알리바바의 큐웬(Qwen)팀이 텍스트 렌더링과 사실적 이미지 생성을 하나의 모델로 통합한 차세대 이미지 생성 AI ‘Qwen-Image-2.0’을 공개했다. 큐웬팀에 따르면, 이 모델은 최대 1천 토큰(약 750단어)에 달하는 복잡한 지시문을 이해하고, PPT 슬라이드부터 포스터, 만화까지 전문적인 인포그래픽을 직접 생성할 수 있다는 점이 특징이다. 기존 이미지 생성 AI들이 텍스트 렌더링에 어려움을 겪었던 것과 달리, Qwen-Image-2.0은 이미지 안의 글자를 정확하게 표현하면서도 사진처럼 사실적인 장면을 만들어낸다.
복잡한 PPT 슬라이드도 프롬프트 하나로 완성
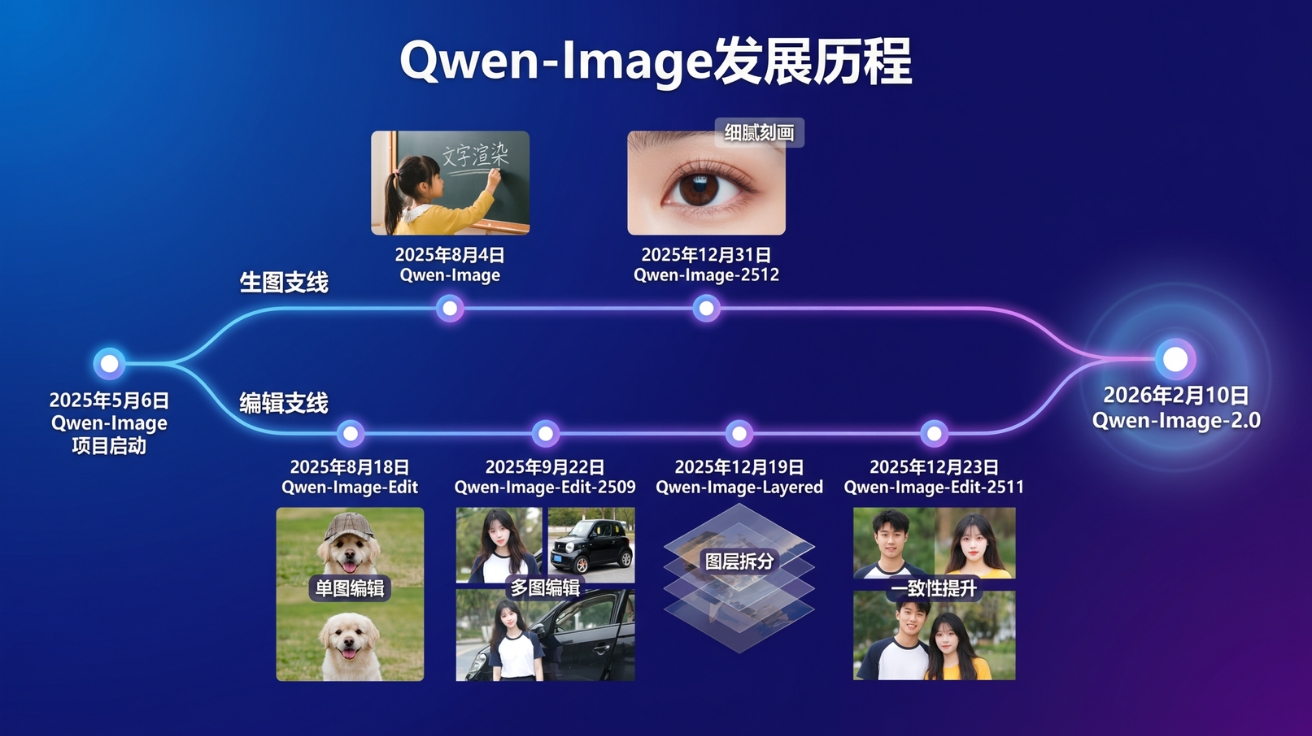
Qwen-Image-2.0의 가장 눈에 띄는 특징은 복잡한 텍스트와 이미지가 혼합된 콘텐츠를 정확하게 생성한다는 점이다. 실제로 큐웬 팀이 공개한 블로그의 이미지는 사람이 직접 만든 것이 아니라 AI가 생성한 것이다. 이 슬라이드에는 ‘Qwen-Image 발전 과정’이라는 제목 아래 시간축이 그려져 있고, 각 시점마다 작은 이미지들이 배치되어 있다. 특히 “모자를 쓴 강아지”와 “모자를 벗은 같은 강아지”처럼 복잡한 ‘그림 속 그림’ 구성도 정확하게 렌더링했다. 이는 전문적인 프레젠테이션 제작을 훨씬 쉽게 만들어준다.
모델은 1천 토큰에 달하는 긴 지시문도 처리할 수 있다. 예를 들어 A/B 테스트 결과 보고서를 요청하면, 왼쪽에는 ‘테스트 개요’, 가운데에는 ‘통계 분석’, 오른쪽에는 ‘비즈니스 영향’이라는 세 개의 섹션으로 나뉜 복잡한 인포그래픽을 생성한다. 각 섹션에는 수십 개의 텍스트 블록과 화살표, 표가 정확하게 배치된다. 이처럼 복잡한 프롬프트는 대형 언어 모델(LLM)의 도움을 받으면 쉽게 만들 수 있다. 사용자가 “항저우 2일 여행 포스터를 만들어줘”라고 간단히 요청하면, LLM이 이를 상세한 지시문으로 변환해준다.
한자 서예부터 영문 타이포그래피까지 정확한 텍스트 렌더링
Qwen-Image-2.0은 텍스트 렌더링의 ‘아름다움’도 구현했다. 중국 고전 수묵화 스타일로 송나라 시인 류융(柳永)의 시 ‘우린령(雨霖铃)’을 세로쓰기로 완벽하게 표현할 수 있다. 서예 붓글씨의 농담, 획의 강약, 먹이 번지는 효과까지 자연스럽게 재현한다. 심지어 송나라 휘종 황제의 독특한 ‘수금체(瘦金體)’ 서체나 왕희지의 소해서(小楷書) 스타일로도 글자를 쓸 수 있다. 왕희지의 ‘난정서(蘭亭序)’ 전문을 소해서로 렌더링한 예시에서는 거의 모든 글자가 정확하게 표현되었으며, 일부 글자만 완벽하지 않았다.

텍스트의 ‘사실성’도 뛰어나다. 한 예시에서는 사무실 유리 화이트보드에 마커로 쓴 글씨, 티셔츠에 프린트된 로고, 잡지 표지의 제목이 각각 다른 재질과 조명 조건에서 자연스럽게 표현된다. 유리에는 반사가 있고, 옷감에는 주름이 생기며, 모든 텍스트가 사실적인 원근감을 유지한다.

2K 해상도로 구현한 극사실주의 이미지
텍스트 렌더링뿐만 아니라 사진 같은 이미지 생성 능력도 크게 향상되었다. Qwen-Image-2.0은 기본적으로 2048×2048 픽셀의 2K 해상도를 지원한다. ‘말이 사람을 타고 있는’ 장면을 요청하면, 말의 근육과 털, 사람의 표정, 갈라진 땅의 질감까지 세밀하게 표현한다. 또 다른 예시에서는 여름 숲 장면에 23가지 이상의 서로 다른 녹색 톤을 사용했다. 떡갈나무와 너도밤나무의 짙은 먹색, 녹색, 단풍나무 새순의 밝은 비취색, 이끼의 청록색이 각각 다른 질감과 광택으로 구분되어 생태학적 사실성을 구현한다.
AI 아레나(AI Arena)에서 실시한 블라인드 테스트 결과, Qwen-Image-2.0은 텍스트-이미지 생성과 이미지-이미지 편집 두 분야 모두에서 우수한 성능을 보였다. 특히 이 모델은 생성과 편집을 하나로 통합한 ‘옴니(omni) 모델’이라는 점이 특징이다. 이전까지 큐웬 팀은 이미지 생성 트랙과 이미지 편집 트랙을 별도로 개발했지만, Qwen-Image-2.0에서는 두 기능을 하나의 모델로 합쳤다. 이는 생성 쪽의 개선사항이 자동으로 편집 기능에도 적용된다는 의미다.

이미지 편집도 한 단계 진화, 시 쓰기부터 합성까지
통합 모델의 장점은 이미지 편집에서도 드러난다. 기존 사진에 직접 시를 새겨 넣을 수 있는데, 이것이 가능한 이유는 향상된 텍스트 렌더링 능력이 편집 기능에도 그대로 적용되기 때문이다. 사용자가 아무 사진이나 업로드하고 “시를 하나 써줘”라고 요청하면, 모델이 사진 위에 자연스럽게 시를 새겨 넣는다. 사진의 사실성도 개선되어, 한 사람이 아홉 가지 다른 포즈로 찍은 것처럼 보이는 구도 사진을 자연스럽게 생성할 수 있다.
두 장의 사진을 합성하는 기능도 뛰어나다. 같은 사람이 찍힌 두 장의 서로 다른 사진을 제공하면, 두 사람이 함께 있는 것처럼 자연스러운 합성 사진을 만들어낸다. 조명 방향, 그림자, 거리감이 모두 일치하며 합성 흔적이 보이지 않는다. 현실 사진과 만화 캐릭터를 섞는 ‘차원 간 편집’도 가능하다. 실제 도시 사진에 만화 캐릭터 세 마리를 배치하되, 건물 위에 하나, 건물 옆에서 하나가 얼굴을 내밀고, 건물 앞 공터에 하나가 앉아 있는 식으로 자연스럽게 합성한다.
더 작은 모델, 더 빠른 속도로 효율성 개선
Qwen-Image-2.0은 성능 향상과 함께 효율성도 개선했다. 모델 크기가 더 작아지고 추론 속도가 빨라졌다. 구체적으로 8B(80억 파라미터) 규모의 Qwen3-VL 인코더와 7B(70억 파라미터) 규모의 확산 디코더로 구성되어 있다. 이는 2K 해상도 이미지를 몇 초 만에 생성할 수 있는 속도를 의미한다. 시각적 품질과 추론 속도 사이의 최적 균형을 찾았다는 평가다.
모델의 발전 과정을 살펴보면, 2025년 5월 프로젝트가 시작된 이후 생성 트랙에서는 Qwen-Image(8월)가 텍스트 렌더링에 집중했고, Qwen-Image-2512(12월)가 사실성을 강화했다. 편집 트랙에서는 Qwen-Image-Edit(8월)이 단일 이미지 편집을, Qwen-Image-Edit-2509(9월)가 다중 이미지 편집을, Qwen-Image-Edit-2511(12월)가 일관성 개선을 다뤘다. Qwen-Image-2.0은 이 두 트랙을 성공적으로 통합한 결과물이다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. Qwen-Image-2.0으로 PPT를 만들 수 있나요?
A. 네, 가능합니다. Qwen-Image-2.0은 최대 1천 토큰에 달하는 복잡한 지시문을 이해하고 전문적인 PPT 슬라이드를 직접 생성할 수 있습니다. 제목, 본문, 이미지, 표, 화살표 등이 포함된 복잡한 레이아웃도 정확하게 렌더링합니다. 사용자가 간단한 요청만 하면 대형 언어 모델이 상세한 프롬프트로 변환해주므로 실제 사용도 어렵지 않습니다.
Q2. 기존 AI 이미지 생성 모델과 무엇이 다른가요?
A. 가장 큰 차이는 텍스트 렌더링의 정확성입니다. 기존 이미지 생성 AI들은 이미지 안의 글자를 제대로 표현하지 못하는 경우가 많았습니다. Qwen-Image-2.0은 한자 서예부터 영문 타이포그래피까지 정확하게 렌더링하며, 2K 해상도의 사실적인 이미지도 생성합니다. 또한 이미지 생성과 편집 기능을 하나의 모델로 통합해 일관된 성능을 제공한다는 점도 차별점입니다.
Q3. 일반 사용자도 쉽게 사용할 수 있나요?
A. 복잡한 프롬프트가 필요해 보이지만, 실제로는 대형 언어 모델의 도움으로 간단하게 사용할 수 있습니다. 예를 들어 “항저우 여행 포스터 만들어줘”처럼 간단히 요청하면, 언어 모델이 이를 상세한 지시문으로 변환합니다. 또한 기존 사진에 시를 새겨 넣거나, 여러 사진을 자연스럽게 합성하는 등의 편집 작업도 직관적으로 수행할 수 있습니다.
기사에 인용된 리포트 원문은 큐웬 블로그에서 확인 가능하다.
리포트명: Qwen-Image-2.0: Professional infographics, exquisite photorealism
이미지 출처: 큐웬
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.