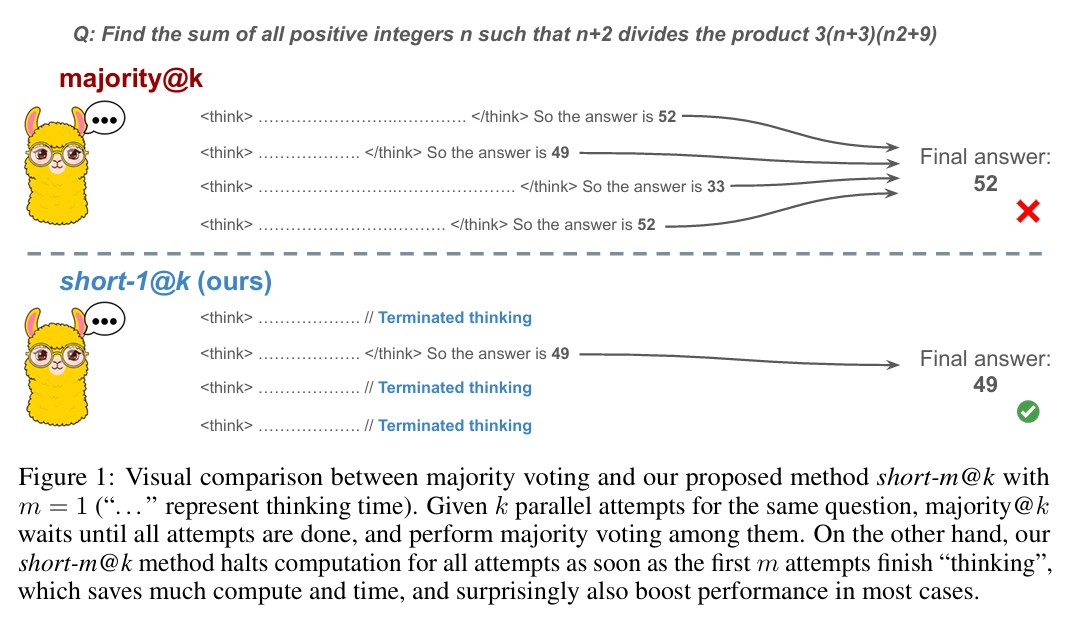
short-m@k 방법론: 병렬 처리로 효율성과 정확성 동시 확보
이러한 발견을 바탕으로 연구진은 ‘short-m@k’라는 새로운 추론 방법을 제안했다. 이 방법은 k개의 독립적인 생성 과정을 병렬로 실행하다가, 첫 번째 m개의 추론 과정이 완료되는 즉시 모든 계산을 중단하는 방식이다. 최종 답안은 이 m개의 짧은 추론 과정에서 다수결 투표로 결정된다.
실험에서 short-1@k 방법은 저연산 환경에서 기존의 다수결 투표 방식과 비슷하거나 더 우수한 성능을 보이면서도 추론 토큰을 최대 40% 절약했다. short-3@k 방법은 모든 연산 예산에서 일관되게 다수결 투표를 능가했으며, 처리 시간을 최대 33% 단축시켰다.
실험 데이터: AIME와 HMMT 벤치마크에서 일관된 결과
연구진은 AIME 2024, AIME 2025, HMMT 2025년 2월 등 3개의 경쟁적인 수학 벤치마크를 사용해 실험을 진행했다. 각 벤치마크는 30개의 다양한 난이도 문제로 구성됐으며, 총 5,400개의 답안을 생성해 분석했다. 흥미롭게도 어려운 문제일수록 더 많은 토큰을 사용하는 경향을 보였지만, 동일한 문제 내에서는 정답이 오답보다 더 짧은 추론 과정을 거치는 것으로 나타났다. 예를 들어, LN-Super-49B 모델의 경우 쉬운 문제에서 정답은 평균 5,300개 토큰을 사용한 반면 오답은 11,100개 토큰을 사용했다.
짧은 추론 데이터로 훈련하면 성능도 향상
연구진은 추가로 콰인-2.5-32B(Qwen-2.5-32B) 모델을 짧은 추론, 긴 추론, 무작위 추론 데이터로 각각 파인튜닝했다. 그 결과 짧은 추론 데이터로 훈련한 모델이 다른 두 모델보다 더 나은 성능을 보였다. S1-short 모델은 S1-random 모델 대비 2.8% 높은 정확도를 달성하면서도 추론 토큰을 5.8% 적게 사용했다. 반면 긴 추론 데이터로 훈련한 S1-long 모델은 더 많은 토큰을 소모했지만 성능 향상은 미미했다. 이는 훈련 단계에서부터 짧은 추론을 활용하는 것이 효율성과 정확성을 동시에 개선할 수 있음을 시사한다.
병렬 처리 의존성과 메모리 제약이라는 한계점
이번 연구의 short-m@k 방법론은 뛰어난 성과를 보였지만 몇 가지 제약사항도 존재한다. 가장 큰 한계는 배치 디코딩(batch decoding)에 의존한다는 점이다. 이 방법은 여러 추론 과정을 동시에 병렬로 실행해야 하므로, 추론 메모리가 제한된 환경에서는 적용이 어려울 수 있다.
연구진은 병렬 처리 없이도 short-m@k를 사용할 수 있지만, 이 경우 효율성 개선 효과가 줄어든다고 밝혔다. 또한 이번 파인튜닝 실험은 특정 모델(콰인-2.5-32B-인스트럭트)과 데이터셋(S1)에 한정되어 진행됐기 때문에, 다른 모델과 데이터셋에서도 동일한 효과를 보일지는 추가 검증이 필요하다.
FAQ
Q: 왜 짧은 추론이 더 정확한 결과를 낳나요?
A: 연구진은 긴 추론 과정이 오히려 모델을 혼란스럽게 만들고 잘못된 경로로 이끌 수 있다고 분석했습니다. 짧은 추론은 핵심적인 문제 해결 과정에 집중하여 더 직접적이고 정확한 답안을 도출합니다.
Q: short-m@k 방법은 어떤 상황에서 가장 효과적인가요?
A: 이 방법은 특히 연산 자원이 제한된 환경에서 뛰어난 효과를 보입니다. 병렬 처리가 가능한 환경에서 사용할 때 최대 40%의 연산 비용을 절약하면서도 더 높은 정확도를 달성할 수 있습니다.
Q: 이 연구 결과가 실제 AI 서비스에 어떤 영향을 미칠까요?
A: 이 연구는 AI 서비스의 연산 비용을 크게 줄이면서도 성능을 향상시킬 수 있는 방법을 제시합니다. 특히 수학 문제 해결, 코딩, 논리적 추론이 필요한 AI 애플리케이션에서 효율성과 정확성을 동시에 개선할 수 있을 것으로 기대됩니다.
해당 기사에서 인용한 논문 원문은 링크에서 확인할 수 있다.
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성했습니다.





