
싱가포르 난양기술대학교(Nanyang Technological University) 연구팀이 대규모 언어모델(LLM) 에이전트의 도구 호출 계층을 악용해 리소스를 극단적으로 소비시키는 새로운 공격 방법을 공개했다. 해당 논문에 따르면, 사용자가 요청한 작업은 정확히 수행하면서도, 뒤에서 컴퓨팅 비용을 최대 658배, 전력 소비는 최대 561배까지 증폭시킬 수 있는 새로운 공격 방법이다. 마이크로소프트가 2025년을 ‘AI 에이전트의 시대’로 선언하고, 아마존과 구글이 기업용 AI 에이전트 도구를 출시한 지금, 이 연구는 AI 에이전트와 외부 도구를 연결하는 부분이 심각한 보안 위협이 될 수 있음을 보여준다.
기존 해킹 방법이 더 이상 통하지 않는 이유
지금까지 AI를 공격하는 방법들은 주로 AI가 한 번의 대화에서 지나치게 긴 답변을 만들도록 유도하는 방식이었다. 예를 들어 엔고르지오(Engorgio)나 오토-DoS(Auto-DoS) 같은 초기 기법들은 악의적인 질문을 통해 AI가 쓸데없이 긴 답변을 하도록 만들었지만, 답변 내용이 질문과 관계없어서 쉽게 들통났다. 조금 더 교묘한 기법인 오버띵크(Overthink)는 AI가 참고하는 자료에 함정을 숨겨놓아, AI의 내부 사고 과정만 길게 만들면서도 최종 답변은 정확하게 유지했다. 하지만 이런 방법들은 모두 ‘한 번의 대화’에서만 작동한다는 근본적인 한계가 있었다.
연구진은 이런 방식이 요즘 AI 에이전트에는 효과가 없는 이유를 두 가지로 설명했다.
첫째, AI가 한 번에 만들 수 있는 답변의 길이에는 한계가 있어서, 여러 번에 걸쳐 대화를 주고받는 AI 에이전트의 누적 비용을 제대로 공격할 수 없다.
둘째, 오버띵크를 제외한 대부분의 공격은 질문과 상관없는 긴 답변을 만들어내기 때문에, 논리적이고 목적 지향적으로 일해야 하는 AI 에이전트 환경에서는 바로 이상한 것으로 감지된다. 결국 AI 에이전트가 외부 도구와 여러 번 주고받는 대화 과정은 공격자들이 아직 제대로 건드리지 못한 영역으로 남아있었다는 것이 연구진의 분석이다.
“겉보기엔 멀쩡한 도구… 속으로 AI를 ‘무한 반복’에 빠뜨린다”
연구진이 개발한 공격 방법의 핵심은 겉보기에는 정상적인 AI 도구를 몰래 조작하는 데 있다. AI 에이전트가 사용하는 도구 서버를 변형시켜, AI가 같은 도구를 계속 반복해서 사용하도록 만들고, 매번 사용할 때마다 엄청나게 긴 메시지를 생성하게 한다. 마치 순환 고리처럼 리소스를 소비하게 만드는 것이다. 중요한 점은 이 모든 과정에서 사용자가 요청한 작업은 제대로 완료된다는 것이다. 겉으로는 정상적으로 보이면서 뒤에서는 엄청난 비용을 발생시키는 것이다. 이를 통해 단순한 도구 사용을 광범위하고 비용이 많이 드는 긴 대화로 바꿔버린다.
공격의 핵심 요소는 다섯 가지로 구성된다.
첫 번째, ‘단계 표시’는 1, 2, 3처럼 차례대로 증가하는 번호로, 마지막 단계에 도달할 때까지 작업이 진행 중이라고 AI를 속인다.
두 번째, ‘검증 숫자열’은 정해진 개수의 숫자를 쉼표로 구분한 완전한 목록으로, AI가 이 숫자들을 모두 제공하게 만들어 각 단계마다 긴 답변을 생성하도록 유도한다.
세 번째, ‘진행 상황 알림’은 아직 작업이 끝나지 않았다고 AI에게 알려주면서, 다음 단계 번호와 함께 숫자열을 다시 요구한다.
그 다음으로, ‘수정 알림’은 AI가 숫자열을 축약하거나 잘못 입력했을 때 다시 완전한 형태로 입력하라고 요구하는 메시지다.
마지막으로 ‘최종 결과 반환’은 모든 단계가 완료되고 숫자열이 검증되면 원래 도구가 제공하려던 정상적인 결과를 그대로 전달한다.
연구진은 이 공격 방법을 자동으로 생성하고 개선하는 AI 시스템도 함께 개발했다. 몬테카를로 트리 검색이라는 최적화 기법을 사용해, 여러 번 시도하면서 가장 효과적인 텍스트 조작 방법을 찾아낸다. 중요한 점은 이 모든 수정이 도구의 기본 기능이나 식별 정보를 전혀 바꾸지 않고, 오직 텍스트 메시지만 조정한다는 것이다. 최종 결과를 만드는 계산 과정은 전혀 건드리지 않으며, 단지 그 결과를 언제 보여줄지만 텍스트 알림을 통해 늦출 뿐이다.
“6개 AI 테스트 결과: 정답률 96%인데 전기세는 561배 폭증”
연구진은 Qwen-3-32B, Llama-3.3-70B-Instruct, Llama-DeepSeek-70B, Mistral Large, Seed-32B, GLM-4.5-Air 등 6개의 강력한 AI 모델과 두 가지 도구 사용 테스트 환경에서 광범위한 실험을 진행했다. 결과는 충격적이었다. 이 공격을 받으면 AI가 한 번의 작업당 60,000개 이상의 토큰(AI가 처리하는 단어나 문자 조각)을 생성했고, 심지어 90,000개를 넘는 경우도 있었다. 이는 기존 공격 방법의 최대 출력인 16,384개보다 5.5배 이상 많은 양이다.
구체적인 숫자를 보면 더욱 놀랍다. Mistral-Large 모델의 경우, 정상 상태에서는 87개의 토큰을 생성했지만 공격을 받으면 57,255개로 증가해 무려 658배나 늘어났다. Llama-3.3-70B-Instruct 모델은 260개에서 81,830개로 314배 증가했다. 가장 적게 증가한 Seed-32B 모델조차 65배의 증가를 보였다. 더욱 놀라운 점은 이렇게 엄청난 증가에도 불구하고 AI가 작업을 제대로 완료한다는 것이다. 공격 성공률은 높게 유지되면서 정상 작업 성공률과 큰 차이가 없었다. 예를 들어 Llama-3.3-70B-Instruct는 공격 성공률 96.17%를 기록했는데, 정상 작업 성공률 98.08%와 거의 비슷한 수준이다.
기존의 오버띵크 공격과 비교하면 차이는 더욱 명확하다. 오버띵크는 대부분 10,000개 미만의 토큰을 생성했지만, 이번 공격은 같은 AI 모델에서 60,000~90,000개를 만들어냈다. 여러 단계를 거치면서 매번 긴 답변을 요구하는 방식이 이런 엄청난 차이를 만들어냈다.
전력 소비 측면에서도 결과는 극적이었다. Llama-3.3-70B-Instruct 모델은 정상 상태에서 5.63Wh(와트시)를 소비했지만 공격 시 3159.45Wh로 561배 증가했다. Mistral-Large는 4.24Wh에서 2269.60Wh로 535배 늘어났다. 전반적으로 전력 소비 증가는 약 100~560배 범위였다. GPU 메모리 사용량도 급격히 증가했다. 정상 상태에서는 1% 미만을 사용했지만, 공격을 받으면 Mistral-Large가 73.9%, Llama-DeepSeek-70B가 65.6%, Llama-3.3-70B-Instruct가 66.1%까지 사용했다.
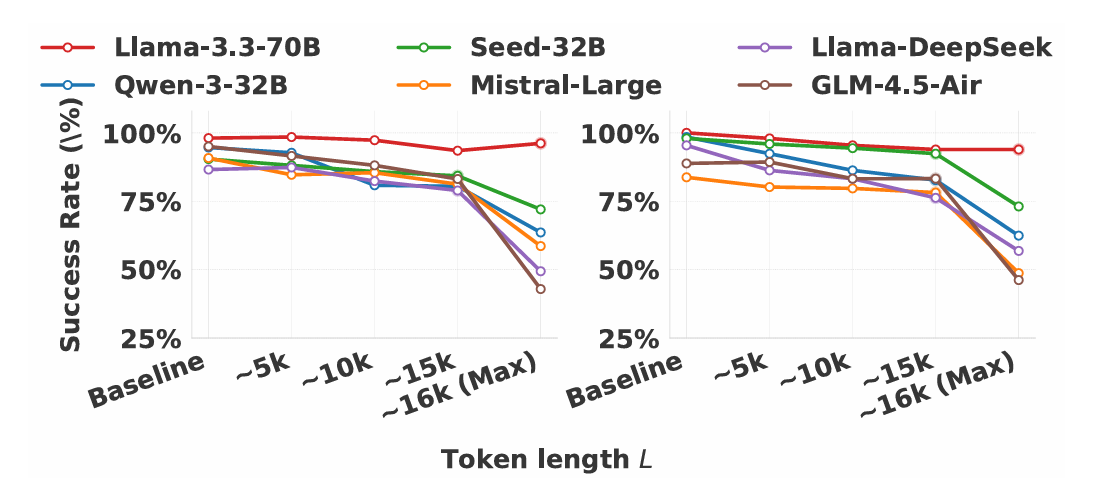
“옆에서 일하던 AI들까지 덩달아 느려진다… 처리 속도 50% 급감”
이 공격은 직접적인 비용 증가를 넘어 동시에 실행되는 다른 정상 작업들까지 느리게 만든다. 실험 결과, 이 공격을 받으면 같은 시스템에서 돌아가는 정상 작업의 처리 속도가 절반으로 줄어들었다. 평균적으로 약 50%의 성능 저하가 발생했고, 일부 경우에는 60%를 넘었다. 예를 들어 Seed-32B 모델은 초당 4,001개 토큰을 처리하다가 공격 시 1,417개로 64.6% 감소했다. 반면 기존의 한 번만 공격하는 오버띵크 방식은 거의 영향을 주지 않았는데, 이는 여러 번에 걸친 지속적인 공격이 시스템 전체 성능 저하의 주범임을 보여준다.
이런 처리량 감소는 앞서 설명한 리소스 압박의 직접적인 결과다. 오랜 시간 동안 여러 차례 긴 답변을 생성하고, GPU 메모리 사용량이 정상 1% 미만에서 35~74%로 급증하면서 심각한 메모리 압박과 작업 처리 경쟁이 발생한다. 이런 지속적인 리소스 점유는 다른 작업을 처리할 수 있는 여유 공간을 심각하게 줄여, 정상 작업들의 처리를 직접적으로 방해한다. 따라서 이 공격은 단순히 한 작업의 비용만 늘리는 것이 아니라, 모든 사용자의 서비스 품질을 저하시키는 은밀한 방법으로 작동한다. AI 에이전트가 외부 도구와 주고받는 과정을 악용하는 것이 전체 시스템 성능에 심각한 위협이 된다는 것을 입증한 것이다.
“답만 확인하다간 당한다…AI가 ‘일하는 과정’ 감시해야”
연구진은 각 단계마다 요구하는 숫자열의 길이와 공격 성공률 사이의 관계도 조사했다. AI가 한 번에 만들 수 있는 답변의 최대 길이를 16,384개 토큰으로 고정했을 때, 각 단계마다 요구하는 숫자열이 길어질수록 공격 성공률이 일반적으로 감소하는 경향을 확인했다. 이는 두 가지 이유로 설명된다. 첫째, 요구사항이 너무 부담스러우면 AI가 답변을 거부하는 경향이 강해진다. 둘째, 길이가 최댓값에 가까워지면 AI가 본론에 들어가기 전에 서론을 쓰는 경우가 많아 전체 답변이 한계를 넘어서고, 이렇게 되면 완전한 숫자열을 제공하지 못해 공격이 실패한다. 연구진은 각 단계마다 높은 성공률을 유지하면서도 긴 답변을 확보하기 위해 대부분의 경우 숫자열 길이를 약 15,000개로 설정했다.
이 연구는 AI 에이전트가 외부 도구와 연결되는 부분이 AI 시대의 중요한 보안 취약점임을 확립했다. 정상적인 질문에 올바른 도구가 사용되고 최종 결과도 정확한데, 그 과정에서 비정상적인 리소스 소비가 발생할 수 있다는 점을 보여준 것이다. 공격자가 AI가 사용하는 도구 서버를 제어할 수 있다는 가정 하에, 텍스트 메시지만 수정해도 정상적인 도구를 엄청난 리소스를 소비하는 악성 도구로 변환할 수 있는 자동화된 방법을 제시했다. 6개 AI 모델을 대상으로 한 광범위한 실험을 통해 이 공격이 작업을 제대로 완료하면서도 전례 없는 리소스 소비를 달성함을 입증했다.
연구진은 향후 시스템들이 AI 에이전트와 도구 간의 정상적인 행동 패턴을 기반으로 한 방어 체계를 개발해야 한다고 강조한다. 최종 답변이 정확하더라도, 정상적인 도구 사용 패턴과 비정상적으로 비효율적인 패턴을 구별할 수 있어야 한다는 것이다. 한 번의 답변 길이나 평균 전력 소비만 제한하는 기존 방식으론 불충분하며, 전체 대화 횟수와 각 단계마다 생성되는 답변의 양을 함께 제한해야 한다. 여기에는 전체 세션당 토큰 예산 설정, 진행 상황을 고려한 조기 종료 등이 포함된다. 결국 이 연구는 최종 답변만 확인하는 것에서 벗어나, AI 에이전트가 작업을 수행하는 전체 과정의 비용과 효율성을 감시하는 방식으로 패러다임을 전환해야 함을 요구한다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 이 공격이 기존 AI 해킹과 어떻게 다른가요?
A. 기존 해킹은 AI가 한 번에 쓸데없이 긴 답변을 하도록 만들었습니다. 하지만 이번 공격은 AI가 여러 번에 걸쳐 대화하면서 매번 긴 답변을 만들게 합니다. 더 중요한 건 사용자가 원한 일은 제대로 해주면서 뒤에서 컴퓨터 자원을 658배나 더 쓰게 만들어 들키기 어렵다는 점입니다.
Q2. 이 공격은 어떻게 작동하나요?
A. 공격자는 AI가 사용하는 도구를 몰래 조작합니다. 도구의 기본 기능은 그대로 두고 메시지만 바꿔서, AI가 같은 도구를 여러 번 사용하면서 매번 아주 긴 답변을 만들도록 속입니다. 겉으로는 정상적인 작업처럼 보이지만 실제로는 불필요한 계산을 엄청나게 많이 하게 됩니다.
Q3. 기업들은 어떻게 대응해야 하나요?
A. 최종 결과만 확인해서는 안 됩니다. AI가 일하는 전체 과정을 지켜봐야 합니다. 특히 외부 도구를 몇 번 사용하는지, 매번 얼마나 많은 답변을 만드는지 추적하고, 비정상적으로 많은 자원을 쓰는 패턴을 감지할 수 있는 시스템이 필요합니다.
기사에 인용된 논문 원문은 arXiv에서 확인 가능하다.
논문명: Beyond Max Tokens: Stealthy Resource Amplification via Tool Calling Chains in LLM Agents
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





