
QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
기존 AI 모델들이 긴 문서에서 겪던 학습 효율성 저하와 불안정성 문제
알리바바 통이랩(Tongyi Lab)이 강화학습을 통해 장문 맥락에서의 추론 능력을 크게 향상시킨 대형 추론 모델 ‘큐원롱-L1(QwenLong-L1)’을 발표했다. 이 모델은 기존의 단문 맥락 추론에 최적화된 모델들과 달리, 12만 토큰 규모의 긴 문서에서도 안정적인 추론 성능을 보여준다.
큐원롱-L1은 기존 대형 추론 모델(LRM)들이 갖고 있던 근본적인 한계를 해결했다. 기존 모델들은 주로 4천 토큰 내외의 짧은 텍스트에서는 뛰어난 성능을 보였지만, 긴 문서를 처리할 때는 학습 효율성 저하와 최적화 과정의 불안정성이라는 문제에 직면했다. 연구팀은 이러한 문제를 체계적으로 분석하고 해결책을 제시했다.
2만→6만 토큰 단계적 확장과 난이도별 샘플링으로 안정성 확보
큐원롱-L1의 핵심 혁신은 점진적 맥락 확장(Progressive Context Scaling) 전략이다. 이 방법은 짧은 맥락에서 시작해 단계적으로 긴 맥락으로 확장하는 커리큘럼 기반 학습을 적용한다. 구체적으로 1단계에서는 2만 토큰, 2단계에서는 6만 토큰으로 점진적으로 입력 길이를 늘려가며 모델을 훈련시킨다.
또한 난이도 인식 회고적 샘플링(Difficulty-Aware Retrospective Sampling) 기법을 도입해 이전 단계의 어려운 문제들을 다음 단계 훈련에 포함시켜 모델의 탐색 능력을 향상시켰다. 이는 평균 보상이 낮은 문제들을 우선적으로 선별해 다시 학습에 활용하는 방식으로 구현된다.
규칙 기반 검증+AI 판정자 결합으로 정확성과 유연성 동시 달성
기존의 수학이나 코딩 문제에서 사용되던 규칙 기반 보상 시스템은 정확한 답 매칭에만 의존해 다양한 답변 형태를 인정하지 못하는 한계가 있었다. 큐원롱-L1은 이를 해결하기 위해 규칙 기반 검증과 LLM 판정자(LLM-as-a-Judge)를 결합한 하이브리드 보상 메커니즘을 개발했다.
규칙 기반 검증은 정확한 문자열 매칭을 통해 정밀도를 보장하고, LLM 판정자는 의미적 동등성을 평가해 다양한 표현 방식의 정답을 인정한다. 최종 보상은 두 방식 중 높은 점수를 선택하는 방식으로 결정되어, 정확성과 유연성을 모두 확보했다.
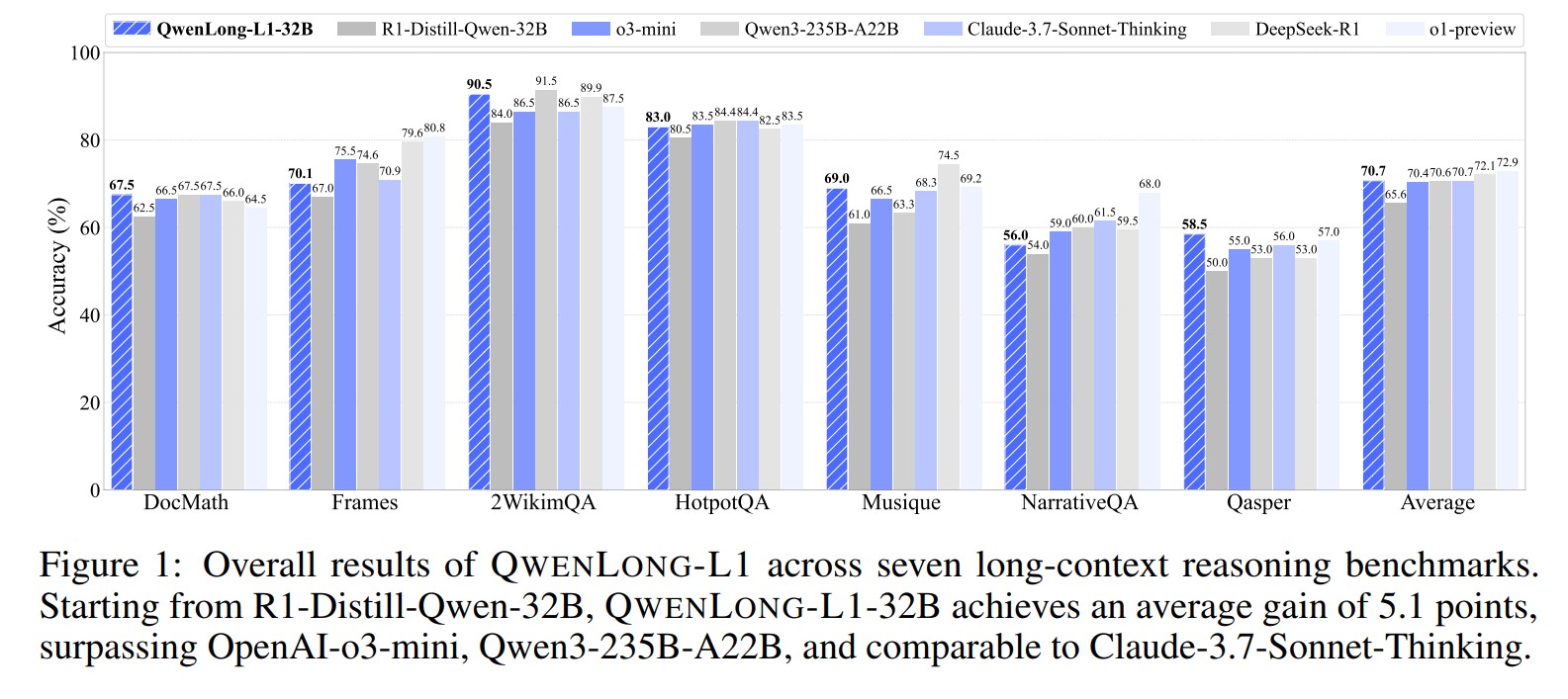
7개 벤치마크 평균 70.7점 달성… 오픈AI o3-mini(70.4점) 앞서
연구팀은 문서 질의응답을 중심으로 한 7개의 장문 맥락 추론 벤치마크에서 큐원롱-L1의 성능을 평가했다. 그 결과 큐원롱-L1-32B 모델은 평균 70.7점을 기록해 오픈AI의 o3-mini(70.4점), 큐원3-235B-A22B(70.6점)를 뛰어넘었으며, 클로드-3.7-소네트-씽킹(70.7점)과 동등한 성능을 보였다. 특히 DocMath에서 67.5점, 2WikimQA에서 90.5점, HotpotQA에서 83.0점을 기록하며 수학적 추론과 다중 홉 추론 모두에서 우수한 성능을 입증했다. 또한 Pass@K 평가에서도 적은 샘플 수로도 높은 성능을 달성해 테스트 시점 확장성도 확인했다.
RL 훈련으로 4가지 핵심 추론 행동 패턴 강화…그라운딩 행동 9.17회로 최다
큐원롱-L1의 가장 흥미로운 발견 중 하나는 강화학습 훈련 과정에서 AI 모델의 ‘생각하는 방식’이 어떻게 진화하는지를 관찰한 것이다. 연구팀은 4가지 핵심 추론 행동 패턴을 추적했다. 장문 맥락에서 가장 중요한 ‘그라운딩(Grounding)’ 행동은 모델이 긴 문서에서 관련 정보를 찾아 인용하는 능력으로, 훈련 후 평균 9.17회로 가장 높은 빈도를 보였다. 이는 “제공된 텍스트에서 관련 정보를 찾아보겠습니다”와 같은 표현으로 나타난다.
‘백트래킹(Backtracking)’ 행동은 모델이 자신의 오류를 인식하고 접근 방식을 수정하는 능력으로 3.33회, ‘검증(Verification)’ 행동은 예측한 답변의 정확성을 체계적으로 확인하는 과정으로 2.90회 관찰됐다. ‘서브골 설정(Subgoal Setting)’은 복잡한 문제를 관리 가능한 하위 목표로 분해하는 능력으로 4.79회 나타났다. 흥미롭게도 지도학습(SFT) 모델도 이러한 추론 행동들을 보였지만, 실제 성능 향상으로는 이어지지 않았다. 연구팀은 이를 “SFT는 표면적인 패턴 모방에 그치지만, RL은 실질적인 추론 능력 개발로 이어진다”고 분석했다.
FAQ
Q: 큐원롱-L1이 기존 AI 모델과 다른 점은 무엇인가요?
A: 큐원롱-L1은 12만 토큰 규모의 긴 문서에서도 안정적인 추론이 가능한 최초의 장문 맥락 전용 강화학습 모델입니다. 기존 모델들이 짧은 텍스트에만 특화되어 있던 것과 달리, 점진적 맥락 확장 방식을 통해 긴 문서 처리 능력을 확보했습니다.
Q: 하이브리드 보상 시스템이 왜 중요한가요?
A: 기존의 규칙 기반 시스템은 정확한 문자 일치만 인정해 다양한 정답 표현을 놓칠 수 있습니다. 하이브리드 시스템은 정확한 매칭과 의미 기반 평가를 결합해 정확성은 유지하면서도 답변의 다양성을 인정합니다.
Q: 이 기술이 실제로 어떤 분야에 활용될 수 있나요?
A: 긴 문서 분석이 필요한 법률, 금융, 학술 연구 분야에서 활용 가능합니다. 특히 복잡한 계약서 분석, 재무제표 해석, 연구논문 요약 등 정보 집약적 환경에서의 의사결정 지원에 유용합니다.
해당 기사에 인용한 논문 원문은 링크에서 확인 가능하다.
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성했습니다.





