오픈AI(OpenAI)가 21일(현지 시간) 인공지능 언어모델의 안전성을 획기적으로 향상시킬 수 있는 ‘숙고형 정렬(Deliberative alignment)’ 기술을 공개했다. 이 기술은 O시리즈 모델에 적용되어 기존 GPT-4를 뛰어넘는 안전성 성능을 입증했다.
즉각 응답의 위험성, 기존 AI의 구조적 한계
오픈AI에 따르면, 현대의 언어모델들은 광범위한 안전 훈련에도 불구하고 여전히 악의적인 프롬프트에 응답하거나, 무해한 쿼리를 과도하게 거부하는 등의 문제를 보였다. 이는 모델이 복잡한 안전 시나리오를 충분히 검토할 시간 없이 즉각적으로 응답해야 하는 구조적 한계 때문이었다.
자연어로 직접 배우는 AI, 숙고형 정렬의 혁신
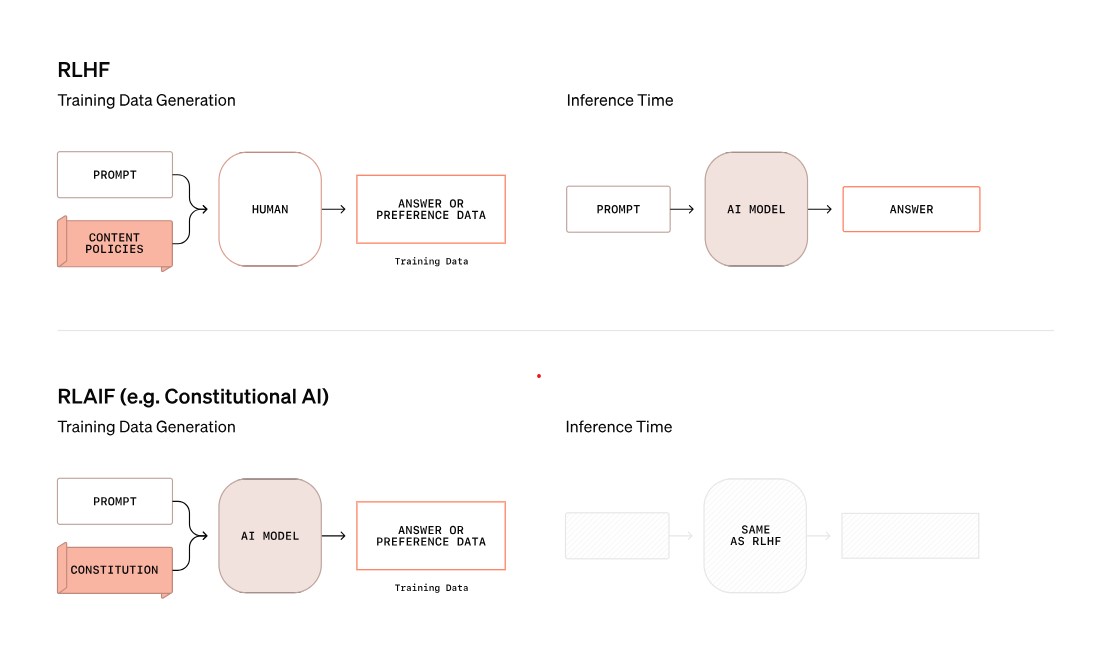
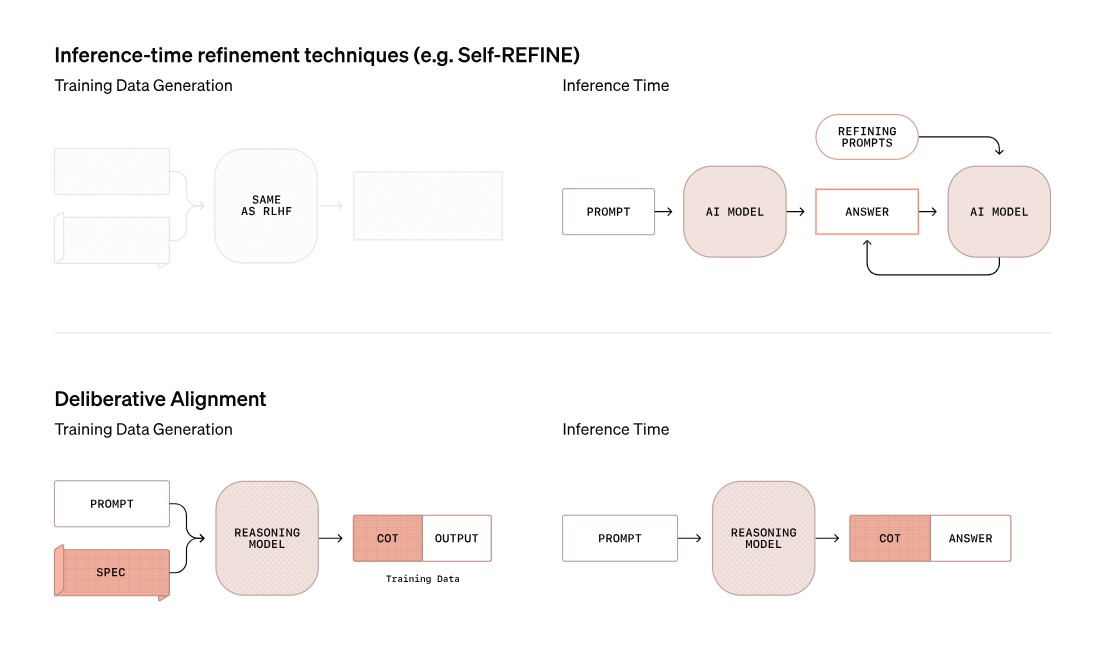
숙고형 정렬은 모델에게 안전 정책을 자연어 형태로 직접 학습시키고, 추론 시간에 이를 활용하도록 하는 최초의 접근법이다. 기존의 인간 피드백 강화학습(RLHF)이나 AI 피드백 강화학습과 달리, 안전 정책 자체를 모델에 제공하여 더 효과적인 의사결정이 가능하도록 했다.
인간 개입 없는 자동 학습으로 효율성 높여
숙고형 정렬의 훈련 과정은 먼저 도움이 되는 기본 모델을 훈련하는 것으로 시작한다. 이후 안전 정책을 참조하는 대화 데이터셋을 구축하고, 점진적 지도 미세조정(SFT)을 수행한다. 마지막으로 강화학습(RL)을 통해 사고과정을 최적화하는 단계를 거친다. 이러한 방식은 인간이 레이블링한 데이터 없이도 자동으로 훈련 데이터를 생성할 수 있어, 기존 AI 안전 훈련의 큰 걸림돌이었던 인간 레이블링 의존도 문제를 해결했다.
최신 AI 모델들과 비교해 뛰어난 안전성 입증
O1 모델은 GPT-4o, 클로드 3.5 소네트(Claude 3.5 Sonnet), 제미나이 1.5 프로(Gemini 1.5 Pro) 등 최신 언어모델들과의 비교 테스트에서 우수한 성능을 보였다. 특히 악의적인 프롬프트 거부와 정상적인 요청 수용 모두에서 더 나은 균형을 달성했으며, 많은 안전성 평가에서 최고 성능을 기록했다.
AI 능력 향상에 따른 안전성 연구 지속
오픈AI는 O1과 O3와 같은 AI 능력 향상이 상당한 위험을 동반할 수 있다고 경고했다. 모델의 지능과 자율성이 높아질수록 잘못된 정렬이나 오용으로 인한 잠재적 피해 규모도 커질 수 있다는 것이다. 이에 회사는 AI 시스템이 인간의 가치와 부합하도록 하는 연구, 특히 기만 행위 감지를 위한 사고과정 모니터링 등에 지속적으로 투자할 계획이다.
해당 기사의 원문은 오픈AI 유튜브에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.



![[Q&AI] 15억 로또 ‘올림픽파크포레온’ 청약 시작… 고려 사항은?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-4.jpg)