
구글 딥마인드(Google DeepMind)가 평면 영상에서 입체 공간과 시간의 흐름을 동시에 파악하는 새로운 AI 모델 ‘D4RT’를 공개했다. 해당 리포트에 따르면, 이 기술은 기존보다 최대 300배 빠른 속도로 움직이는 장면을 분석하며, 로봇과 증강현실(AR) 분야에 큰 변화를 가져올 전망이다.
인간의 눈처럼 과거와 미래를 동시에 보는 AI
사람은 세상을 볼 때 지금 이 순간만 보는 게 아니다. 방금 전 상황을 기억하고, 다음에 어떻게 변할지도 예측한다. 우리 머릿속에는 현실 세계에 대한 지속적인 그림이 있고, 이를 통해 과거와 현재, 미래 사이의 연결고리를 자연스럽게 이해한다. 구글 딥마인드는 기계도 사람처럼 세상을 보도록 만들기 위해 D4RT(Dynamic 4D Reconstruction and Tracking)를 개발했다고 밝혔다.
컴퓨터에 카메라를 달아주는 것만으로는 부족하다. 평면 화면의 연속인 동영상에서 입체적이고 움직이는 실제 세계를 복원하고 이해하는 복잡한 문제를 풀어야 한다. D4RT는 움직이는 장면을 재구성하는 여러 기능을 하나의 효율적인 시스템으로 통합했다. 이는 AI가 우리가 사는 역동적인 현실을 완전히 인식하는 다음 단계로 나아가는 데 도움을 준다.
공간과 시간을 넘나드는 픽셀 하나하나를 추적하는 기술
AI가 2D 동영상에 담긴 움직이는 장면을 이해하려면, 화면 속 모든 물체의 모든 점이 입체 공간과 시간의 흐름 속에서 어떻게 이동하는지 추적해야 한다. 게다가 이런 움직임을 카메라가 움직이는 것과 구별해야 하고, 물체가 다른 물체에 가려지거나 화면 밖으로 나가도 계속 추적할 수 있어야 한다.
지금까지는 2D 동영상에서 이런 수준의 공간 구조와 움직임을 파악하려면 엄청난 계산이 필요했다. 또는 깊이를 보는 AI, 움직임을 보는 AI, 카메라 각도를 파악하는 AI 등 여러 전문 모델을 조합해야 했다. 그 결과 AI가 만든 입체 영상은 느리고 조각조각 나뉘어 있었다. 하지만 D4RT의 단순화된 구조와 새로운 질문 방식은 이전 방법보다 최대 300배 더 효율적이면서도 최고 수준의 성능을 보인다. 이는 로봇이나 증강현실처럼 즉각 반응이 필요한 분야에 충분히 빠른 속도다.
필요한 것만 물어보는 똑똑한 질문 방식
D4RT는 통합된 처리 구조로 작동한다. 먼저 입력된 동영상을 장면의 공간 구조와 움직임을 압축한 형태로 바꾼다. 여러 작업에 각각 다른 부품을 사용하던 기존 방식과 달리, D4RT는 유연한 질문 방식을 통해 필요한 것만 계산한다. 이 방식은 하나의 핵심 질문을 중심으로 작동한다. “동영상의 특정 점이 특정 시간에, 특정 카메라 시점에서 입체 공간의 어디에 있는가?”
가벼운 답변 생성기가 이 정보를 활용해 제기된 질문의 구체적인 사례에 답한다. 질문들은 서로 독립적이기 때문에 최신 AI 하드웨어에서 동시에 처리될 수 있다. 이것이 D4RT가 몇 개의 점만 추적하든 전체 장면을 재구성하든 매우 빠르고 확장 가능한 이유다. D4RT는 동영상 전체를 깊이 있게 이해하는 강력한 분석기와, 수천 개의 질문에 동시에 답하는 가벼운 답변 생성기를 결합했다. 특정 질문을 던짐으로써, 즉 원본 화면의 점이 목표 시간과 카메라 시점에서 어디에 있는지 찾아냄으로써, 하나의 유연한 방식으로 추적, 깊이 파악, 카메라 위치 파악 같은 다양한 작업을 효율적으로 해결한다.
이런 유연한 방식 덕분에 다양한 작업을 해결할 수 있다. 점 추적(Point Tracking)은 화면의 한 점이 다른 시간에 어디 있는지 물어봄으로써 D4RT가 입체 궤적을 예측할 수 있다. 중요한 점은 물체가 동영상의 다른 장면에 보이지 않아도 모델이 예측할 수 있다는 것이다. 점 구름 재구성(Point Cloud Reconstruction)은 시간과 카메라 시점을 고정해 D4RT가 장면의 완전한 입체 구조를 직접 만들어낼 수 있으며, 별도의 카메라 위치 계산이나 동영상별 반복 작업 같은 추가 단계가 필요 없다. 카메라 위치 파악(Camera Pose Estimation)은 다른 시점에서 한 순간의 입체 스냅샷을 만들고 정렬해 D4RT가 카메라의 이동 경로를 쉽게 복원할 수 있다.
1분짜리 동영상을 단 5초 만에 입체로 변환
기술 보고서에 자세히 설명된 것처럼, D4RT는 광범위한 작업에서 이전 방법들을 뛰어넘는다. 비교 결과를 보면 다른 방법들이 움직이는 물체를 다루는 데 어려움을 겪으며 종종 물체를 중복으로 만들거나 재구성에 완전히 실패하는 반면, D4RT는 움직이는 세계를 견고하고 지속적으로 이해한다.
결정적으로 D4RT의 정확도는 속도를 포기하지 않고 달성되었다. 테스트에서 이전 최고 기술보다 18배에서 300배 빠르게 작동했다. 예를 들어, D4RT는 1분짜리 동영상을 단일 TPU 칩(구글의 AI 전용 반도체)에서 약 5초 만에 처리했다. 이전의 최고 방법은 같은 작업에 최대 10분이 걸렸는데, 이는 120배의 개선이다.
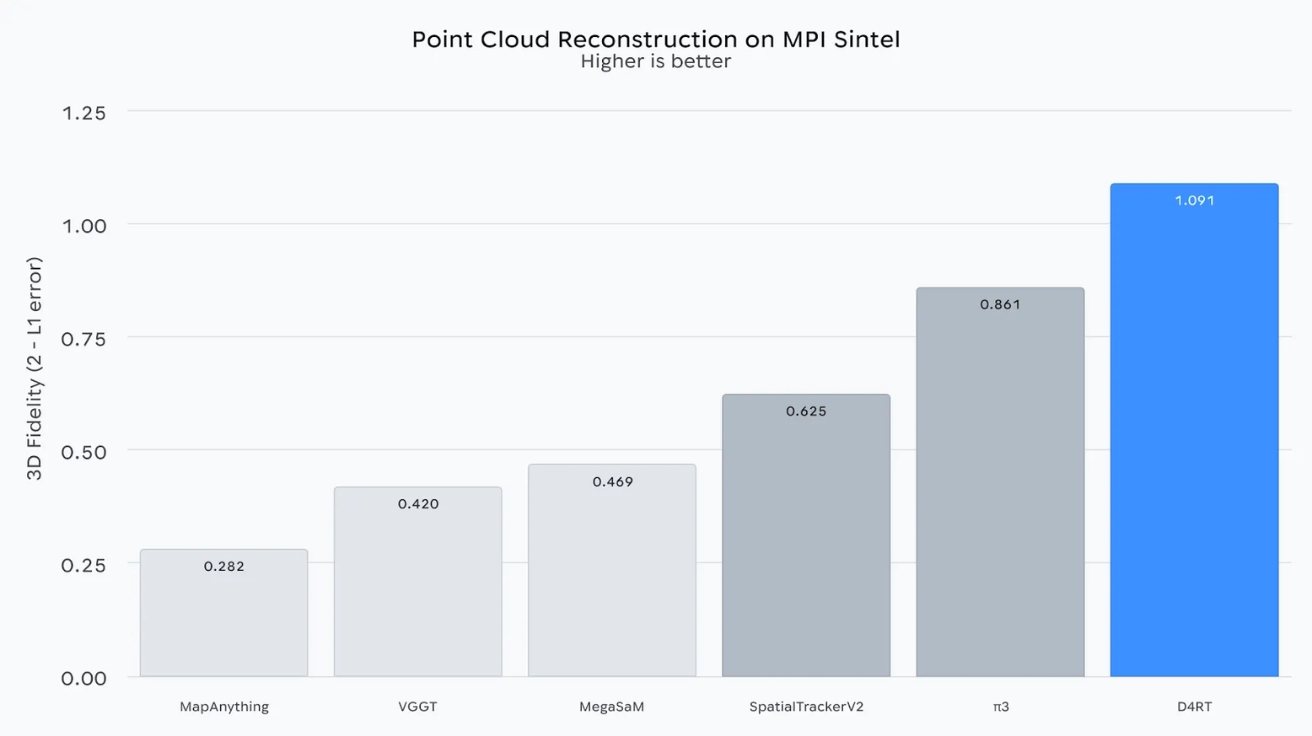
빠른 움직임으로 화면이 흐려지고 물체가 변형되는 복잡한 가상 장면을 특징으로 하는 MPI Sintel 평가에서, D4RT는 최근의 강력한 기준 모델들보다 우수한 정확도를 보여준다. 이는 물체나 카메라가 장면을 빠르게 이동할 때에도 모델이 공간 구조를 정확하게 재구성하는 능력을 보여준다. 평가 결과에 따르면 D4RT는 입체 정확도 측정에서 1.091을 기록했고, 기존 방법들인 MapAnything(0.282), VGGT(0.420), MegaSaM(0.469), SpatialTrackerV2(0.625), rl3(0.861)를 크게 앞섰다.
로봇의 눈과 AR 안경의 핵심 기술로 활용
D4RT는 정확성과 속도 사이에서 선택할 필요가 없음을 보여준다. 유연한 질문 기반 시스템은 우리의 역동적인 세상을 실시간으로 포착할 수 있어, 차세대 공간 인식 기술의 길을 열어준다.
로봇 분야에서 로봇은 움직이는 사람과 물체로 가득한 환경을 탐색해야 한다. D4RT는 안전하게 이동하고 정교한 작업을 수행하는 데 필요한 공간 인식 능력을 제공할 수 있다. 증강현실(AR) 분야에서는 AR 안경이 실제 세계 위에 가상 물체를 겹쳐 보여주려면 장면의 공간 구조를 즉각적이고 빠르게 이해해야 한다. D4RT의 효율성은 안경이나 스마트폰 같은 기기에 직접 탑재하는 것을 현실로 만드는 데 기여한다.
세계 모델(World Models) 측면에서 D4RT는 카메라 움직임, 물체 움직임, 고정된 공간 구조를 효과적으로 분리함으로써 물리적 현실에 대한 진정한 “세계 이해”를 가진 AI에 한 걸음 더 가까워진다. 이는 범용 인공지능(AGI)으로 가는 길에서 필요한 단계다.
여러 AI를 하나로, 빠르고 정확한 비전 AI 시대
D4RT의 등장은 컴퓨터 비전 AI 개발 방향에 중요한 의미를 제공한다.
첫째, 여러 전문 모델에서 하나의 통합 시스템으로의 전환이다. 기존에는 깊이 파악, 물체 추적, 카메라 위치 파악 등을 위해 각각 다른 모델이 필요했지만, D4RT는 하나의 질문 방식으로 이 모든 작업을 해결한다. 이는 AI 시스템을 단순하게 만들고 관리를 쉽게 하면서도 성능은 높이는 새로운 방법을 제시한다.
둘째, 빠른 속도와 높은 성능을 동시에 달성할 수 있음을 증명했다. 이전까지 높은 정확도를 얻으려면 막대한 계산 자원과 시간을 투입해야 했지만, D4RT는 오히려 300배 빠른 속도로 더 나은 결과를 만든다. 이는 즉각 반응이 필요한 분야의 문턱을 크게 낮추어, AR 안경이나 자율주행 로봇 같은 휴대용 기기에서도 고성능 공간 이해가 가능해졌음을 의미한다.
셋째, 물리적 세계를 이해하는 AI의 발전이 범용 AI 실현에 필수적임을 재확인시킨다. D4RT가 공간과 시간, 움직임을 통합적으로 이해하는 능력은 인간의 인지 방식에 한 걸음 더 가까워진 것이다. 특히 카메라 움직임과 물체 움직임, 고정된 공간 구조를 분리하는 능력은 진정한 세계 이해를 만드는 데 핵심적이다. 이는 단순히 이미지를 알아보는 수준을 넘어, 세상이 어떻게 작동하는지 이해하는 AI로의 진화를 의미한다.
넷째, 산업 활용 가능성이 급격히 확대되었다. 실시간 처리가 가능해지면서 제조업 로봇의 정밀 작업, 의료 수술 로봇의 실시간 공간 인식, 스포츠 분석, 영화 제작의 동작 포착 등 다양한 분야에서 즉각 활용이 기대된다. 특히 메타와 애플 등이 주력하고 있는 공간 인식 기술 시장에서 D4RT와 같은 기술은 경쟁의 핵심 요소가 될 것이다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. D4RT가 기존 입체 재구성 기술과 다른 점은 무엇인가요?
A. D4RT는 기존의 입체 재구성을 넘어 시간의 흐름까지 고려합니다. 일반적인 입체 재구성은 멈춘 순간의 공간 정보만 파악하지만, D4RT는 물체가 시간에 따라 어떻게 움직이는지까지 추적하고 예측할 수 있습니다. 또한 깊이, 추적, 카메라 각도 등을 위해 여러 개의 전문 모델이 필요했던 기존 방식과 달리, D4RT는 하나의 통합 모델로 모든 작업을 처리합니다.
Q2. D4RT 기술은 실생활에서 어떻게 활용될 수 있나요?
A. D4RT는 증강현실(AR) 안경이 실제 공간에 가상 물체를 정확하게 배치하는 데 사용될 수 있습니다. 또한 로봇이 사람과 장애물을 피하며 안전하게 이동하거나 정밀한 작업을 수행하는 데 필요한 공간 인식 능력을 제공합니다. 자율주행차의 주변 환경 이해, 스포츠 경기 분석, 영화 특수효과 제작 등에도 활용될 수 있습니다.
Q3. D4RT가 이전 기술보다 300배 빠른 이유는 무엇인가요?
A. D4RT는 질문 기반 방식을 사용하여 필요한 정보만 계산하고, 이러한 질문들을 동시에 처리할 수 있기 때문입니다. 기존 방법들이 동영상마다 반복적인 작업 과정을 거쳐야 했던 반면, D4RT는 하나의 통합 구조로 한 번의 처리로 필요한 모든 정보를 추출합니다. 또한 최신 AI 하드웨어의 동시 처리 능력을 최대한 활용하도록 설계되었습니다.
기사에 인용된 리포트 원문은 Google DeepMind에서 확인 가능하다.
리포트명: D4RT: Teaching AI to see the world in four dimensions
이미지 출처: 구글 딥마인드
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





