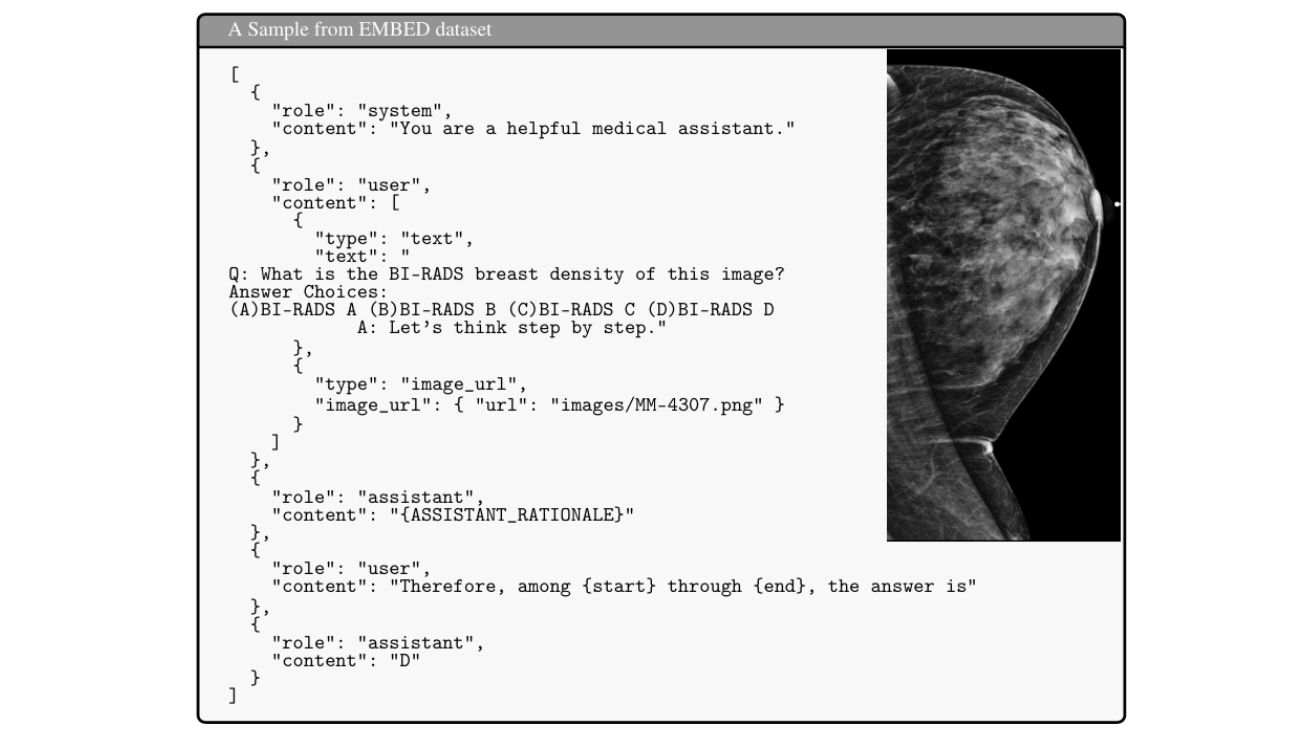
최신 AI 챗봇인 ChatGPT-5가 유방암 검사 사진을 분석하는 능력을 테스트한 결과, 이전 버전보다는 나아졌지만 여전히 의사를 대신하기에는 실력이 부족하다는 연구 결과가 나왔다. 미국 에모리대학교 의과대학 연구팀이 진행한 이 연구는 GPT-5가 의료 영상 전용 훈련 없이도 유방암 검사 이미지를 얼마나 잘 분석할 수 있는지 살펴본 첫 번째 종합적인 평가다.
연구진은 총 4개의 공개된 유방암 검사 데이터(EMBED, InBreast, CMMD, CBIS-DDSM)를 사용해 GPT-5가 유방암 위험도 평가, 이상한 부분 찾기, 암인지 아닌지 구분하기를 얼마나 잘하는지 확인했다. 결과적으로 GPT-5는 이전 버전들을 일관되게 앞섰으나, 실제 의사나 의료 전문 AI보다는 상당한 차이를 보였다. CBIS-DDSM 데이터에서 의사와 비교했을 때, 암을 제대로 찾아내는 능력에서 GPT-5는 63.5%로 의사의 86.9%보다 23.4% 낮았고, 정상을 정상으로 판단하는 능력에서는 52.3%로 의사의 88.9%보다 36.6% 낮은 성능을 기록했다.
EMBED 데이터에서 종양 찾기 64.5% 정확도, 전문 AI보다는 한참 부족
EMBED라는 유방암 검사 데이터를 가지고 테스트한 결과, GPT-5는 ChatGPT 시리즈 중에서는 가장 좋은 성과를 거뒀다. 유방 조직 밀도 구분에서 56.8%, 구조 변형 찾기에서 52.5%, 혹 분류에서 64.5%, 석회화 찾기에서 63.5%, 암 여부 판단에서 52.8%의 정확도를 보였다. 이는 GPT-5의 작은 버전들이나 이전 버전인 GPT-4보다 모두 나은 결과다.
그러나 유방암 검사만을 위해 특별히 만들어진 AI와 비교하면 아직 많이 부족했다. 유방암 전문 AI인 Mammo-CLIP은 암 판별에서 82.3%의 정확도를 보여 GPT-5보다 거의 30%나 높은 성능을 기록했다. 이는 모든 것을 다 할 수 있다고 하는 범용 AI가 의료 분야 같은 전문 영역에서는 아직 전문 AI를 이기기 어렵다는 것을 보여준다.
의사와 직접 비교하니 암 찾기 63.5%, 의사는 86.9%로 큰 차이
CBIS-DDSM이라는 유방암 검사 데이터를 통해 실제 의사와 GPT-5를 직접 비교해 본 결과, GPT-5의 한계가 더욱 명확하게 드러났다. 암을 제대로 찾아내는 능력에서 의사들은 86.9%의 정확도를 보인 반면, GPT-5는 63.5%에 그쳤다. 또한 정상을 정상으로 제대로 판단하는 능력에서도 의사는 88.9%였지만 GPT-5는 52.3%로 훨씬 떨어졌다.
더 작은 버전의 GPT 모델들은 성능이 더욱 걱정스러운 수준이었다. GPT-5-mini와 GPT-5-nano는 암 찾기에서 50% 이상 떨어지는 성능을 보였고, 정상 판단에서도 26% 가까이 의사보다 못했다. 이런 결과는 현재의 범용 AI가 의료 분야 전용 훈련 없이는 의사 수준의 정확도를 내기 어렵다는 점을 보여준다.
GPT-5가 자주 틀리는 패턴, 조직 촘촘한 유방을 덜 촘촘하다고 잘못 판단
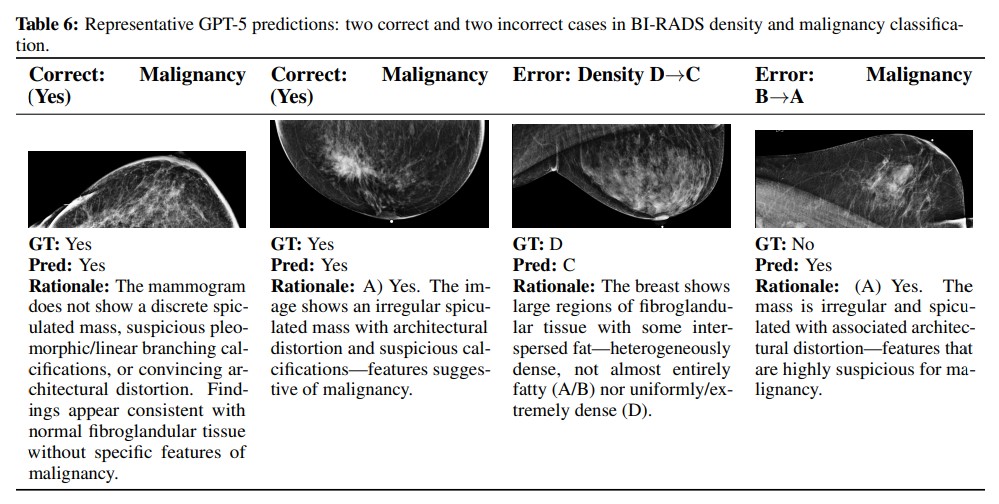
연구진은 GPT-5가 어떤 실수를 자주 하는지 알아보기 위해 대표적인 사례들을 자세히 살펴봤다. 유방 조직 밀도를 판단할 때 GPT-5는 매우 촘촘한 유방(D등급)을 덜 촘촘한 유방(C등급)으로 계속 잘못 판단했다. 이는 AI가 조직이 매우 촘촘한 유방에서 실제보다 밀도를 낮게 평가하는 경향이 있다는 뜻이다.
암 여부를 판단할 때는 실제로는 암이 아닌 양성 변화를 암이라고 잘못 진단하는 과진단 문제를 보였다. 구조가 비틀어져 보이거나 혹의 경계가 불규칙해 보이기만 해도 다른 암의 징후가 없는데도 암이라고 판단하는 경우가 많았다. 연구진은 이런 오류가 GPT-5가 고화질 유방 사진에 대한 전문 훈련이 부족하고, 의료진이 사용하는 표준 분류 방법에 맞춰 특별히 적응되지 않았기 때문이라고 분석했다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q: ChatGPT-5가 이전 버전보다 유방암 검사에서 얼마나 더 나아졌나요?
A: 모든 검사 항목에서 이전 버전인 GPT-4o보다 좋아졌습니다. 예를 들어 EMBED 데이터에서 암 여부 판단에서 GPT-4o는 42.5%였는데 GPT-5는 52.8%를 기록했고, 혹 찾기에서도 GPT-4o가 50.0%인데 GPT-5는 64.5%로 향상됐습니다.
Q: ChatGPT-5가 유방암 진단에서 자주 하는 실수는 무엇인가요?
A: 연구진이 분석한 결과 두 가지 주요 실수 패턴을 보였습니다. 첫째, 매우 촘촘한 유방 조직을 덜 촘촘하다고 계속 잘못 판단했습니다. 둘째, 실제로는 암이 아닌 양성 변화를 암이라고 과도하게 진단하는 경향을 보였는데, 구조가 비틀어져 보이거나 혹의 경계가 불규칙하기만 해도 암이라고 판단하는 경우가 많았습니다.
Q: 왜 ChatGPT-5는 유방암 검사에서 의사만큼 정확하지 못한가요?
A: 연구진에 따르면 GPT-5가 고화질 유방 사진에 대한 전문 훈련이 부족하고, 의료진이 사용하는 표준 분류 방법에 맞춰 특별히 적응되지 않았기 때문입니다. 유방암 진단은 매우 미세하고 대조가 낮은 특징들을 구분해야 하는 어려운 작업이어서 전문적인 훈련이 필요합니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문 명: Is ChatGPT-5 Ready for Mammogram VQA?
이미지 출처: Is ChatGPT-5 Ready for Mammogram VQA?
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





![[CES 2026] 가격표 붙은 ‘휴머노이드 로봇’ 시대… 집안을 보여줄 준비가 됐습니까?](https://aimatters.co.kr/wp-content/uploads/2026/01/AI-매터스-기사-썸네일-CES2026-robots.jpg)