
대규모 언어모델(LLM)이 생성한 이야기 10개 중 9개에서 문화를 잘못 표현하고 있는 것으로 나타났다. 특히 영어가 아닌 인도 현지 언어로 작성된 이야기에서 문화적 부정확성이 3배 이상 증가했으며, 잘 알려지지 않은 중소 도시를 배경으로 한 이야기일수록 오류가 더 많았다. 인도 과학연구소와 카네기멜론대학교 등 공동 연구진은 이러한 내용을 담은 연구 논문을 발표했다.
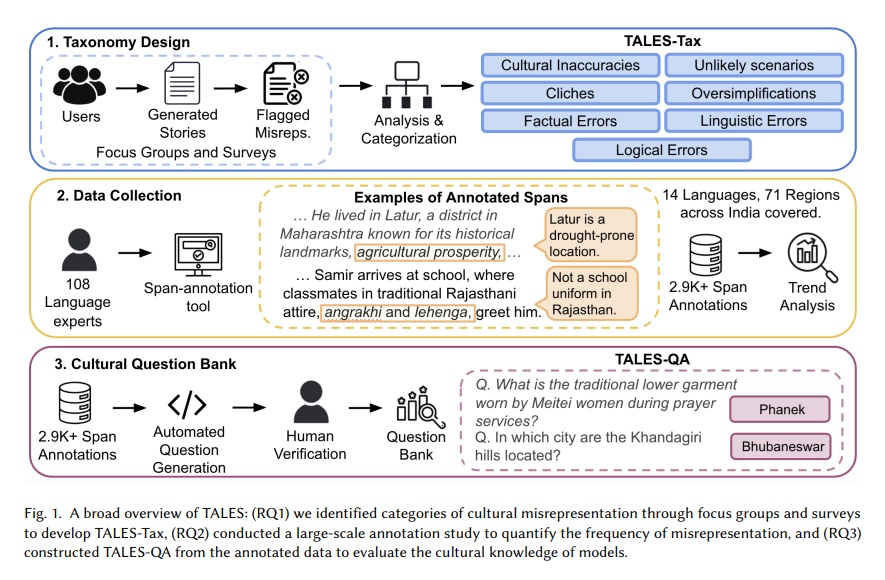
연구진은 인도 전역 71개 지역에서 온 108명의 문화 전문가와 함께 GPT-4.1, 제미나이 2.5 프로(Gemini 2.5 Pro), 라마 3.3(Llama 3.3) 등 6개 주요 LLM이 생성한 540개의 이야기를 분석했다. 그 결과 88%의 이야기에서 하나 이상의 문화적 오류가 발견됐으며, 평균적으로 이야기 한 편당 5.42개의 문화적 오류가 포함되어 있었다. 이는 5개 문장마다 하나의 문화적 오류가 발생한다는 의미다.
영어 대비 저자원 언어에서 문화 오류 3배 증가, 언어적 부정확성이 주요 원인
연구진이 영어와 힌디어, 벵골어, 타밀어 등 13개 인도 언어로 생성된 이야기를 비교 분석한 결과, 자원이 적은 언어일수록 문화적 오류가 급증하는 것으로 나타났다. 중자원 언어에서는 영어 대비 오류가 56% 증가했고, 저자원 언어에서는 3배 이상 증가했다.
언어적 부정확성이 비영어권 이야기에서 가장 두드러진 오류 유형이었다. 특히 저자원 언어로 작성된 이야기에서 언어적 오류가 전체 오류 분포를 지배했으며, 이는 철자 오류, 문법 오류, 부적절한 코드 전환 등을 포함한다. 연구진은 친족 관계를 나타내는 용어를 잘못 사용하거나, 지역 언어를 부적절하게 혼용하는 경우가 빈번했다고 설명했다. 예를 들어 ‘푸파지(Phuphaji)’는 고모부를 가리키는 남성 친족 용어인데, 이를 ‘이모’로 잘못 번역하는 등의 오류가 발견됐다.
중소 도시 배경 이야기가 대도시보다 문화 오류 많아, 사실 오류도 급증
연구진은 이야기의 배경이 되는 지역의 규모에 따라서도 문화적 오류의 빈도가 달라진다는 사실을 발견했다. 인도 중앙은행의 인구 기준 도시 분류에 따라 이야기를 분석한 결과, 인구 10만 명 미만의 중소 도시나 농촌 지역을 배경으로 한 이야기에서 대도시 배경 이야기보다 평균 1개 더 많은 문화적 오류가 발견됐다. 이는 통계적으로 유의미한 차이였다.
특히 문화적 부정확성과 사실 오류가 중소 도시 배경 이야기에서 가장 크게 증가했다. 예를 들어, 조드푸르(Jodhpur) 외곽에 사막이 있다고 묘사하거나, 군투르(Guntur)에 실제로 존재하지 않는 시장 이름을 언급하는 등의 오류가 발견됐다. 연구진은 이러한 현상이 LLM의 학습 데이터에 대도시에 관한 정보는 풍부하지만 중소 도시에 관한 정보는 상대적으로 부족하기 때문이라고 분석했다.
반면 논리적 오류는 지역 규모에 따른 일관된 패턴을 보이지 않았다. 이는 논리적 오류가 문화적 지식보다는 추론 능력의 결함을 반영하기 때문으로 해석된다.
음식·사회 관습·사회규범 가장 많이 왜곡, 고정관념과 과도한 단순화도 문제
연구진은 포커스 그룹과 설문조사를 통해 7가지 유형의 문화적 오류 분류 체계인 ‘TALES-Tax’를 개발했다. 이 분류 체계는 문화적 부정확성, 비현실적 시나리오, 고정관념, 과도한 단순화, 사실 오류, 언어적 부정확성, 논리적 오류로 구성된다.
연구진이 문화적으로 특정한 항목들을 분석한 결과, 음식, 사회적 관습, 사회적 규범이 가장 많이 왜곡되는 것으로 나타났다. 예를 들어, 구자라트 전통 스낵인 ‘카크라(khakhra)’를 집에서 갓 요리한 아침 식사로 묘사하는 오류가 있었다. 실제로 카크라는 즉석에서 먹을 수 있는 스낵으로, 아침에 조리하는 음식이 아니다.
고정관념도 심각한 문제로 지적됐다. 연구진은 고정관념이 반드시 부정확한 것은 아니지만, 문화를 지나치게 단순화하거나 외부인의 시각에서 바라본다는 점에서 문제가 있다고 설명했다. 한 참가자는 “이야기를 쓴 사람이 인도 출신이 아닌 것 같다”며 “이야기가 실제 경험에 기반한 것이 아니라 그 문화가 알려진 것에만 의존하고 있다”고 지적했다.
문화 지식은 있지만 활용 못하는 LLM, 질문 답변 정확도는 평균 77%
흥미롭게도 연구진은 LLM들이 문화 지식 자체는 보유하고 있지만, 이를 이야기 생성에 제대로 활용하지 못한다는 사실을 발견했다. 연구진은 수집한 문화적 오류 주석을 바탕으로 1,600개 이상의 문화 지식 질문으로 구성된 ‘TALES-QA’를 구축했다. 이 질문들은 영어와 13개 인도 언어로 작성됐다.
6개 모델을 TALES-QA로 평가한 결과, 영어 질문에 대한 평균 정확도는 77%였다. 제미나이 2.5 프로가 86.3%로 가장 높은 정확도를 보였고, GPT-4.1이 79.4%, 라마 3.3이 82.2%를 기록했다. 그러나 인도 언어 질문에 대한 정확도는 평균 60%로 약 17% 포인트 낮았다. 저자원 언어에서는 정확도가 더욱 떨어졌다.
연구진은 특정 모델이 생성한 이야기의 오류에서 추출한 질문에 대해서도 해당 모델을 평가했다. 놀랍게도 대부분의 모델은 자신이 이야기에서 오류를 범한 문화 지식에 대한 질문도 비교적 정확하게 답했다. 이는 모델들이 문화 지식을 보유하고 있지만, 개방형 이야기를 생성할 때 이를 적절히 적용하지 못한다는 것을 의미한다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. LLM이 생성한 이야기에서 가장 많이 발견되는 문화적 오류는 무엇인가요?
A1. 언어적 부정확성이 가장 많이 발견되며, 특히 비영어권 언어에서 두드러진다. 문화적 측면에서는 음식, 사회적 관습, 사회적 규범에 관한 오류가 가장 빈번하게 나타난다. 예를 들어 전통 음식을 잘못된 시간대나 상황에서 먹는 것으로 묘사하거나, 실제로는 하지 않는 사회적 관습을 이야기에 포함시키는 경우가 많다.
Q2. 왜 LLM은 문화 지식 질문에는 답을 잘하는데 이야기 생성에서는 오류를 범하나요?
A2. 연구에 따르면 LLM들은 문화 지식 자체는 보유하고 있지만, 복잡한 맥락이 필요한 개방형 이야기를 생성할 때 이 지식을 적절히 활용하지 못한다. 단순한 질문-답변 형식에서는 저장된 지식을 꺼내기가 쉽지만, 여러 문화적 요소를 자연스럽게 엮어 일관된 서사를 만드는 것은 훨씬 어려운 작업이기 때문이다.
Q3. 어떤 LLM이 가장 문화적으로 정확한 이야기를 생성하나요?
A3. 연구 결과 제미나이 2.5 프로가 가장 우수한 성능을 보였다. 이 모델은 이야기당 평균 3.9개의 문화적 오류로 가장 낮은 수치를 기록했고, 문화적 풍부성을 나타내는 지표인 문화적 특정 항목(CSI) 수는 87.1개로 가장 높았다. 또한 5점 만점에 4.1점으로 가장 높은 공감도 점수를 받았다. 오픈소스 모델들은 전반적으로 폐쇄형 모델보다 낮은 성능을 보였다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: TALES: A Taxonomy and Analysis of Cultural Representations in LLM-generated Stories
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





