AI 모델을 학습시키는 데 필요한 시간과 비용을 획기적으로 줄일 수 있는 기술이 나왔다. 해당 리포트에 따르면, AI 학습 도구 개발사 언슬로스(Unsloth)가 전문가 혼합형(Mixture of Experts, MOE) AI 모델의 학습 속도를 최대 12배 높이는 새로운 기술을 공개했다. 이 기술은 컴퓨터 메모리 사용량을 35% 이상 줄이면서도 AI의 성능은 그대로 유지한다는 점에서 주목받고 있다.
게임용 그래픽카드로도 200억 개 규모 AI 학습 가능
언슬로스의 새 기술을 사용하면 일반 PC용 그래픽카드로도 대형 AI 모델을 학습시킬 수 있다. 예를 들어 200억 개의 파라미터(AI가 학습하는 값)를 가진 gpt-oss-20b 모델은 12.8GB의 메모리만 있으면 학습이 가능하다. 이는 RTX 3090 같은 게임용 그래픽카드로도 충분히 가능한 수준이다.
300억 개 파라미터 규모의 큐원3-30B-A3B(Qwen3-30B-A3B) 모델도 63GB 메모리로 학습할 수 있다. 이 기술은 수천만 원대 전문 장비인 B200, H100은 물론 10년 전 나온 RTX 3090 같은 저렴한 그래픽카드에서도 작동한다. 지원하는 AI 모델은 gpt-oss, 큐원3(Qwen3), 딥시크(DeepSeek) R1, V3, GLM 시리즈 등 다양하다.
기존 방식보다 최대 30배 빠른 학습 속도 달성
언슬로스가 이런 성능을 낼 수 있는 비결은 두 가지 핵심 기술에 있다. 첫째는 ‘트리톤 커널’이라는 최적화된 계산 방식이고, 둘째는 새로운 수학 공식을 활용한 것이다. AI 개발 플랫폼 허깅페이스(Hugging Face)와 협력해 만든 이 기술은 파이토치(PyTorch)라는 AI 개발 도구의 새로운 기능을 기반으로 한다.
기존에 사용하던 트랜스포머(Transformers) v5 버전도 이전 v4 버전보다 6배 빠른 학습이 가능했다. 언슬로스는 여기에 자체 개발한 계산 방식을 더해 2배 이상 속도를 더 높였다. 결과적으로 구형 트랜스포머 v4와 비교하면 12배에서 최대 30배까지 빠른 학습이 가능해졌다.
엔비디아 A100 전문 그래픽카드에서 언슬로스의 트리톤 커널은 기본 방식보다 약 2.5배 빠르다. 학습을 시작할 때 약 2분간 자동으로 최적의 설정을 찾는 과정을 거치는데, 이를 통해 전체 학습 시간을 35% 더 단축할 수 있다. 특히 AI 모델이 클수록, 한 번에 처리하는 문장이 길수록 메모리 절약 효과가 더욱 커진다.
그래픽카드 성능에 맞춰 자동으로 최적 방식 선택
언슬로스의 핵심 혁신 중 하나는 ‘스플릿 로라(Split LoRA)’라는 방식이다. 이 방법을 사용하면 트랜스포머 v5보다 메모리를 약 35% 덜 쓰면서 학습 속도는 2배 빠르다. 구형 트랜스포머 v4와 비교하면 12배에서 30배까지 빠른 학습이 가능하다.
언슬로스는 사용자가 가진 그래픽카드 종류에 따라 자동으로 최적의 계산 방식을 선택한다. H100 이상 최신 장비에서는 ‘grouped_mm’ 방식을, A100이나 구형 장비에서는 ‘unsloth_triton’ 방식을 사용한다. 속도는 12배 느리지만 메모리 절약 효과는 그대로인 ‘native_torch’ 방식도 있다. 원한다면 사용자가 직접 계산 방식을 선택할 수도 있다.
실제 테스트로 확인된 압도적인 성능 차이
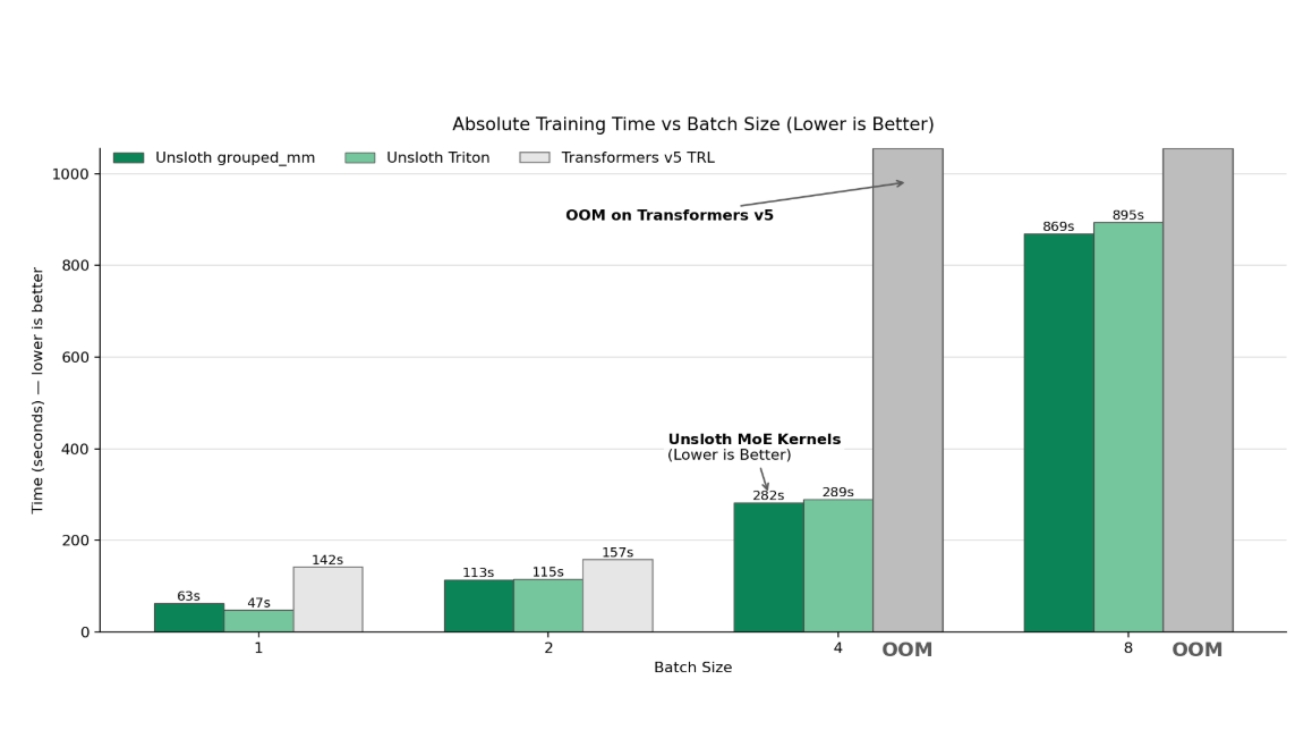
실제 성능 테스트 결과는 언슬로스의 효과를 명확히 보여준다. 엔비디아 B200 그래픽카드에서 gpt-oss 모델을 학습할 때 기존 방식보다 7배 빠르고 메모리는 36% 덜 사용했다. 큐원3-30B-A3B는 1.8배, GLM 4.7 플래시(Flash)는 RTX PRO 6000에서 2.1배 빠른 속도를 보였다.
특히 gpt-oss-20b 모델을 16,000자 분량의 문장 길이로 학습할 때, 언슬로스는 7배 빠르고 메모리는 36% 적게 사용했다. 기존 트랜스포머 v5와 TRL 방식은 메모리 부족으로 아예 실행조차 불가능했다. H100 그래픽카드에서는 최대 1.77배 빠른 학습과 약 5.3GB의 메모리 절약을 달성했다. 8,192자 길이 학습에서는 언슬로스만 정상 작동했으며, 이때 사용한 메모리가 기존 방식의 4,096자 길이 학습보다 적었다.
적은 메모리로 효율적 학습 가능하게 만드는 원리
언슬로스 기술의 핵심은 ‘로라(LoRA)’라는 효율적 학습 방식을 더욱 개선한 것이다. 로라는 AI 모델 전체를 다시 학습시키는 대신, 작은 크기의 ‘어댑터’만 학습하는 방법이다. 일반적인 레이어를 전체 학습하면 약 4,800만 개의 값을 다뤄야 하지만, 로라를 사용하면 약 100만 개만으로도 비슷한 성능을 낼 수 있다.
그런데 전문가 혼합형 모델은 여러 개의 전문가가 동시에 존재하는 구조라서 상황이 다르다. 큐원3-30B-A3B의 경우 128개의 전문가가 있고, 각 입력마다 8개의 전문가가 활성화된다. 로라를 적용하면 전문가당 약 18만 개의 추가 값이 생기는데, 이게 모든 전문가에 적용되면 메모리 사용량이 크게 늘어난다.
기존 방식은 로라로 만든 값들을 원래 AI 모델에 합친 후 계산을 실행했다. 문제는 이 과정에서 모든 전문가의 값을 동시에 메모리에 올려야 해서 메모리 소비가 컸다. 언슬로스는 수학의 결합법칙을 활용해 계산 순서를 바꿨다. 최종 결과는 똑같지만 중간 과정에서 메모리를 훨씬 덜 쓰도록 만든 것이다.
젬마-3 모델, 메모리 사용량 획기적 개선
언슬로스는 전문가 혼합형 모델 외에도 젬마-3(Gemma-3) 모델에 ‘플렉스어텐션(FlexAttention)’이라는 기술을 기본으로 적용했다. 이전에는 문장 길이가 2배 늘어나면 메모리 사용량이 4배 증가했지만, 이제는 2배만 증가한다. 학습 속도도 3배 이상 빠르며, 긴 문장일수록 효과가 더 크다. 이전 버전에서는 메모리 부족 문제가 발생했지만 지금은 해결됐다.
이 외에도 이미지와 텍스트를 섞어서 AI를 학습시킬 수 있게 되었고, 윈도우(Windows) 운영체제를 공식 지원한다. 전체 120개 학습 예제 중 80% 이상이 최신 버전과 호환되며, 곧 100%로 늘릴 계획이다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 전문가 혼합형 AI 모델이란 무엇인가요?
하나의 거대한 AI 대신 여러 개의 작은 AI ‘전문가’들을 함께 사용하는 방식입니다. 입력되는 내용에 따라 가장 적합한 전문가 몇 개만 작동시키므로, 큰 AI의 능력은 유지하면서도 실제 계산량은 줄일 수 있습니다. 예를 들어 128개 전문가 중 8개만 선택해서 사용하는 식입니다.
Q2. 로라(LoRA)는 왜 메모리를 절약할 수 있나요?
AI 모델의 모든 부분을 다시 학습하는 대신, 작은 어댑터만 새로 학습하는 방법입니다. 전체를 학습하면 4,800만 개의 값을 다뤄야 하지만, 로라를 쓰면 100만 개(약 2%)만으로도 비슷한 결과를 얻을 수 있습니다. 학습 시간과 필요한 메모리가 크게 줄어드는 이유입니다.
Q3. 개인이 가진 일반 그래픽카드로도 대형 AI를 학습할 수 있나요?
네, 언슬로스 기술을 사용하면 가능합니다. RTX 3090 같은 게임용 그래픽카드로도 200억 개 파라미터 AI 모델을 12.8GB 메모리만으로 학습시킬 수 있습니다. 수천만 원대 전문 장비뿐 아니라 100만 원대 일반 그래픽카드에서도 작동하므로, 고가 장비 없이도 AI 모델 학습이 가능합니다.
기사에 인용된 리포트 원문은 Unsloth Documentation에서 확인 가능하다.
리포트명: Fine-tune MoE Models 12x Faster with Unsloth | Unsloth Documentation
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.