오픈AI가 새로운 AI 모델 ‘o3’와 ‘o3 mini’를 발표했다. ‘12 Days of OpenAI: Day 12’의 마지막 날 공개된 두 모델은 기존 모델인 ‘o1’보다 더 향상된 성능을 보여주며, 특히 코딩과 수학 분야에서 괄목할만한 성과를 기록했다. o1 다음으로 ‘o2’라는 이름을 붙이지 않은 것은 영국 통신사의 이름과 겹치기 때문이라고 설명했다.
코딩과 수학 분야에서 탁월한 성능 입증
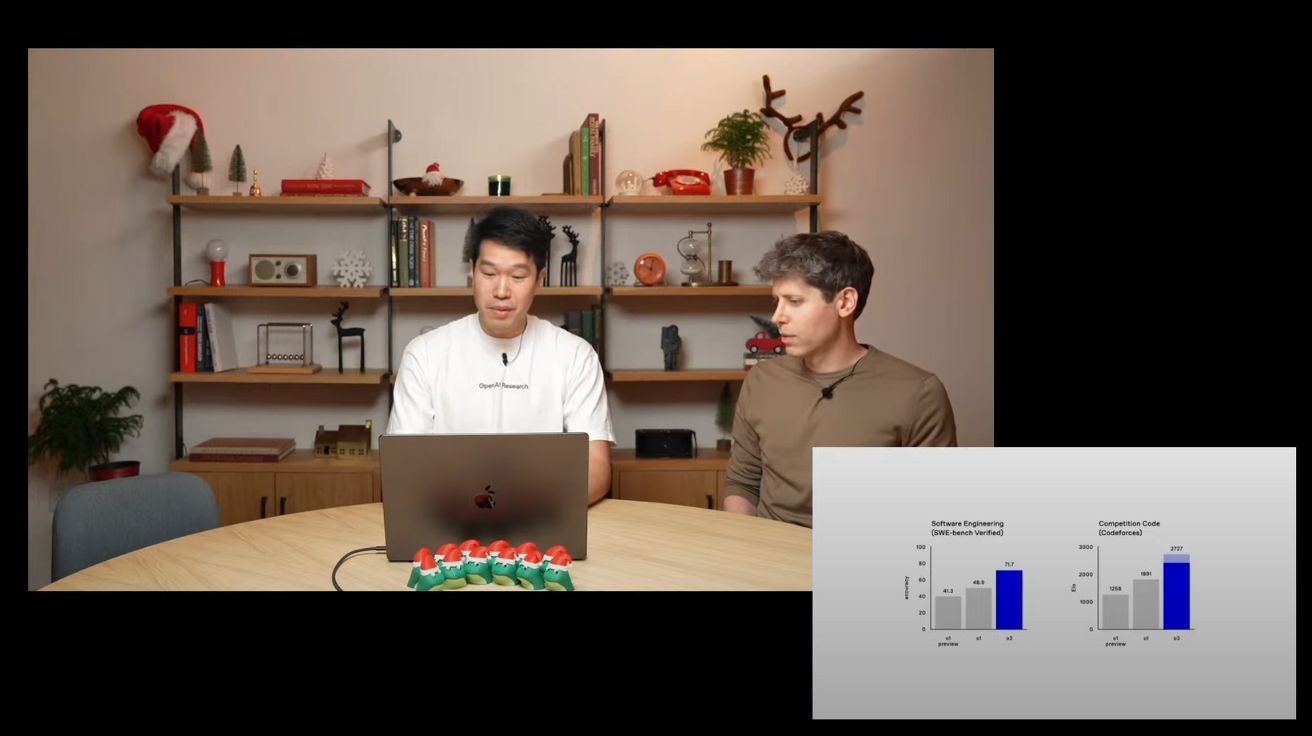
오픈AI의 연구 책임자 마크에 따르면, o3는 소프트웨어 벤치마크인 ‘스윗벤치 베리파이드(Sweet Bench Verified)’에서 71.7%의 정확도를 보였다. 이는 o1보다 20% 이상 향상된 수치다. 코딩 대회 플랫폼인 코드포스(CodeForces)에서는 2727의 엘로(ELO) 레이팅을 기록했다. 이는 대부분의 전문 프로그래머들의 점수를 앞서는 수준이다.
수학 분야에서는 미국 수학 올림피아드 예선 시험에서 96.7%의 정확도를 기록했으며, PhD 수준의 과학 문제를 평가하는 ‘GPQ 다이아몬드(GPQ Diamond)’ 테스트에서는 87.7%의 정확도를 달성했다. PhD 전문가들의 평균 정확도가 70% 수준임을 감안하면 주목할 만한 성과다.
ARC 프라이즈 재단(ARC Prize Foundation)의 그렉 카맛 대표에 따르면, o3는 인공지능의 일반 지능을 평가하는 ‘ARC AGI’ 벤치마크에서 역대 최고 성적을 기록했다. 일반 연산 설정에서 75.7%, 고성능 연산 설정에서는 87.5%를 기록했는데, 이는 인간의 평균 성능인 85%를 뛰어넘는 수준이다.
O3 미니, 효율성과 성능의 새로운 기준 제시
오픈AI 연구원 홍우란은 o3 미니가 저비용으로 뛰어난 성능을 제공한다고 설명했다. o3 미니는 낮음, 중간, 높음 세 가지 수준의 추론 능력을 지원하며, 사용자는 문제의 복잡성에 따라 적절한 수준을 선택할 수 있다.
코딩 성능 평가에서 o3 미니는 중간 수준의 추론으로도 o1을 능가했으며, 비용 대비 성능 면에서 새로운 기준을 제시했다. 또한 함수 호출, 구조화된 출력, 개발자 메시지와 같은 API 기능을 모두 지원한다.
안전성 강화를 위한 새로운 접근 및 출시 일정
오픈AI는 ‘심의적 조정(Deliberative Alignment)’이라는 새로운 안전성 기술을 도입했다. 이 기술은 AI 모델이 입력된 프롬프트의 안전성을 추론하고 판단할 수 있게 해준다. 기존 모델들과 비교해 안전하지 않은 요청을 더 정확하게 식별하고 거부할 수 있다.
오픈AI는 두 모델의 안전성 테스트를 위해 외부 연구자들의 참여를 요청했다. 안전성 테스트는 2024년 1월 10일까지 진행되며, o3 미니는 1월 말, o3는 그 직후 공개될 예정이다. 연구자들은 오픈AI 웹사이트를 통해 테스트 참여를 신청할 수 있다.
해당 기사의 원문은 오픈AI 공식 유튜브에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기