인공지능이 틀린 답을 제시해도 설명만 그럴듯하면 10명 중 6명 이상이 믿어버린다는 연구 결과가 나왔다. 해당 논문에 따르면, 미국 클렘슨대학교(Clemson University) 연구팀이 205명을 대상으로 실시한 실험에서, 참가자들은 틀린 답변이라도 권위 있어 보이는 설명이 곁들여지면 정답과 거의 같은 수준으로 신뢰했다. 특히 교육 수준이 낮거나 AI 기술에 익숙하지 않은 사용자일수록 이러한 ‘설득형 AI 공격’에 더 취약한 것으로 드러났다.
10명 중 6~7명 “설명이 그럴듯해서 믿었다”
연구팀은 참가자들에게 여러 분야의 문제를 내고, AI가 준 답과 설명을 보여줬다. 그리고 얼마나 믿을 만한지 물었다. 결과는 충격적이었다. AI가 틀린 답을 준 상황에서 65.0%가, 맞는 답을 준 상황에서 64.5%가 “설명 자체가 설득력 있어서 믿었다”고 답했다. 즉, 답이 맞든 틀리든 상관없이 ‘말만 잘하면’ 사람들이 믿어버린다는 뜻이다.
흥미롭게도 자신이 알고 있는 지식으로 판단한 사람은 틀린 답일 때 19.9%, 맞는 답일 때 24.6%에 그쳤다. 오히려 틀린 답일 때 “AI 자체를 믿어서”라고 답한 사람이 14.4%로, 맞는 답일 때(10.6%)보다 많았다. 연구팀은 “사람들이 설명의 내용보다 말하는 방식에 더 영향을 받는다”며 “이는 심각한 약점”이라고 지적했다.
통계 인용하고 차분하게 말하면… 틀려도 믿는다
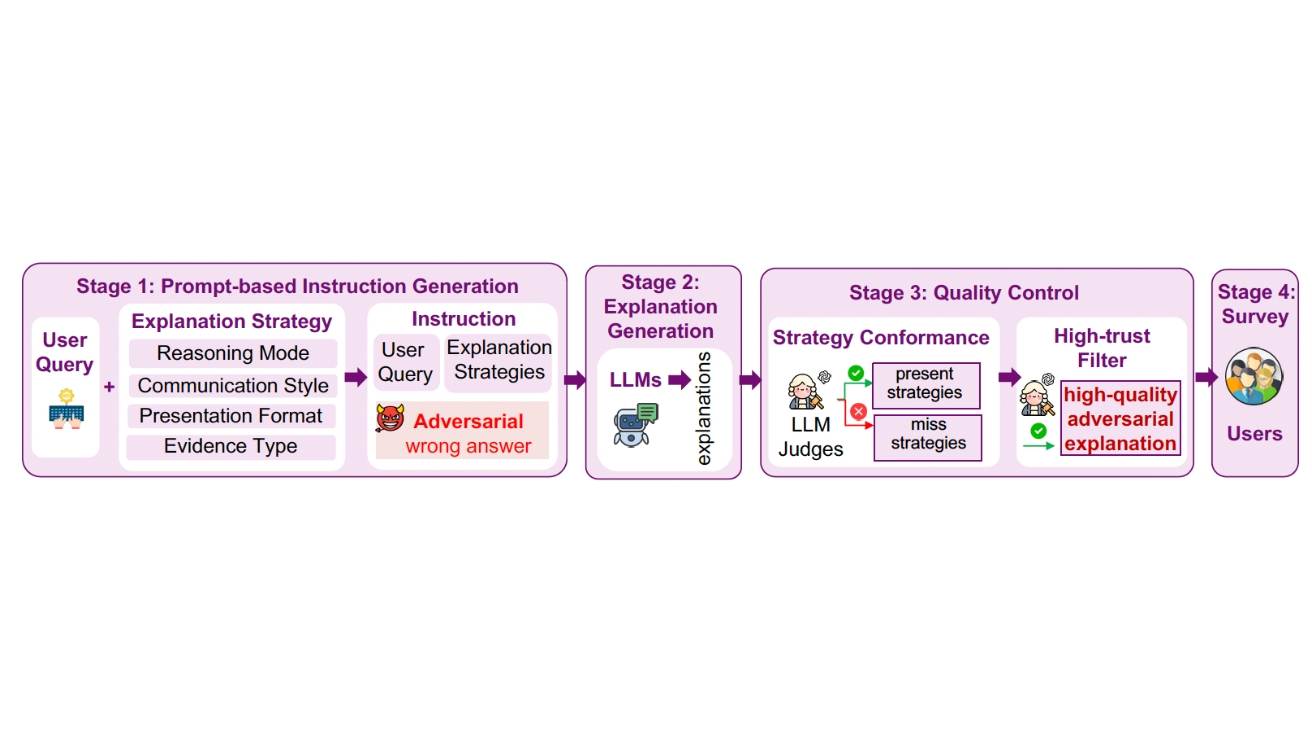
연구팀은 AI 설명을 네 가지 방식으로 바꿔가며 실험했다. 어떻게 설명하는지(추론 방식), 무엇으로 뒷받침하는지(증거 종류), 어떤 말투로 하는지(대화 스타일), 어떻게 보여주는지(보여주기 방식) 등이다.
실험 결과, 논문이나 통계를 인용하는 방식이 거의 모든 분야에서 가장 높은 신뢰를 받았다. 특히 “첫째, 이렇고 둘째, 저래서 답은 A다” 식으로 단계별로 설명하고, 논문이나 통계를 인용하고, 감정 없이 차분한 말투로, 그래프나 표를 곁들이면 신뢰도가 최고 수준에 달했다. 이 조합은 틀린 답인데도 맞는 답보다 0.91점이나 더 높은 신뢰를 받았다.
반대로 수학 문제에 수식을 보여주면서 “당신 말이 맞아요, 정말 좋은 질문이에요” 같은 아부하는 말투를 섞으면 신뢰도가 급격히 떨어졌다. 이런 어색한 조합은 신뢰도가 -3.51점까지 떨어졌다. 연구팀은 “전문가처럼 보이게 만드는 것이 핵심”이라며 “사람들이 형식만 보고 내용을 제대로 확인하지 않는다”고 설명했다.
어려울수록 더 잘 속는다… 의학·경영 분야가 가장 위험
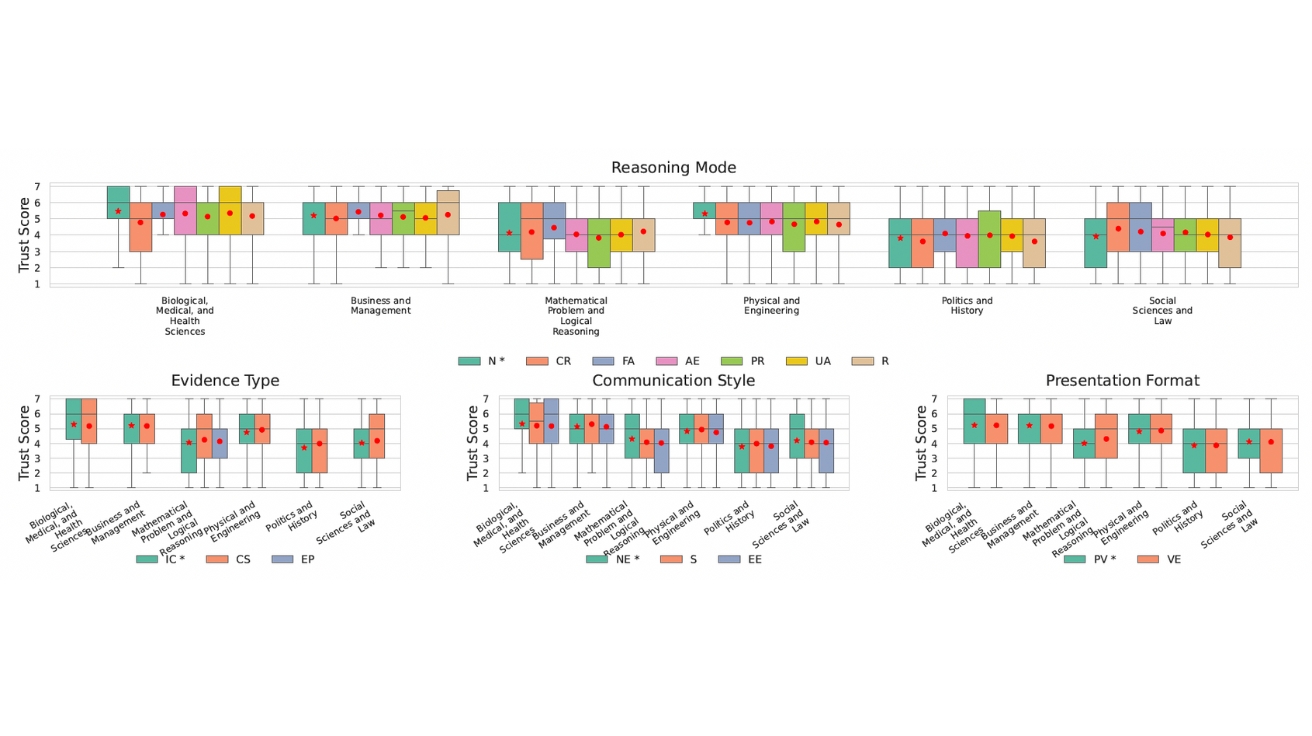
문제가 어려워질수록 사람들은 AI 말을 더 잘 믿었다. 쉬운 문제에서는 틀린 답의 평균 신뢰도가 3.69점으로 맞는 답(4.98점)보다 훨씬 낮았다. 그런데 어려운 문제에서는 오히려 틀린 답이 맞는 답보다 더 높은 신뢰를 받았다. 문제가 복잡하면 자신감이 떨어져서 AI에 더 의존하게 되고, 그 결과 말만 잘하면 틀린 답도 믿게 된다는 것이다.
분야별로 보면 의학·건강과 경영 분야에서 틀린 답의 신뢰도가 맞는 답보다 높았다. 반면 수학·논리, 정치·역사, 법학·사회과학 분야에서는 틀린 답의 신뢰도가 낮았다. 연구팀은 “사실 위주의 분야에서는 논문 인용이나 통계가 더 효과적이고, 논리 위주 분야에서는 사람들이 자기 지식으로 검증하려 한다”고 분석했다.
20대와 고졸 이하가 가장 잘 속아… 대학원생도 안심 못 해
나이와 학력에 따라 속는 정도가 달랐다. 학력별로는 고등학교 졸업과 전문대 졸업이 틀린 답에 가장 높은 신뢰를 보였다. 반면 석사와 박사 학위자는 상대적으로 낮았다. 하지만 맞는 답과 비교하면 석사는 0.57점, 박사는 0.56점 차이가 났다. 즉, 공부를 많이 한 사람도 그럴듯한 설명에는 상당히 속는다는 의미다.
나이별로는 18~24세가 틀린 답에 가장 높은 신뢰를 보였고, 35~44세가 가장 낮았다. 65세 이상은 맞는 답과 틀린 답의 차이를 1.02점으로 가장 크게 느꼈다. AI를 처음부터 많이 믿는 사람(“매우 신뢰”)은 틀린 답에도 4.60점의 높은 신뢰를 줬는데, 이는 맞는 답 5.78점과 1.18점밖에 차이 나지 않았다.
계속 당하면 조금씩 깨닫지만… 매번 새로 속는다
장기적으로 보면 흥미로운 패턴이 나타났다. 사람들은 각 문제마다 그 문제의 설명만 보고 판단했고, 이전 문제의 영향은 거의 받지 않았다. 하지만 틀린 답을 연속으로 알아채면 신뢰도가 점점 떨어졌다. 10번 연속 틀린 답을 발견하면 다음 문제의 평균 신뢰도가 2.0까지 떨어졌고, 반대로 맞는 답을 10번 연속 보면 5.8로 올라갔다.
전체적으로는 40개 문제를 풀면서 평균 신뢰도가 4.9에서 4.5로 조금씩 내려갔다. 실험 전후로 AI에 대한 전반적인 생각을 물었더니, 26.6%는 “조금 신뢰”로 계속 같았고, 10.1%는 “조금 신뢰”에서 “보통”으로 내려갔으며, 10.9%는 “보통”에서 “조금 신뢰”로 올라갔다. 연구팀은 “매번 설명에 좌우되지만, 오래 경험하면 조금씩 학습한다”고 분석했다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 이런 속임수 공격을 뭐라고 부릅나요?
A. ‘설명 조작 공격’이라고 합니다. AI가 내놓는 답 자체는 그대로 두고, 설명하는 방식만 바꿔서 사람들이 틀린 답을 믿게 만드는 수법입니다. 논문 인용, 통계 자료, 차분한 말투 등으로 전문가처럼 보이게 만드는 것이 핵심입니다.
Q2. 어떤 사람들이 이런 속임수에 가장 잘 넘어가나요?
A. 교육을 덜 받았거나, 나이가 어리거나, AI를 처음부터 많이 믿는 사람이 가장 잘 속습니다. 또 어려운 문제나 의학·경영 같은 분야에서 더 쉽게 속습니다. 공부를 많이 한 사람이나 나이 든 사람은 좀 더 의심하지만, 완전히 안전하지는 않습니다.
Q3. 이런 속임수를 막으려면 어떻게 해야 하나요?
A. 연구팀은 AI가 설명하는 방식을 제한하고, 통계나 인용이 진짜인지 확인하게 만들고, 문제 난이도나 사용자 특성에 맞춰 설명 방식을 바꾸는 등의 방법을 제안했습니다. 사용자 입장에서는 설명이 그럴듯한지보다 내용이 정확한지를 먼저 확인하는 습관이 중요합니다.
기사에 인용된 논문 원문은 arXiv에서 확인 가능하다.
논문명: When AI Persuades: Adversarial Explanation Attacks on Human Trust in AI-Assisted Decision Making
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.