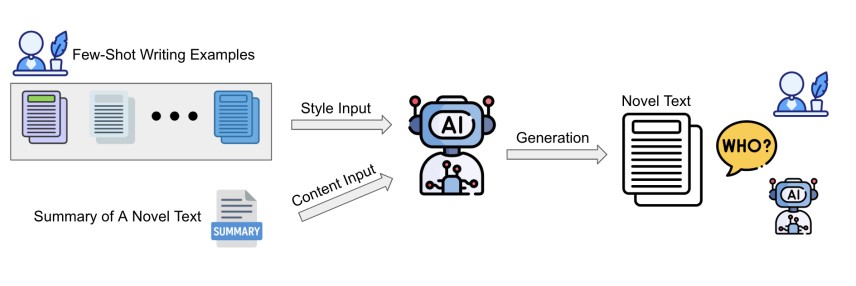
대형 언어모델(LLM)들이 개인 맞춤형 글쓰기 도구로 널리 활용되면서, 과연 AI가 몇 개의 예시만으로도 개인의 고유한 글쓰기 스타일을 완벽하게 모방할 수 있는지에 대한 의문이 제기되고 있다. 스토니브룩 대학교, 펜실베이니아 주립대학교, 보쉬 AI센터 공동 연구진이 발표한 연구에 따르면, GPT-4o(OpenAI), 제미나이 2.0-플래시(Google), 딥시크-V3(DeepSeek), 라마-4-매버릭(Meta) 등 비교적 최근 발표된 AI 모델들조차 일반인의 개인적이고 암묵적인 글쓰기 스타일을 정확히 모방하는 데 여전히 한계를 보이는 것으로 나타났다.
뉴스와 이메일은 성공, 블로그와 포럼은 실패… 도메인별 극명한 성능 격차
연구진은 뉴스 기사, 이메일, 온라인 포럼, 블로그 등 4개 분야에서 400명 이상의 실제 작가들이 작성한 글을 대상으로 6개의 최신 LLM 모델을 평가했다. 그 결과 AI 모델들은 뉴스나 이메일처럼 구조화되고 공식적인 글쓰기에서는 상당한 성능을 보였지만, 블로그나 포럼 같은 비공식적이고 미묘한 표현이 필요한 글쓰기에서는 어려움을 겪었다.
저자 검증(Authorship Verification) 정확도를 살펴보면, CCAT50 뉴스 데이터셋과 Enron 이메일 데이터셋에서는 95% 이상의 높은 정확도를 기록했지만, Reddit 포럼에서는 60% 내외, 블로그에서는 20% 미만으로 급격히 떨어졌다. 연구진은 이를 도메인별 특성 차이로 설명했다. 뉴스 기사의 경우 기자들이 서로 다른 주제를 다루어 구별이 용이하지만, 블로그나 포럼에서는 스타일적으로 다양하고 비공식적인 글쓰기가 많아 AI가 개인 특유의 패턴을 포착하기 어려웠다.
“더 많이 보여줘도 소용없다”… 예시 늘려도 개선 안 되는 AI 학습의 벽
연구진은 AI에게 제공하는 글쓰기 예시의 개수를 2개부터 10개까지 다양하게 조정하며 실험했다. 하지만 예시 개수를 늘려도 저자 귀속(Authorship Attribution)이나 저자 검증 정확도는 거의 개선되지 않았다. 이는 단순히 더 많은 예시를 제공하는 것만으로는 개인의 글쓰기 스타일을 정확히 학습할 수 없음을 보여준다.
연구진은 또한 다양한 예시 선별 전략을 시도했다. BERTopic을 활용해 내용 유사성에 기반해 예시를 선별하거나, 글의 길이를 맞춘 예시를 제공하는 방식을 테스트했다. 하지만 이런 전략들도 일관된 성능 향상을 가져오지 못했다. 특히 내용 기반 예시 선별은 일부 데이터셋에서 오히려 성능을 저하시켰다. 연구진은 이를 좁은 클러스터로 예시를 제한할 경우 스타일적 다양성이 줄어들어 개인 특유의 신호를 포착하기 어렵게 만드는 것으로 분석했다.
원본 텍스트의 첫 50단어나 20%를 미리 제공하는 ‘스니펫 포함’ 방식은 AI 탐지에서 인간으로 분류되는 비율을 높이는 데는 효과가 있었지만, 전반적인 저자 귀속이나 검증 성능에서는 혼재된 결과를 보였다.
GPTZero가 밝힌 충격적 사실… AI 글쓰기, 여전히 들킬 수밖에 없는 이유
GPTZero를 사용한 AI 탐지 실험에서는 흥미로운 결과가 나타났다. 대부분의 AI 생성 텍스트가 인간이 작성한 것으로 분류되는 비율이 낮았으며, 특히 GPT-4o와 GPT-4o-mini는 거의 0%에 가까운 인간 탐지율을 보였다. 반면 제미나이 2.0-플래시와 젬마-3-27B는 상대적으로 높은 인간 탐지율을 기록했다.
연구진은 이러한 차이가 GPTZero가 GPT 기반 모델 탐지에 최적화되어 있어 발생하는 편향일 가능성을 제기했다. 따라서 탐지율 차이는 실제 스타일 유사성보다는 탐지 도구의 편향을 반영할 수 있다고 해석했다. 또한 제로샷(0-shot) 설정에서는 모든 모델과 데이터셋에서 인간 탐지율이 더욱 낮아졌다.
파인튜닝도 RAG도 현실성 제로… 연구진이 단순 프롬프팅만 택한 이유
연구진이 파인튜닝이나 복잡한 프롬프팅 기법을 배제한 이유는 실용성 때문이다. 실제 사용자들은 제한된 수의 글쓰기 샘플만을 제공하며, 개별 사용자마다 파인튜닝된 모델을 유지하는 것은 비용과 확장성 면에서 비현실적이다. 또한 여러 번의 API 호출이 필요한 복잡한 기법들은 실시간 사용 시 지연시간과 비용 문제를 야기한다.
연구진은 일반 사용자가 그래픽 인터페이스를 통해 AI와 상호작용하는 현실적인 시나리오에 초점을 맞춰, 단일 API 호출로 가능한 몇 샷 프롬프팅의 한계를 정확히 평가하고자 했다고 설명했다. 이는 현재 기술 수준에서 달성 가능한 개인화의 실제 한계를 이해하는 데 중요한 의미가 있다.
연구진은 진정한 개인 맞춤형 글쓰기를 위해서는 암묵적이고 스타일 일관성 있는 생성을 지원하는 개선된 기법이 필요하다고 결론지었다.
AI 개인화의 딜레마… “완벽한 모방 vs 창작자 정체성” 기로
이번 연구 결과는 현재 AI 기술이 직면한 근본적인 한계를 명확히 보여준다. 연구진이 의도적으로 파인튜닝이나 복잡한 프롬프팅 기법을 배제하고 일반 사용자가 실제로 사용하는 방식에 초점을 맞춘 점이 특히 주목할 만하다. 이는 AI 업계가 흔히 보여주는 ‘실험실 환경에서의 성능’과 ‘실제 사용 환경에서의 성능’ 사이의 간극을 정확히 드러낸다.
연구에서 GPT-4o부터 최신 혼합 전문가(MoE) 모델인 딥시크-V3, 라마-4-매버릭까지 다양한 아키텍처의 모델들을 테스트했음에도 개인 스타일 모방에서는 유사한 한계를 보인 점도 시사하는 바가 크다. 이는 단순한 모델 크기 확장이나 파라미터 증가만으로는 개인화 문제를 해결하기 어려움을 의미한다.
이는 단순한 모델 확장만으로는 개인화 문제를 해결할 수 없음을 의미한다. 오히려 업계는 스타일 일관성을 위한 새로운 아키텍처나 훈련 방법론 개발에 더 집중해야 할 필요성이 제기된다. 특히 실시간 상호작용이 중요한 개인 어시스턴트 분야에서는 복잡한 파인튜닝이나 다중 API 호출 방식보다는 효율적이면서도 효과적인 개인화 기법이 절실하다. 이번 연구는 AI가 범용성과 개인화 사이에서 균형을 찾아야 하는 새로운 도전에 직면했음을 보여주는 중요한 이정표가 될 것으로 보인다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q: AI가 개인 글쓰기 스타일을 모방할 때 가장 어려워하는 부분은 무엇인가요?
A: AI는 블로그나 온라인 포럼 같은 비공식적이고 개인적인 글쓰기에서 가장 큰 어려움을 겪습니다. 이런 글쓰기는 개인의 미묘한 감정 표현, 독특한 어투, 창의적인 표현 방식이 많이 들어가기 때문에 AI가 따라하기 어렵습니다.
Q: AI에게 더 많은 글쓰기 예시를 보여주면 성능이 향상되나요?
A: 연구 결과에 따르면 예시 개수를 늘려도 성능 향상은 미미합니다. 2개에서 10개까지 예시를 늘려도 스타일 모방 능력은 거의 개선되지 않았습니다. 단순히 양을 늘리는 것보다는 질적으로 다른 접근 방식이 필요합니다.
Q: AI가 생성한 글을 인간이 쓴 글과 구별할 수 있나요?
A: 네, 가능합니다. GPTZero 같은 AI 탐지 도구는 여전히 AI가 생성한 텍스트를 식별할 수 있습니다. 다만 모델에 따라 탐지율에 차이가 있어, 이는 탐지 도구의 편향일 가능성도 있습니다.
기사에 인용된 논문 원문은 arXiv에서 확인할 수 있다.
논문명: Catch Me If You Can? Not Yet: LLMs Still Struggle to Imitate the Implicit Writing Styles of Everyday Authors
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.