대형 언어모델(LLM)이 학술 연구에 널리 활용되면서, 존재하지 않는 논문을 인용하는 ‘유령 인용(ghost citation)’ 문제가 심각한 수준으로 드러났다. 난카이대(Nankai University)와 칭화대(Tsinghua University) 공동 연구팀이 개발한 CITEVERIFIER 시스템을 통해 분석한 결과, 최신 AI 모델들이 생성한 학술 인용의 14%에서 최대 95%까지 실제로 존재하지 않는 허위 참고문헌인 것으로 확인됐다.
GPT-5는 51%, 클로드4는 22%… 모델별 환각 인용률 편차 최대 6.7배
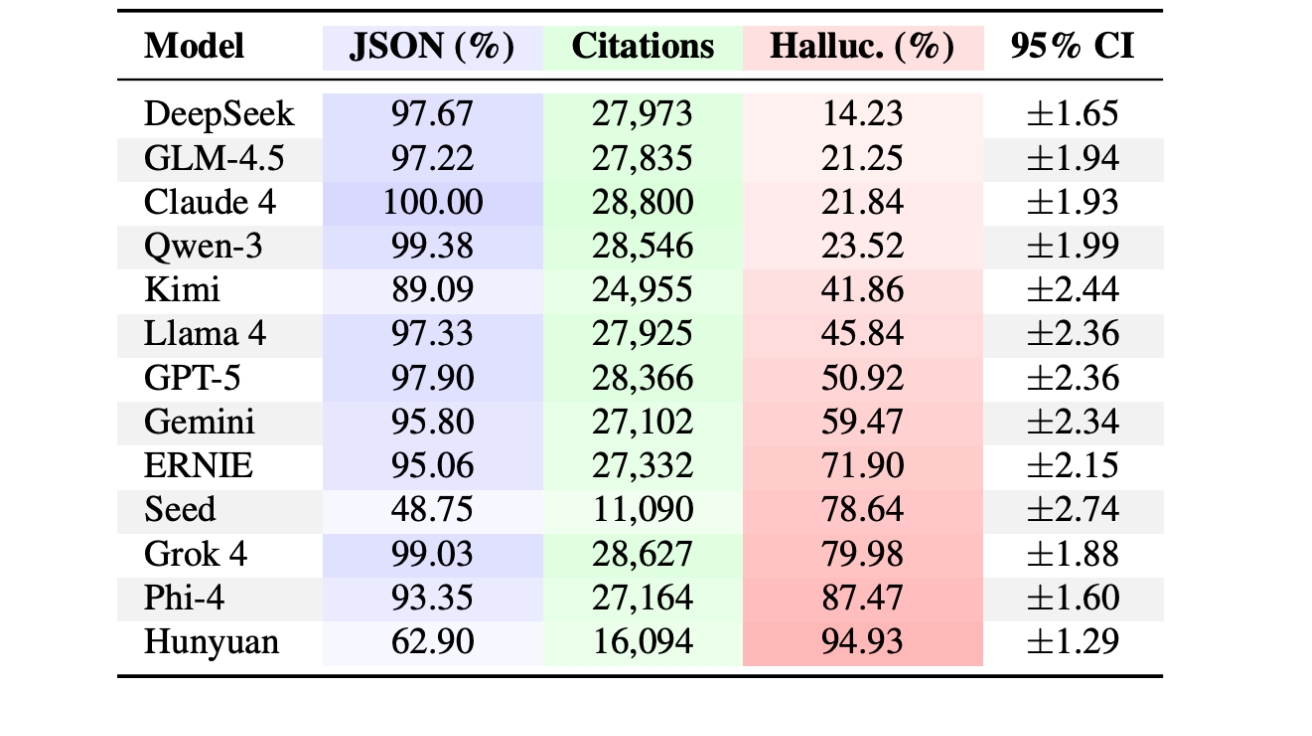
연구팀은 GPT-5, 클로드4, 제미나이 등 13개 최신 LLM을 대상으로 컴퓨터 과학 40개 연구 분야에서 37만 5,440개의 인용을 생성하도록 한 뒤 진위를 검증했다. 그 결과 모든 모델이 허위 인용을 생성했으며, 환각 인용률은 딥시크의 14.23%부터 훈위안(Hunyuan)의 94.93%까지 약 6.7배 차이를 보였다. 특히 주목할 점은 GPT-5가 50.92%, 클로드4가 21.84%의 환각률을 기록해 최신 프리미엄 모델조차 신뢰할 수 없다는 사실이 입증됐다는 점이다.
환각 인용의 패턴도 흥미롭다. AI 모델들은 실제 저자 이름, 그럴듯한 제목, 유명 학회명을 통계적으로 조합해 겉보기에는 완벽해 보이지만 실제로는 존재하지 않는 참고문헌을 만들어낸다. 2000년부터 2025년까지 생성된 인용을 분석한 결과, 최근 연도로 갈수록 환각 인용률이 급격히 증가해 2025년에는 98.75%에 달했다. 이는 LLM이 최신 논문을 선호적으로 환각 한다는 것을 의미한다.
2025년 학술 논문, 전년 대비 80.9% 급증한 허위 인용 포함
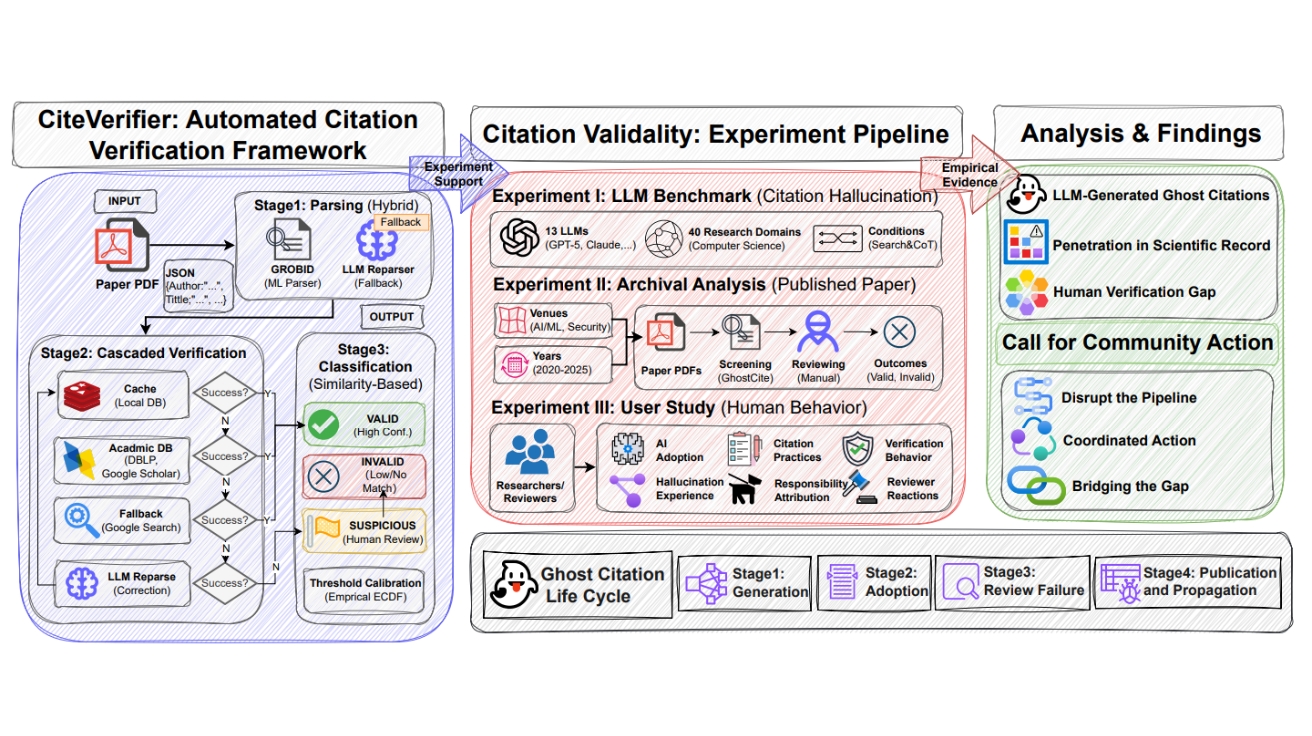
연구팀은 2020년부터 2025년까지 NeurIPS, ICML, IEEE S&P 등 최상위 AI/ML 및 보안 학회에 발표된 5만 6,381편의 논문에서 220만 개의 인용을 검증했다. 자동 검증 후 의심스러운 2,530개 인용을 16명의 연구진이 약 한 달간 수작업으로 재검증한 결과, 604편(1.07%)의 논문에서 739개의 확실한 허위 인용을 발견했다. 이 중 486편(0.86%)은 추적 불가능한 유령 인용을, 133편(0.24%)은 메타데이터 오류를 포함하고 있었다.
시간에 따른 추세는 더욱 우려스럽다. 2020년부터 2024년까지 허위 인용률은 0.76%에서 0.98% 사이로 비교적 안정적이었으나, 2025년에는 1.61%로 급등했다. 이는 2020~2024년 평균(0.89%) 대비 80.9% 증가한 수치다. 특히 AI/ML 분야 학회가 보안 학회보다 절대적 허위 인용 건수가 훨씬 많았는데, 이는 AI 연구 커뮤니티에서 LLM 기반 도구를 더 일찍, 더 광범위하게 채택했기 때문으로 분석된다.
더 심각한 것은 ‘반복되는 허위 인용’ 현상이다. 연구팀은 동일한 잘못된 인용이 최대 16편의 독립적인 논문에 반복 등장하는 것을 확인했다. 예를 들어 “AugMix” 논문의 제목 오류가 AAAI, IJCAI, NeurIPS에 걸쳐 16편의 논문에 동일하게 나타났다. 이는 연구자들이 다른 논문의 참고문헌을 복사하면서 이미 포함된 오류까지 함께 전파하고 있음을 보여준다.
연구자 87%가 AI 사용하지만, 41%는 BibTeX 검증 없이 복사
연구팀은 94명의 연구자를 대상으로 설문조사를 실시해 인간의 검증 행동을 분석했다. 응답자의 87.2%가 연구에 AI 도구를 사용한다고 답했으며, AI 사용자 중 86.7%는 “항상 검증한다”고 주장했다. 그러나 실제 행동 데이터는 달랐다. 41.5%는 BibTeX 항목을 내용 확인 없이 복사-붙여넣기하며, 17.3%는 AI가 추천한 논문을 읽지 않고 인용했다. 의심스러운 참고문헌을 발견했을 때 44.4%는 개인적으로만 확인하거나 무시하는 등 아무런 조치를 취하지 않았다.
리뷰어들의 검증도 허술하다. 설문에 응한 리뷰어 30명 중 76.7%는 참고문헌을 철저히 확인하지 않으며, 80.0%는 제출된 논문에서 허위 인용을 의심한 적이 없다고 답했다. 연구자의 74.5%는 현재 동료 심사 과정이 메타데이터 오류를 잡아내는 데 효과적이지 않다고 평가했다. 이는 저자와 리뷰어 모두 기본적으로 인용을 신뢰한다는 ‘신뢰 기반 규범(trust-by-default norm)’이 작동하고 있음을 보여준다.
흥미롭게도 연구자들은 문제의 심각성을 인지하고 있다. 76.6%가 허위 인용을 ‘중대한 문제’ 또는 ‘심각한 위기’로 여기며, 70.2%는 제출 시스템에 자동화된 DOI/참고문헌 검증 도구 도입을 강력히 지지했다. 그러나 책임 소재에 대해서는 91.5%가 저자에게 있다고 답해, 학회나 도구 개발자 등 다른 이해관계자들에 대한 압력을 오히려 감소시킬 수 있다는 우려가 제기된다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 유령 인용이란 무엇이며 왜 문제인가요?
A. 유령 인용은 AI가 생성한 실제로 존재하지 않는 허위 참고문헌입니다. 학술 논문에서 인용은 주장의 근거를 제공하는 신뢰 메커니즘인데, 존재하지 않는 논문을 인용하면 이 신뢰가 무너지고 과학적 진실이 왜곡됩니다. 연구자들이 이런 허위 인용을 추적하느라 시간을 낭비하고, 인용 그래프에 허위 정보가 쌓이면서 학술 커뮤니케이션 전체의 신뢰성이 훼손됩니다.
Q2. AI가 허위 인용을 생성하는 이유는 무엇인가요?
A. 대형 언어모델은 실제 데이터베이스를 검색하지 않고 통계적 패턴에 따라 텍스트를 생성합니다. 학술 인용은 엄격한 형식을 따르기 때문에 AI는 실제 저자명, 그럴듯한 제목, 유명 학회명 등을 조합해 겉으로는 완벽해 보이지만 실제로는 존재하지 않는 참고문헌을 쉽게 만들어냅니다. AI는 언어의 구조를 모방할 뿐 진실성은 고려하지 않기 때문입니다.
Q3. 연구자들이 허위 인용을 막기 위해 무엇을 해야 하나요?
A. AI가 생성한 모든 참고문헌을 제출 전에 반드시 검증해야 합니다. Google Scholar나 DBLP 같은 신뢰할 수 있는 데이터베이스에서 제목을 확인하고, DOI가 없거나 메타데이터가 일치하지 않으면 주의해야 합니다. BibTeX 항목을 확인 없이 복사-붙여넣기하는 습관을 피하고, 검색 기반 도구를 순수 생성 모델보다 우선적으로 사용하는 것이 좋습니다. 학회는 자동화된 인용 검증 시스템을 도입하고, AI 도구 개발자들은 검증된 출처에 기반한 검색 방식을 채택해야 합니다.
기사에 인용된 논문 원문은 arXiv에서 확인 가능하다.
논문명: GHOSTCITE: A Large-Scale Analysis of Citation Validity in the Age of Large Language Models
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.