
On the generalization of language models from in-context learning and finetuning
: a controlled study
Generalization ability of large language models: AI vulnerable to inverse relationships during fine-tuning.
Large language models (LLMs) demonstrate interesting capabilities, but show surprisingly limited generalization abilities in fine-tuning. For example, there are cases where the model fails at simple logical reasoning based on the relationships it has learned or information it has been trained on. Such generalization failures in fine-tuning can hinder the practical application of the model. On the other hand, in-context learning of language models shows different inductive biases and in some cases demonstrates better generalization abilities.
The Google DeepMind research team has built several new datasets to explore the difference in generalization between context learning and fine-tuning based learning. These datasets are designed to separate knowledge from pre-training data to create a clean test for generalization. The research team exposed pre-trained large models to subsets of information from these datasets (within the context or through fine-tuning) and evaluated performance on test sets requiring various types of generalization.
Contextual learning shows up to 100% improvement in understanding inverse relationships compared to fine-tuning
According to the research results, it was shown that contextual learning can generalize more flexibly than fine-tuning in settings where the data matches. However, some limitations of previous research results were also found, for example, there were cases where fine-tuning could generalize for reversals included in a larger knowledge structure.
This study specifically focused on a phenomenon called ‘reversal curse’. In the phenomenon of reversal curse discovered in the study by Berglund et al. (2024), a fine-tuned language model that states “B’s mother is A” was shown to be unable to generalize to the question “Who is A’s son?”. However, models can easily answer these types of reverse relationship questions within the context.
Based on these findings, researchers proposed a method to improve generalization in fine-tuning: adding in-context reasoning to fine-tuning data. The researchers demonstrated that this method improves generalization in various partitions of datasets and different benchmarks.
Solution to ‘reverse curse’ discovered: Adding context-dependent inference to fine-tuned data drastically improves generalization ability.
In the study, various types of datasets were constructed to conduct experiments. The simple reversal and syllogism datasets contain independent examples of reversal relationships and syllogistic reasoning. For example, after learning the sentence “femp is more dangerous than glon,” it includes a test for the reversal relationship “glon is less/more dangerous than femp.” The reversal curse dataset includes a sentence description of a virtual celebrity proposed by Berglund et al. (2024).
For example, the name ‘Daphne Barington’ can be presented before or after the description (“director of Time Travel”). The meaning structure benchmark is built around a relational semantic hierarchy that allows for deductive reasoning and abstraction. This hierarchy is based on real-world categories and relationships, including 110 animal and object categories, attributes (1-6 per category, excluding inherited ones), and relationships. To eliminate potential overlap with pre-training data, all nouns, adjectives, and verbs were replaced with meaningless terms.”
A new method proposed to increase the fine-tuning effect through sentence splitting.
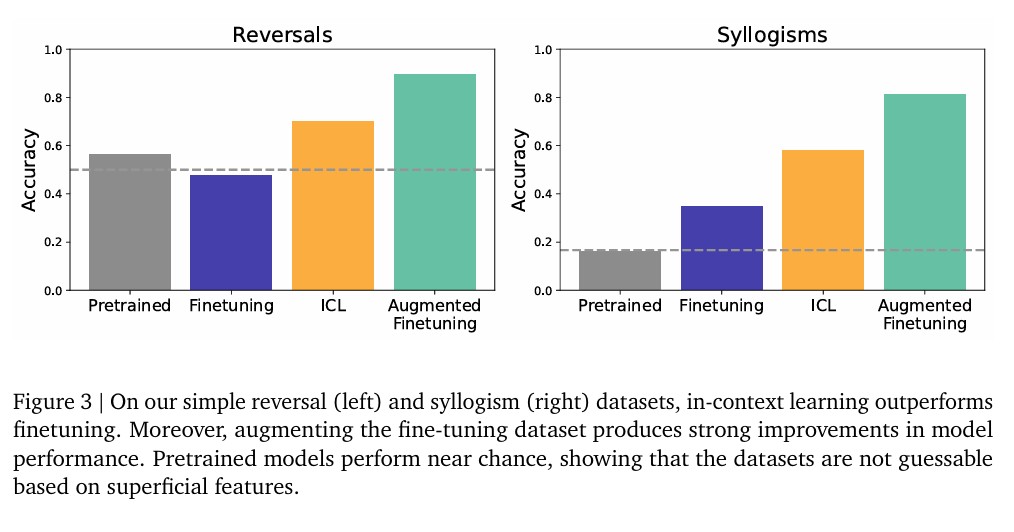
The main result of the study is the reproduction of previous research findings that fine-tuning in the forward direction in the adversarial curse dataset does not generate generalization for the backward direction. By presenting the entire dataset in context and systematically studying it, the model showed performance close to the maximum in the adversarial relationship. This strongly demonstrates the advantages of learning within the context over fine-tuning.
Furthermore, fine-tuning with data augmented by contextual inference also yielded similarly high test performance. Even in simple meaningless adversarial tests, contextual learning showed weaker but still noticeable advantages compared to fine-tuning, and there were additional stronger advantages in augmented fine-tuning.
In simple syllogism datasets, pre-trained models operated at chance levels indicating no contamination. Fine-tuning on the dataset produced some obscure generalizations, but learning within the context showed much stronger performance. Augmenting the training dataset with contextual learning improved overall performance.
In semantic structure benchmark tests, various generalizations were integrated in a richer learning environment. Evaluations were performed on rephrasing of learned statements, adversarial relationships, syllogistic reasoning, and propositions excluded from categories. Overall, there were advantages of learning within the context over fine-tuning, but the extent varied depending on the division. There were improvements in generalization of rephrased information from learning, and more dramatic improvements in adversarial relationships and syllogisms.
Learning through accidents: AI can acquire new knowledge through calculation alone without additional input.
The core approach proposed by the researchers is to improve the range of fine-tuning datasets using generalization within the context of the model. This aim is to improve out-of-context generalization at test time (i.e., without additional information in the context) by generating more fine-tuning data using computational reasoning within the context during training.
Specifically, two types of augmentations were considered. Local (sentence) augmentation involved augmenting each training data point (e.g., sentence) to allow the model to encode more flexibly. This approach used prompts involving rephrasing and inversion. Global (document) augmentation connected the entire training dataset into context, then provided the model with prompts to generate inferences through connections between a given document and other documents within the context.
This led to longer chains of related inferences. Additionally, some datasets include documents composed of multiple logically or semantically connected sentences. The researchers found that splitting these documents at the sentence level to create multiple fine-tuning examples significantly improved fine-tuning performance.
“When using meaningless words, the contextual learning performance deteriorates, and even greater differences are expected in real data.”
This study provides important insights into how language models learn differently in the context learning and fine-tuning modes. There have been several studies on the distinct inductive biases of context learning and fine-tuning, and this study contributes to this research trend by considering different types of knowledge beyond the commonly considered input-output tasks.
Lombrozo (2024) emphasized that “learning through reasoning” is an integrative theme across recent developments in cognitive science and AI. Systems can acquire new information and skills purely through computation without additional input. Contrary to appearances, this additional computation can actually enhance performance by increasing the accessibility of information. The use of context reasoning to enhance fine-tuning performance beyond the original data follows this pattern.
Recent studies are exploring extensions of test-time reasoning for performance enhancement, and these findings complement earlier research on expanding learning computation through larger models or more data. The results of this study suggest that expanding learning-time computation through context reasoning may help improve certain aspects of model generalization.
Innovative improvement of AI’s inference ability is possible through fine-tuning data augmentation techniques.
There are some limitations to this study. The key experiments rely on meaningless words and unrealistic calculations. These reflexive tasks can help avoid dataset contamination, but they may also hinder the model’s performance to some extent. According to preliminary experiments, replacing the names of reverse curse datasets with meaningless ones can degrade the model’s contextual learning performance. Also, the researchers did not conduct experiments with other language models to increase the generality of the results. However, since phenomena like the reverse curse have been observed in multiple models during fine-tuning in previous studies, it is believed that these results can be reasonably extended to different environments.
This research contributes to understanding the training and generalization of large-scale language models, and presents practical methods for adapting them to downstream tasks. In particular, it shows that a simple method of adding contextual inference to fine-tuning data can significantly improve performance in various types of generalization tasks. These findings provide important insights into ways to adapt models or adjust them to new tasks or information. The methods proposed by the researchers are related to recent studies.
Some concurrent studies suggest that language models can generate additional inference directions and that using them for training data augmentation can improve the performance of inference tasks. This is a similar approach to the method proposed in this study. In addition, Yang et al. (2024) used language models to extract entities from training documents and generated synthetic data for inferring links between these entities. Similarly to the results of this study, they found that rearranging knowledge in this way helps improve downstream performance.
FAQ
Q: What is the reason why fine-tuned language models fail to generalize in simple inverse relationships?
A: Language models tend to overly adapt to the specific patterns and relationships presented during fine-tuning. When fine-tuned with sentences like “B’s mother is A,” the model learns only this exact relationship and struggles to generalize to logical inverse relationships like “A’s son is B.” Contextual learning allows the model to process information more flexibly and consider relationships from various perspectives.
Q: What is the reason why contextual learning demonstrates better generalization ability than fine-tuning?
A: Contextual learning enables the model to interpret provided examples more flexibly and recognize various patterns. While fine-tuning optimizes the model’s weights for specific data distributions, contextual learning allows the model to infer patterns on the spot and apply various reasoning methods. As a result, it shows better performance in challenging generalization tasks like inverse relationships or syllogisms.
Q: What practical significance do these research findings hold for AI developers and users?
A: This research suggests a more effective approach to adapting language models to new tasks or domains than simply fine-tuning with original data. By reinforcing fine-tuning data with information inferred contextually, the model’s generalization ability can be significantly improved. This assists AI systems in learning new information more comprehensively and applying it from various perspectives. It also presents the possibility to efficiently reduce the amount of data needed for model training.
The paper quoted in the article can be found at the following link.
Image source: Google
The article was written using Claude and ChatGPT.

![[2025 대선] 후보별 AI 정책 비교분석, 대한민국 AI 패권의 향방은?](https://aimatters.co.kr/wp-content/uploads/2025/05/AI-Matters-기사-썸네일-2025-president.jpg)
![[Q&AI] 대선 후보 첫 TV토론 주요 내용 정리… AI가 분석한 여론은?](https://aimatters.co.kr/wp-content/uploads/2025/05/AI-Matters-기사-썸네일-QAI-1.jpg)
![[Q&AI] 최고가 찍은 삼양식품 주가... 단기 전망은?](https://aimatters.co.kr/wp-content/uploads/2025/05/AI-Matters-기사-썸네일-QAI.jpg)

