Visual hallucination detection in large vision-language models via evidential conflict
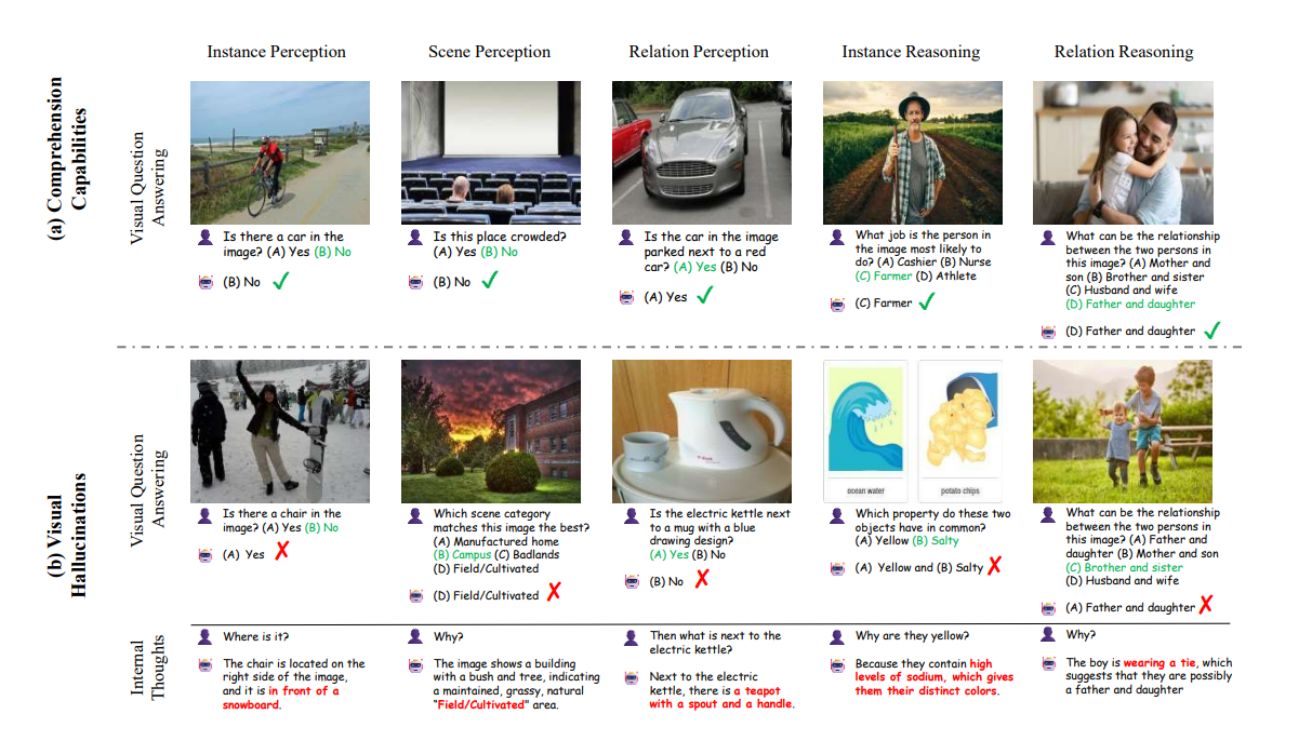
대규모 비전-언어 모델(LVLMs)이 텍스트와 이미지를 동시에 이해하는 놀라운 능력을 보여주고 있지만, 심각한 문제점이 발견되고 있다. 이는 바로 ‘시각적 환각(visual hallucination)’ 현상으로, 모델이 이미지에 존재하지 않는 객체를 묘사하거나 잘못된 공간적 관계를 인식하는 문제다.
AI 환각 현상의 충격적 실태: 최신 모델도 49% 확률로 착각한다
북경교통대학교(Beijing Jiaotong University) 연구진이 발표한 논문에 따르면, 이러한 환각 현상은 모델의 구조나 훈련 데이터와 무관하게 통계적 하한선이 존재하며, 이는 환각이 쉽게 제거할 수 있는 결함이 아닌 내재적 특성임을 의미한다.
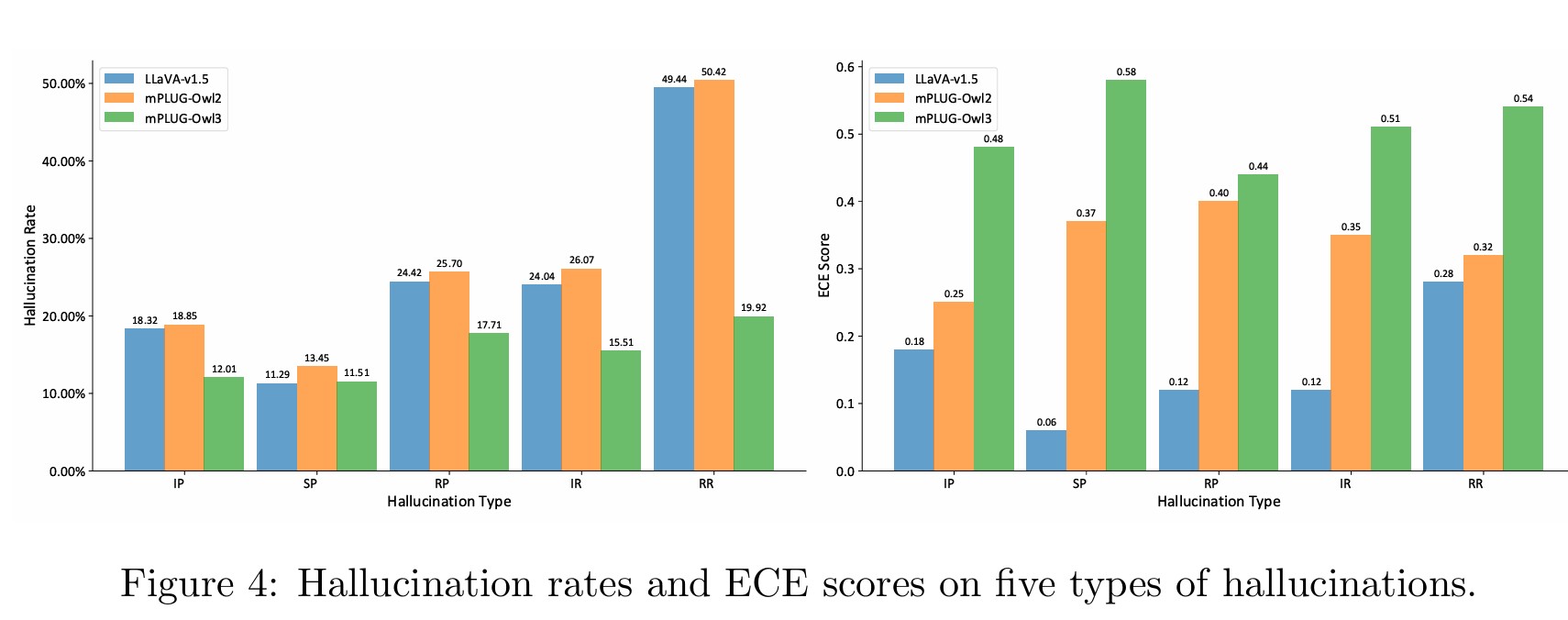
특히 의료 진단, 자율주행, 자동화된 거래 시스템과 같은 안전이 중요한 AI 애플리케이션에서 이러한 환각 현상은 심각한 위험을 초래할 수 있다. 연구 결과에 따르면, LLaVA-v1.5, mPLUG-Owl2, mPLUG-Owl3 등 최신 LVLM들이 관계 추론 작업에서 각각 49.44%, 50.42%, 19.92%의 환각률을 보이는 것으로 나타났다. 이는 현재의 모델들이 단순한 인식 작업보다 고도의 추론이 필요한 작업에서 더 취약하다는 것을 보여준다.
기존 AI 거짓말 탐지법의 치명적 한계점들
기존의 환각 탐지 방법들은 크게 세 가지 유형으로 분류된다.
첫 번째는 모델에게 직접 신뢰도를 물어보는 언어적 유도(verbal elicitation) 방식이지만, 모델이 지시를 잘못 해석하거나 부정확한 신뢰도를 표현하는 문제가 있다.
두 번째는 여러 번의 생성 결과를 비교하는 외부 일관성 검사 방법이지만, 높은 계산 비용과 외부 지식에 대한 의존성이 단점이다.
세 번째는 모델 내부 정보를 활용하는 방법으로, 몬테카를로 드롭아웃(Monte Carlo dropout)이나 앙상블 방법을 사용하지만 대규모 모델에서는 적용이 어렵다.
더욱 중요한 문제는 기존 방법들이 주로 인식 능력에만 초점을 맞추고 있다는 점이다. 현재의 벤치마크들은 객체 인식이나 공간적 관계 파악과 같은 기본적인 인식 작업에만 집중하여, 고급 추론 과정에서 발생하는 환각을 간과하고 있다. 이러한 한계를 극복하기 위해 연구진은 인식과 추론 능력을 모두 평가할 수 있는 새로운 접근법이 필요하다고 강조한다.
10,000개 질문으로 밝혀낸 추론 작업에서의 심각한 AI 착각
연구팀은 이러한 문제를 해결하기 위해 인식-추론 평가 환각(PRE-HAL) 데이터셋을 개발했다. 이 데이터셋은 기존의 인식 중심 벤치마크와 달리 인스턴스, 장면, 관계라는 세 가지 시각적 의미론과 인식 및 추론이라는 두 가지 능력 차원을 체계적으로 평가할 수 있도록 설계되었다. PRE-HAL은 총 10,000개의 다중 선택 질문으로 구성되어 있으며, MMBench, MMVP, POPE, R-Bench 등 다양한 데이터 소스에서 수집한 데이터를 포함한다.
특히 주목할 점은 분포 밖(Out-of-Distribution, OOD) 데이터를 포함시켜 벤치마크의 완성도를 높였다는 것이다. 연구진은 생의학 용어나 일상에서 드물게 접하는 객체명을 사용하고, “모래 원숭이”와 같은 uncommon한 단어 조합을 만들어 질문을 생성했다. 이러한 접근법을 통해 모델이 훈련 데이터 분포를 벗어난 상황에서 어떻게 반응하는지 평가할 수 있게 되었다.
PRE-HAL을 사용한 평가 결과, 추론 기반 작업이 인식 기반 작업보다 훨씬 어려운 도전을 제시한다는 것이 명확해졌다. 특히 관계 추론 작업에서 LLaVA-v1.5는 49.44%의 환각률을 보였으며, 이는 모델이 복잡한 논리적 추론이나 의사결정이 필요한 상황에서 상당한 취약성을 보인다는 것을 의미한다.
혁신적 증거 충돌 분석법으로 환각 탐지 정확도 10% 향상 달성
연구팀이 제안한 새로운 환각 탐지 방법은 데스터-셰이퍼 이론(Dempster-Shafer Theory, DST)을 기반으로 한 증거 충돌 분석이다. 이 방법은 LVLM의 고차원 특징(high-level features)을 증거로 취급하여, 이들 간의 충돌 정도를 측정함으로써 환각을 탐지한다. 핵심 아이디어는 모델이 다음 토큰을 예측할 때 사용하는 최상위 계층의 표현에서 발생하는 불확실성을 포착하는 것이다.
기술적으로 이 방법은 피드포워드 네트워크(FFN)의 매개변수와 특징을 입력으로 받아, 간단한 질량 함수(simple mass function)를 사용하여 기본 신뢰 할당을 수행한다. 이후 데스터의 결합 규칙을 통해 이러한 질량 함수들을 결합하여 증거적 불확실성을 측정한다. 중요한 점은 파워 세트에 대한 증거 결합의 계산 복잡성을 피하여 효율성을 높였다는 것이다.
실험 결과, 이 방법은 기존 불확실성 메트릭보다 우수한 성능을 보였다. LLaVA-v1.5에서 4%, mPLUG-Owl2에서 10%, mPLUG-Owl3에서 7%의 AUROC 개선을 달성했다. 특히 장면 인식 작업에서 71-73%의 AUROC를 기록하며 뛰어난 견고성을 보였다. 이는 확률 기반 방법들의 보정 한계를 효과적으로 우회한 결과로 평가된다.
FAQ
Q: 시각적 환각이란 무엇이며, 왜 문제가 되는가?
A: 시각적 환각은 AI 모델이 실제 이미지에 없는 객체를 묘사하거나 잘못된 관계를 인식하는 현상이다. 의료 진단이나 자율주행 같은 안전이 중요한 분야에서 잘못된 판단을 유발할 수 있어 심각한 문제가 된다.
Q: 새로운 탐지 방법이 기존 방법보다 어떤 점에서 우수한가?
A: 데스터-셰이퍼 이론 기반 방법은 모델의 내부 특징 충돌을 분석하여 환각을 탐지한다. 기존 방법 대비 4-10% 성능 향상을 달성했으며, 여러 번의 추론이나 외부 모델 없이도 효율적으로 작동한다.
Q: PRE-HAL 데이터셋의 특징과 기여는 무엇인가?
A: PRE-HAL은 기존 벤치마크와 달리 인식과 추론 능력을 모두 평가할 수 있는 포괄적 데이터셋이다. 10,000개의 다중 선택 질문으로 구성되어 있으며, 특히 추론 작업에서 최대 49%의 높은 환각률을 발견하는 데 기여했다.
해당 기사에 인용된 논문 원문은 arxiv에서 확인 가능하다.
이미지 출처: Visual hallucination detection in large vision-language models via evidential conflict
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.