
어도비 리서치(Adobe Research)와 한국 카이스트(KAIST) 연구진이 비디오 AI의 고질적 문제를 해결했다. 해당 논문에 따르면, 기존 비디오 편집 AI는 한 번 편집하는 데는 뛰어났지만, 실제 작업처럼 여러 번 수정하면 앞뒤가 안 맞는 결과물이 나왔다. 이번에 나온 ‘Memory-V2V’는 이전 편집 내용을 기억해서 몇 번을 다시 만들어도 일관된 영상을 만들어낸다. 비디오 AI가 드디어 ‘기억력’을 갖게 된 셈이다.
한 번은 잘하는데 두 번째부터 문제… 기존 AI의 치명적 약점
요즘 나오는 비디오 생성 AI들은 정말 대단하다. 텍스트만 입력하면 영상을 만들고, 원하는 대로 배경을 바꾸고, 카메라 각도도 조절할 수 있다. 문제는 실제 작업 환경에서 나타난다. 영상 제작자들은 한 번에 완성하지 않는다. 결과를 보고 수정하고, 또 보고 또 수정한다. 이렇게 여러 차례 편집하는 과정에서 기존 AI들은 이전에 뭘 했는지 기억하지 못한다.
구체적인 예를 들어보자. 최신 비디오 AI인 ReCamMaster는 한 영상을 여러 각도에서 다시 만들어낸다. 하지만 첫 번째 편집에서 만든 배경과 두 번째 편집에서 만든 배경이 서로 다르게 나온다. 같은 장면인데 색깔이나 모양이 달라지는 것이다. 긴 영상을 여러 조각으로 나눠서 편집할 때도 마찬가지다. 각 조각은 잘 만들어지지만, 이어 붙이면 앞뒤가 안 맞는다. 연구진은 이 문제를 처음으로 정의하고 해결책을 내놨다.
세 가지 방식 비교해서 가장 좋은 ‘기억 저장법’ 찾아냈다
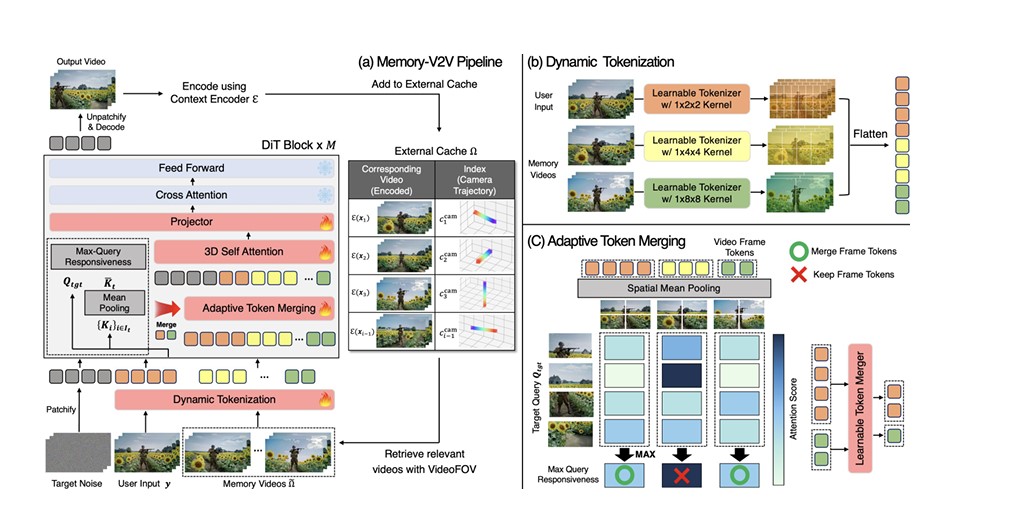
Memory-V2V의 핵심은 말 그대로 ‘기억(Memory)’이다. 이전에 만든 영상을 저장해뒀다가 나중에 참고하는 방식이다. 연구진은 먼저 “어떻게 저장할까?”를 고민했다. 3D로 재구성하는 방법(CUT3R), 새로운 시점을 만드는 네트워크(LVSM), 그리고 일반적인 비디오 압축 방식(VAE) 등 세 가지를 비교했다. 결과는 VAE가 가장 좋았다. 화질도 잘 유지하면서 처리 속도도 빠른 것으로 나타났다.
하지만 과거에 만든 모든 영상을 다 저장하고 참고하는 건 비효율적이다. 쓸데없는 정보가 많으면 오히려 결과가 나빠질 수 있다. 그래서 Memory-V2V는 ‘필요한 것만 꺼내 쓰는’ 방식을 채택했다. 카메라 각도를 바꾸는 작업에서는 ‘VideoFOV’라는 알고리즘으로 카메라 시야가 겹치는 부분을 계산해 관련 있는 과거 영상만 가져온다. 긴 영상 편집에서는 장면이 비슷한 부분끼리 찾아서 참고한다.
가져온 영상도 중요도에 따라 다르게 처리한다. 가장 중요한 영상은 세밀하게 분석하고, 덜 중요한 건 대충 봐도 되니까 정보를 압축한다. 구체적으로 사용자가 넣은 원본 영상은 1×2×2 비율로, 관련성 높은 상위 3개 영상은 1×4×4 비율로, 나머지는 1×8×8 비율로 압축한다. 여기에 ‘중요하지 않은 부분은 더 압축하는’ 기술까지 더해서 처리 속도를 약 30% 끌어올렸다. 기억력이 생겼는데 속도까지 빨라진 것이다.
기존 AI보다 23% 더 일관되고, 화질과 정확도도 개선
연구진은 두 가지 작업으로 성능을 확인했다.
첫 번째는 ‘시점 바꾸기’다. 한 영상을 여러 각도에서 다시 만드는 작업이다. 40개 영상으로 테스트한 결과, Memory-V2V는 일관성 점수(MEt3R)에서 0.1357을 기록했다. 기존 모델들(0.1485~0.1892)보다 훨씬 좋은 성적이다. 특히 첫 번째와 세 번째 편집 사이 일관성(0.1525)은 기존 대비 23% 이상 개선됐다. 카메라 각도 정확도도 높아져서 회전 오차는 1.65도, 위치 이동 오차는 13.47로 모두 1등을 차지했다.
두 번째는 ‘긴 영상 편집’이다. 200프레임 이상 되는 긴 영상 50개를 텍스트 지시에 따라 편집했다. 예를 들어 “파란 재킷을 빨간색으로 바꿔”라는 지시를 주면, Memory-V2V는 영상 전체에서 재킷을 똑같은 빨간색으로 일관되게 바꿨다. 반면 기존 AI는 앞부분과 뒷부분의 빨간색이 달랐다. 수치로도 확인됐다. 피사체 일관성 점수는 0.9326으로 기존(0.8683)보다 7% 높았고, 배경 일관성도 0.9233으로 개선됐다. 화질 점수(DINO-F)는 0.8019로 기존(0.6856) 대비 17% 높아졌다.

‘일회용’ 아닌 ‘실전용’ AI로 진화… 다만 장면 전환 많은 영상은 과제
Memory-V2V의 등장은 비디오 AI가 실제 제작 현장에 한 발짝 더 다가갔다는 의미다. 지금까지는 ‘한 번 잘 만드는’ 수준이었다면, 이제는 ‘여러 번 수정해도 일관되게 만드는’ 단계로 올라섰다. 영화나 광고, 게임 제작처럼 반복 작업이 많은 분야에서 특히 유용할 것으로 보인다. 필요한 정보만 골라서 압축하는 방식 덕분에 컴퓨터 부담도 줄었다.
물론 한계도 있다. 학습에 사용한 데이터가 장면 전환 없이 쭉 이어지는 영상들이라서, 영화처럼 장면이 자주 바뀌는 영상에서는 문제가 생긴다. 예를 들어 A장면의 소품이 전혀 다른 B장면에 갑자기 나타나는 식이다. 또 과거 영상을 만들 때 생긴 작은 오류(깜빡임, 색 변화 등)가 쌓이면서 긴 영상에서 점점 어긋나는 현상도 있다. 연구진은 앞으로 장면 전환이 많은 데이터와 더 깨끗한 긴 영상 데이터로 학습하면 이 문제를 해결할 수 있을 것으로 보고 있다.
향후 더 빠르게 만드는 기술이나 자동으로 이어서 만드는 방식과 결합하면 더 발전할 것으로 기대된다. 이번 연구의 가장 큰 의미는 ‘단순히 좋은 영상’을 넘어 ‘계속 일관되게 좋은 영상’을 만드는 새로운 기준을 제시했다는 점이다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. Memory-V2V가 기존 비디오 AI와 다른 점은 무엇인가요?
A. 기존 AI는 한 번 편집하면 끝이지만, Memory-V2V는 이전 작업을 기억해서 여러 번 편집해도 앞뒤가 맞는 영상을 만듭니다. 긴 영상을 여러 조각으로 나눠 편집해도 이어 붙였을 때 자연스럽습니다.
Q2. 기억 기능이 있으면 처리 속도가 느려지지 않나요?
A. 오히려 30% 빨라졌습니다. 중요한 과거 작업만 골라서 참고하고, 덜 중요한 부분은 압축해서 처리하기 때문입니다.
Q3. 어떤 작업에 쓸 수 있나요?
A. 영상을 다른 각도에서 다시 만들거나, 긴 영상에서 색깔이나 물체를 바꾸는 작업 등에 사용할 수 있습니다. 특히 여러 번 수정이 필요한 전문 영상 제작에 유용합니다.
기사에 인용된 리포트 원문은 arXiv에서 확인 가능하다.
리포트명: Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





