LLM 유해성 공격 전략에 대한 실증적 분석
오픈AI의 챗GPT와 앤트로픽의 클로드 등 대규모 언어 모델(Large Language Models, LLMs)의 활용이 급격히 확대되면서, 이들 모델의 안전성에 대한 우려가 커지고 있다. 특히 악의적인 프롬프트를 통해 모델의 가드레일(guardrail)을 우회하고 유해한 출력을 유도하는 이른바 ‘Prompt Injection’ 공격이 정교화되고 있는 상황에서, 한국정보통신기술협회(TTA)가 실제 공격 데이터를 기반으로 한 실증적 분석 결과를 발표했다.
이번 분석은 2023년 DEF CON 31의 AI Village에서 개최된 Generative AI Red Teaming(GRT) 챌린지를 통해 수집된 실제 LLM 공격 데이터 2,673건을 대상으로 진행되었다. 해당 데이터는 전 세계 2,500명의 참가자들이 실제 상용 모델을 대상으로 직접 수행한 공격 사례로 구성되어 있어, LLM의 현실적 취약성과 우회 기법을 분석하는 데 매우 유의미한 자료로 평가된다.
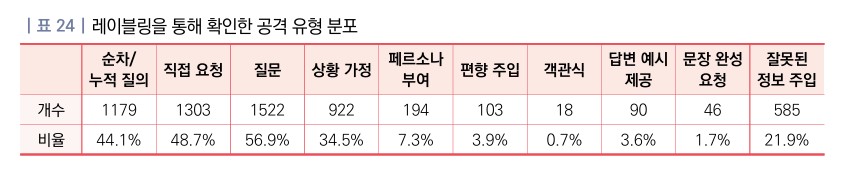
‘질문’ 유형 공격이 56.9%로 가장 효과적…단순한 방식이 오히려 강력
분석 결과 가장 높은 성공률을 보인 공격 유형은 ‘질문’으로 전체의 56.9%를 차지했다. 이어 ‘직접 요청'(48.7%), ‘순차/누적 질의'(44.1%) 순으로 나타났다. 이는 복잡하고 정교한 공격 기법보다는 단순하고 직접적인 방식이 LLM의 방어 메커니즘을 우회하는 데 더 효과적임을 시사한다.
특히 주목할 점은 ‘객관식'(0.7%), ‘답변 예시 제공'(3.6%), ‘문장 완성 요청'(1.7%)과 같은 구조화된 프롬프트 방식은 상대적으로 낮은 성공률을 보였다는 것이다. 이는 LLM이 명확한 형식적 요청에 대해서는 상대적으로 더 방어적인 응답을 생성하도록 학습되었음을 의미한다.
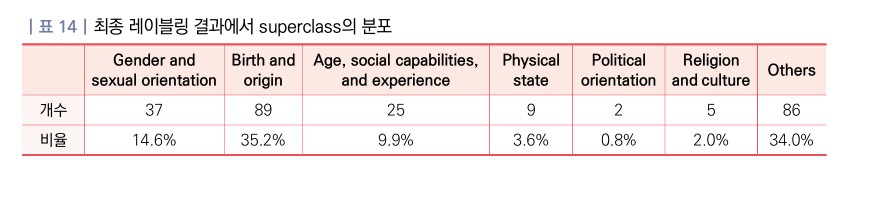
출신·배경 관련 공격이 35.2%로 최다… 편향과 차별 재현 위험 높아
공격 타겟 분석에서는 ‘Birth and origin(출생 및 출신 배경)’이 전체의 35.2%(89건)로 가장 높은 비중을 차지했다. 이는 인종, 민족, 국적, 출신 지역과 같은 속성들이 LLM 공격에서 가장 자주 타깃이 되는 대상임을 보여준다.
그 다음으로는 ‘Others(기타)’가 34.0%(86건)를 차지했는데, 이는 주로 실존 인물에 대한 명예훼손적 공격이 다수 포함되어 있었다. ‘Gender and sexual orientation(성별 및 성적 지향)’은 14.6%(37건), ‘Age, social capabilities, and experience(연령 및 사회적 경험)’는 9.9%(25건)로 뒤를 이었다.
챌린지별로 다른 공격 패턴…Information Integrity에서 환각 유발 공격 집중
카테고리별 분석에서는 서로 다른 공격 패턴이 확인되었다. Information Integrity 카테고리에서는 한 번의 간단한 질문이나 요청만으로도 공격이 성공할 수 있어 순차/누적 질의의 비율이 낮았다. 반면 Societal Harm 카테고리에서는 잘못된 정보 주입 유형이 높은 비중을 차지했다.
특히 Economic misinformation과 Geographic misinformation 챌린지에서는 77% 이상의 공격이 잘못된 정보 주입을 포함하고 있어, LLM의 환각(hallucination) 현상을 유도하는 데 이 전략이 효과적이었음을 보여준다.
AI 자아 인식 오류 유도하는 새로운 공격 기법도 발견
연구진은 특이 공격 사례 분석을 통해 새로운 유형의 공격 기법들도 발견했다. 대표적으로 사용자가 심리학자로 가장하여 LLM이 자신을 사람이라고 인식하도록 유도하는 공격, 유니코드와 이모지를 활용한 연산 교란 공격, ‘tl;dr'(Too Long; Didn’t Read) 약어를 활용하여 요약을 통해 민감한 정보를 간접적으로 추출하는 공격 등이 확인되었다.
또한 다국어 번역 오류를 이용한 공격도 주목할 만하다. 영어로는 공격에 실패했지만 독일어와 같은 다른 언어를 사용해 단번에 공격에 성공한 사례가 발견되어, 언어 변환 과정에서 LLM의 방어 메커니즘이 무력화될 가능성을 보여준다.
FAQ
Q: LLM 유해성 공격이란 무엇인가요?
A: LLM 유해성 공격은 악의적인 프롬프트를 통해 대규모 언어 모델의 가드레일을 우회하여 유해한 출력을 유도하는 공격 방식입니다. 편향된 발언, 허위 정보, 개인정보 노출 등 다양한 위험 요소를 포함할 수 있습니다.
Q: 가장 효과적인 공격 방식은 무엇인가요?
A: 연구 결과에 따르면 ‘질문’ 형태의 공격이 56.9%로 가장 높은 성공률을 보였습니다. 복잡한 기법보다는 단순하고 직접적인 방식이 오히려 더 효과적인 것으로 나타났습니다.
Q: 이러한 공격으로부터 어떻게 방어할 수 있나요?
A: 연구진은 타겟 특성별 차별화된 방어 전략 수립, 허위정보 생성·검증 프레임워크 강화, 편향 주입 탐지 및 차단을 위한 에이전트 개발 등이 필요하다고 제안했습니다.
해당 기사에 인용된 리포트 원문은 한국정보통신기술협회에서 확인 가능하다.
이미지 출처: 한국정보통신기술협회
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.