
최근 AI 연구에서 충격적인 결과가 나왔다. 챗GPT(ChatGPT)나 딥시크(DeepSeek) 같은 최첨단 AI 모델이 문제를 풀 때 중간 과정을 억지로 줄이면, 아예 생각을 안 하는 것보다 오히려 성능이 더 나빠진다는 사실이 밝혀진 것이다. 2026년 2월 arxiv에 공개된 논문 “Broken Chains: The Cost of Incomplete Reasoning in LLMs”는 GPT-5.1, Gemini 3 Flash, DeepSeek-V3.2, Grok 4.1 등 4개의 최신 AI 모델을 대상으로 ‘생각하는 방식’과 ‘생각하는 양’이 성능에 어떤 영향을 미치는지 체계적으로 실험한 결과를 담았다.
반만 생각한 AI, 차라리 안 생각하는 것보다 못하다
AI가 복잡한 문제를 풀 때 사용하는 핵심 기술 중 하나가 연쇄적 사고(CoT, Chain-of-Thought)다. 이는 사람이 수학 문제를 풀 때 중간 계산 과정을 적어가며 풀듯이, AI도 단계별 풀이 과정을 생성하면서 최종 답을 도출하는 방식이다. 문제는 이 과정을 생성하는 데 사용되는 ‘토큰(token)’이라는 단위가 비용과 시간을 잡아먹는다는 점이다. 토큰은 AI가 처리하는 텍스트의 최소 단위로, 단어 하나 혹은 그보다 더 작은 조각이라고 이해하면 된다.
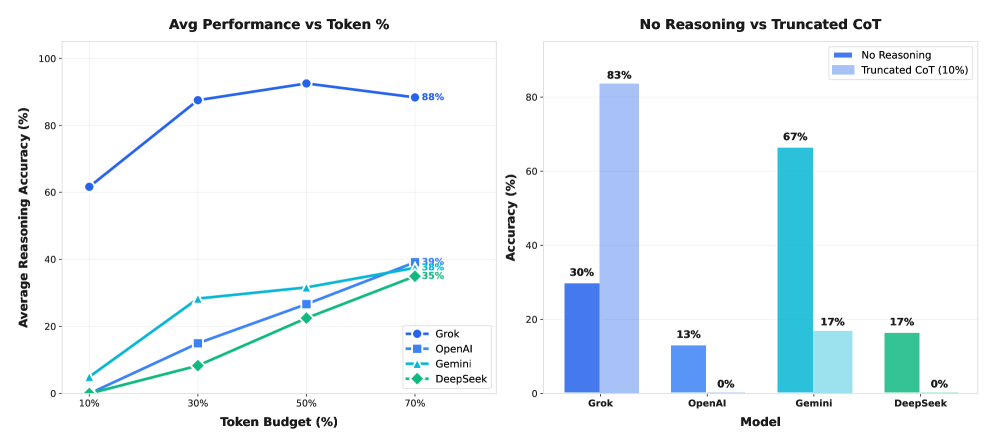
연구팀은 각 모델이 문제를 자유롭게 풀 때 사용하는 토큰 수를 100%로 기준 삼고, 이를 10%, 30%, 50%, 70%로 강제로 줄였을 때 성능이 어떻게 변하는지 측정했다. 결과는 놀라웠다. 딥시크-V3.2는 아무 추론 과정 없이 바로 답을 출력했을 때 53%의 정확도를 기록했지만, 토큰을 50%로 제한해 추론을 강제로 중단시켰을 때는 고작 17%에 그쳤다. 즉, 반쪽짜리 생각이 생각을 아예 안 하는 것보다 훨씬 해롭다는 역설이 증명된 것이다.
코드로 생각하는 AI가 글로 생각하는 AI보다 더 버틴다
연구팀은 AI가 추론하는 방식을 크게 4가지로 나눠 실험했다. 첫째는 실행 가능한 코드로만 사고하는 방식(코드 전용), 둘째는 자연어 설명으로만 사고하는 방식(주석 전용), 셋째는 둘을 혼합한 방식(하이브리드), 넷째는 아무 과정 없이 바로 답을 내는 방식(추론 없음)이다.
토큰을 30%로 줄였을 때, 제미나이의 자연어 방식 성능은 0%로 완전히 붕괴했지만, 코드 방식은 43%를 유지했다. 50% 제한에서도 같은 격차(0% 대 47%)가 이어졌다. 연구팀은 그 이유를 코드의 구조적 특성에서 찾았다. 코드는 반쪽짜리 반복문(for loop)이나 조건문(if문)이라도 ‘이 부분에서 반복이 일어난다’, ‘이 조건에서 분기가 생긴다’는 의미를 보존한다. 반면 자연어로 된 추론은 중간에 잘리면 논리적 연결 고리 자체가 끊겨버린다.
두 가지를 동시에 쓰면 오히려 역효과, 하이브리드의 함정
직관적으로는 코드와 자연어를 함께 사용하는 하이브리드 방식이 가장 강력할 것 같지만, 실험 결과는 반대였다. 모든 토큰 예산 조건에서 하이브리드 방식은 단일 방식보다 성능이 낮았다. 그록의 경우 코드 전용과 자연어 전용 모두 90%를 달성했지만, 둘을 섞었을 때는 80%로 떨어졌다. 연구팀은 이를 ‘방식 전환 비용’ 때문으로 설명한다. AI가 코드에서 자연어로, 또는 자연어에서 코드로 전환할 때마다 현재까지의 계산 상태를 정리하고 다시 인코딩하는 작업이 필요한데, 이 과정에서 토큰이 낭비되고 실제 문제 풀이에 쓸 수 있는 자원이 줄어드는 것이다.
같은 압박에서 그록 80~90% vs GPT 10~27%, 모델마다 극명한 차이
이번 연구에서 가장 실용적으로 중요한 발견은 모델별 강인성(robustness)의 극심한 차이다. 토큰을 30%로 제한했을 때 그록 4.1은 코드, 자연어, 연쇄적 사고 방식 모두에서 80~90%의 정확도를 유지했다. 반면 GPT-5.1은 10~27%, 딥시크-V3.2는 7~47%로 급격히 무너졌다. 극단적인 10% 토큰 제한에서는 격차가 더 벌어져, 그록은 코드 방식에서 77%, 연쇄적 사고 방식에서 83%를 기록했지만 GPT와 딥시크는 거의 0%에 수렴했다.
연구팀은 딥시크-V3.2처럼 긴 추론 과정을 생성하도록 특화 훈련된 모델일수록 완전한 추론 과정에 더 의존적이 되고, 중간에 잘렸을 때 더 큰 혼란을 겪는다고 분석했다. 이는 AI 서비스를 운영하는 기업이나 개발자 입장에서 매우 실질적인 함의를 가진다. 속도나 비용 제한이 있는 실제 환경에서 어떤 모델을 쓰느냐에 따라, 같은 제약 조건에서 성능 차이가 10배 이상 벌어질 수 있기 때문이다.
추론 전문 AI일수록 토큰 부족에 더 취약하다
이번 연구는 AI 서비스를 도입하거나 활용하는 기업과 개발자에게 중요한 경고를 던진다. 복잡한 추론에 강하다고 알려진 모델이 토큰 제약 상황에서 오히려 더 불안정할 수 있다는 점이다. 딥시크-V3.2처럼 긴 사고 과정으로 훈련된 모델은 그 과정이 강제로 중단될 때, 오히려 아무 추론도 하지 않는 것보다 더 나쁜 결과를 낸다. 실제 서비스 환경에서는 응답 속도, API 비용, 컨텍스트 창(context window) 제한 등 다양한 이유로 토큰이 제한되는 경우가 흔하다. 이런 상황에서는 무조건 ‘더 똑똑한 추론 모델’이 아니라, 제약 환경에서도 안정적인 모델을 선택하거나, 추론 방식 자체를 코드 기반으로 전환하는 전략이 필요하다. 또한 하이브리드 프롬프트 설계가 직관과 달리 역효과를 낼 수 있다는 점도 실무에서 반드시 고려해야 할 사항이다.
FAQ(※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 연쇄적 사고(CoT)가 뭔가요? AI가 생각하는 방식이 왜 중요한가요?
A. 연쇄적 사고(Chain-of-Thought, CoT)란 AI가 최종 답을 내기 전에 중간 풀이 과정을 단계별로 생성하는 방식입니다. 사람이 수학 문제를 풀 때 메모지에 과정을 적으며 검토하듯, AI도 이 과정을 통해 복잡한 문제를 훨씬 잘 풀 수 있습니다. 다만 이 과정이 중간에 강제로 잘리면, 오히려 결론을 잘못 유도할 수 있다는 것이 이번 연구의 핵심 발견입니다.
Q2. AI 서비스를 사용할 때 토큰 제한이 실제로 문제가 되나요?
A. 네, 매우 실질적인 문제입니다. 많은 AI API(응용프로그램 연결 인터페이스)는 비용이나 속도를 이유로 한 번에 처리할 수 있는 토큰 수를 제한합니다. 기업에서 AI를 자동화 업무나 고객 응대에 활용할 때, 이 제한 안에서 얼마나 똑똑하게 작동하느냐가 서비스 품질을 결정합니다.
Q3. 어떤 AI 모델이 제약 환경에서 가장 안정적으로 작동하나요?
A. 이번 연구에 따르면, xAI의 그록 4.1이 토큰을 30%만 써도 80~90% 수준의 성능을 유지해 가장 강인한 모습을 보였습니다. 반면 GPT-5.1과 딥시크-V3.2는 같은 조건에서 10~27%까지 성능이 떨어졌습니다. 단, 이 연구는 수학 문제 한정이므로 다른 영역에서의 성능은 별도 검토가 필요합니다.
기사에 인용된 리포트 원문은 arxiv에서 확인할 수 있다.
리포트명: Broken Chains: The Cost of Incomplete Reasoning in LLMs
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





