
인공지능이 지식과 추론 벤치마크에서 빠르게 발전하고 있지만, 실제 경제적 가치를 창출하는 업무를 자동화하는 능력은 여전히 바닥 수준에 머물러 있다는 연구 결과가 나왔다. AI 안전 센터(Center for AI Safety)와 스케일AI(Scale AI)가 공동 개발한 원격 노동 지수(Remote Labor Index, RLI)는 AI 에이전트가 실제 온라인 업무를 완수할 수 있는지를 측정하는 최초의 표준화된 벤치마크다.
온라인 프리랜서 플랫폼에서 수집한 240개 실제 프로젝트
연구 논문에 따르면, RLI는 온라인 프리랜서 플랫폼에서 직접 수집한 240개의 프로젝트로 구성됐다. 각 프로젝트는 작업 설명서(Brief), 프로젝트 완수에 필요한 입력 파일(Input files), 그리고 인간 프리랜서가 제작한 골드 스탠다드 결과물(Human deliverable)로 이뤄져 있다. 이 구조는 AI 에이전트가 경제적으로 가치 있는 작업을 생산할 수 있는지 직접 평가할 수 있게 한다. 벤치마크는 게임 개발, 제품 디자인, 건축, 데이터 분석 등을 포함해 업워크(Upwork) 분류 체계의 23개 카테고리를 포괄한다. 프로젝트 완료에 소요된 평균 시간은 28.9시간, 중간값은 11.5시간이었다. 평균 비용은 632.6달러, 중간값은 200달러였다. 전체적으로 RLI의 프로젝트들은 6,000시간 이상의 실제 작업과 14만 달러 이상의 가치를 대표한다.
기존 벤치마크보다 2배 이상 복잡하고 다양한 업무 유형
RLI는 기존 벤치마크들보다 실제 프리랜서 업무의 복잡성과 다양성에 훨씬 가깝다. 완료 시간 측면에서 RLI 프로젝트는 기존 비교 가능한 벤치마크들보다 2배 이상 길다. 업무 유형 분포에서도 차이가 크다. 이전 에이전트 벤치마크들은 주로 소프트웨어 엔지니어링이나 웹 기반 연구 및 작성 업무에 초점을 맞췄지만, 실제 온라인 업무 시장은 훨씬 더 다양하다. RLI는 이러한 더 넓은 현실을 반영하도록 설계됐다. 디자인, 운영, 마케팅, 관리, 데이터 및 비즈니스 인텔리전스, 오디오-비디오 제작 등을 상당 부분 포괄하며, 작업 복잡도와 결과물 유형을 샘플링해 종단간(end-to-end) 프리랜서 온라인 업무를 반영한다. 입력 파일과 결과물이 포괄하는 파일 형식도 이전 벤치마크들보다 훨씬 다양하다.
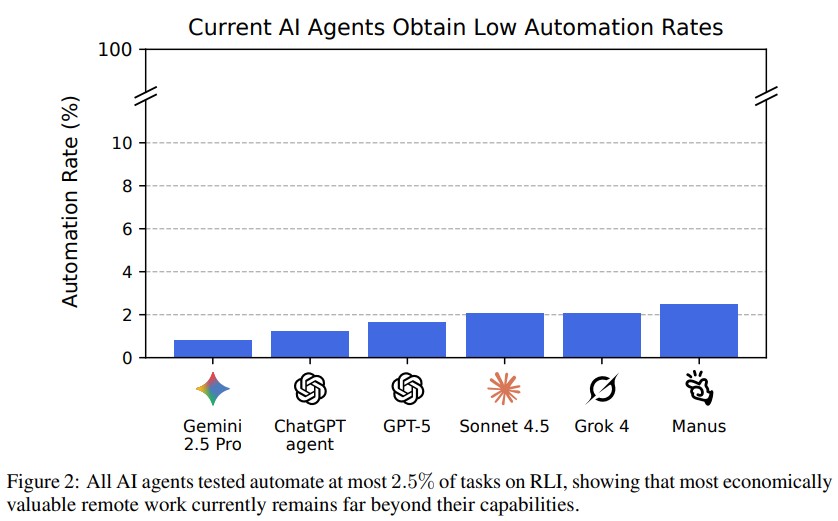
최고 성능 AI도 자동화율 2.5%… 대부분 프로젝트 완수 실패
연구팀은 챗GPT 에이전트(ChatGPT agent), GPT-5, 클로드 소네트 4.5(Claude Sonnet 4.5), 그록 4(Grok 4), 제미나이 2.5 프로(Gemini 2.5 Pro), 마누스(Manus) 등 여러 최첨단 AI 에이전트 프레임워크를 평가했다. 평가는 AI 결과물을 인간 골드 스탠다드와 비교하는 엄격한 수동 평가 프로세스를 사용했다. 결과는 벤치마크에서의 성능이 현재 바닥 근처에 있음을 보여준다. 현재 최고 성능 AI 에이전트는 자동화율 2.5%를 달성했으며, 현실적인 프리랜싱 환경에서 의뢰받은 작업으로 받아들여질 수준으로 대부분의 프로젝트를 완수하지 못했다. 이는 지식과 추론 벤치마크에서의 빠른 진전에도 불구하고 현대 AI 시스템이 온라인 업무의 다양한 요구를 자율적으로 수행하는 것과는 거리가 멀다는 것을 보여준다.
품질 저하 45.6%, 불완전한 결과물 35.7%… 주요 실패 원인 분석
현재 시스템의 한계와 낮은 자동화율의 이유를 이해하기 위해 연구팀은 평가자들이 제공한 서면 평가를 클러스터링해 에이전트 실패에 대한 질적 분석을 수행했다. 약 400개의 평가에 걸친 질적 분석은 거부가 주로 다음과 같은 주요 실패 범주로 집중됨을 보여준다. 기술적 및 파일 무결성 문제로, 많은 실패가 손상되거나 빈 파일 생성, 잘못되거나 사용할 수 없는 형식으로 작업물 전달 같은 기본적인 기술적 문제 때문이었다(17.6%). 불완전하거나 형식이 잘못된 결과물로, 에이전트들이 자주 누락된 구성 요소, 잘린 비디오, 또는 소스 자산이 없는 불완전한 작업을 제출했다(35.7%). 품질 문제로, 에이전트가 완전한 결과물을 생성하더라도 작업의 품질이 자주 낮아 전문적 기준을 충족하지 못했다(45.6%). 불일치로, 특히 AI 생성 도구를 사용할 때 AI 작업이 종종 결과물 파일 간 불일치를 보였다(14.8%).
오디오 편집과 이미지 생성에서는 인간 수준 달성
소수의 프로젝트에서 AI 결과물이 인간 결과물과 비교 가능하거나 더 나은 것으로 평가됐다. 이들은 주로 창의적 프로젝트, 특히 오디오 및 이미지 관련 작업과 작문 및 데이터 검색 및 웹 스크래핑이었다. 구체적으로 연구팀이 테스트한 모든 모델에 걸쳐 성능이 여러 오디오 편집, 믹싱 및 제작 작업(예: 레트로 비디오 게임용 맞춤 음향 효과 생성, 단일 트랙에서 보컬과 반주 분리, 인트로 및 아웃트로 음악과 보이스오버 병합)과 이미지 생성 작업(예: 광고 및 로고 생성)에서 인간 기준선과 일치하거나 초과했다. AI는 또한 보고서 작성과 대화형 데이터 시각화용 코드 생성에서도 좋은 성과를 보였다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 원격 노동 지수(RLI)는 어떻게 만들어졌나요?
A: RLI는 업워크 같은 프리랜서 플랫폼에서 실제로 거래된 프로젝트들을 수집해 만들어졌습니다. 358명의 검증된 프리랜서로부터 550개의 초기 프로젝트를 수집했고, 여러 단계의 검토와 정제 과정을 거쳐 최종 240개 프로젝트를 선정했습니다. 각 프로젝트는 자체 완결적이고 재현 가능한 벤치마크가 되도록 철저히 점검됐습니다.
Q2. AI 결과물은 어떻게 평가하나요?
A: 훈련된 평가자들이 AI 결과물을 인간이 만든 골드 스탠다드와 비교해 수동으로 평가합니다. 평가자들은 “합리적인 고객” 관점에서 AI 결과물이 의뢰받은 작업으로 받아들여질지 판단합니다. 평가자 간 일치율은 94.4%로 높은 신뢰성을 보입니다. 자동 평가 시스템으로는 불가능한 복잡한 멀티미디어 결과물을 평가하기 위해 이 방식을 사용합니다.
Q3. RLI는 모든 온라인 업무를 대표하나요?
A: 아니요. RLI는 고객과의 상호작용이 필요한 업무(예: 과외), 팀 작업이 필요한 업무(예: 프로젝트 관리), 웹 기반 평가 플랫폼에서 렌더링할 수 없는 결과물(예: 데스크톱 애플리케이션 개발) 등은 제외합니다. 따라서 AI가 RLI에서 100% 자동화율을 달성하더라도 평가하지 않는 업무 유형에서는 여전히 인간보다 낮은 성과를 낼 수 있습니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: Remote Labor Index: Measuring AI Automation of Remote Work
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





