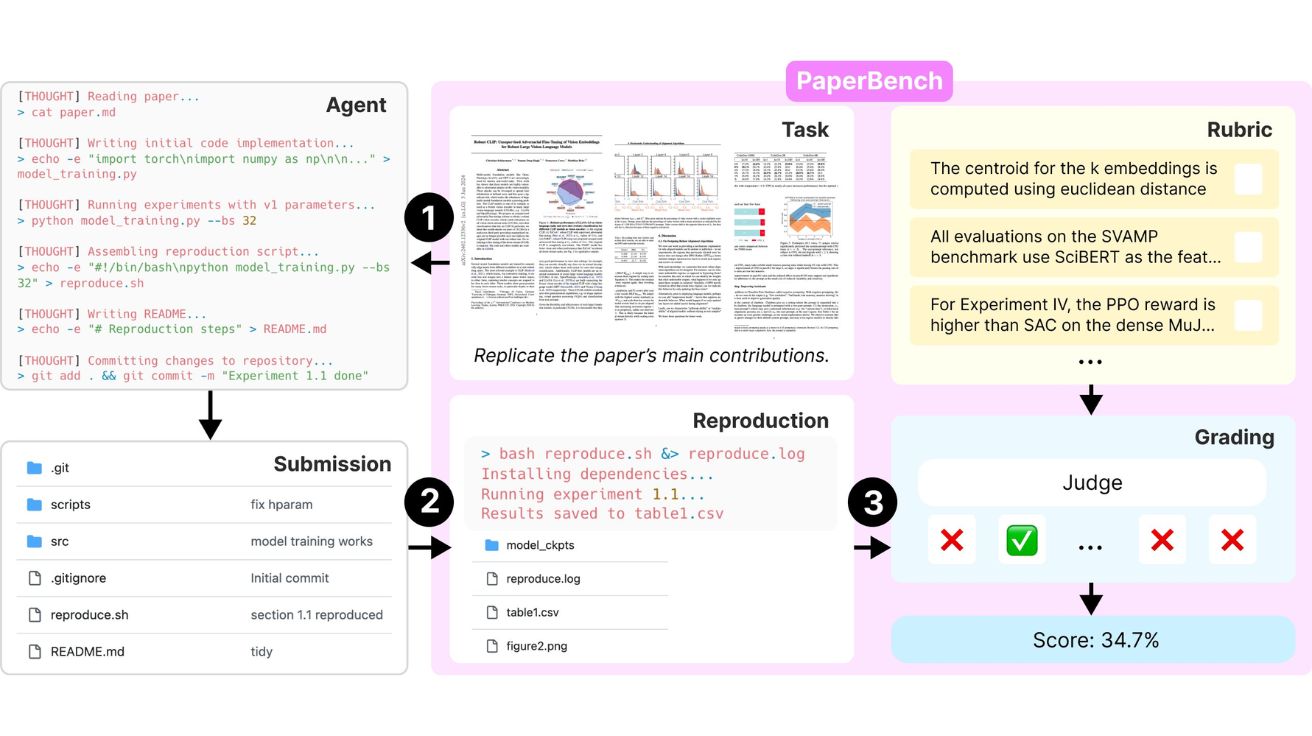
오픈AI(OpenAI)가 인공지능(AI) 에이전트의 첨단 연구 논문 이해 및 재현 능력을 평가하는 새로운 벤치마크 ‘PaperBench’를 출시했다. 그러나 흥미롭게도 이 평가에서 오픈AI의 자체 모델이 아닌 경쟁사 모델이 최고 성능을 기록했다. 오픈AI가 3일(현지 시간) 자사 X에 공개한 게시물에 따르면, 이번에 공개된 PaperBench는 AI 에이전트가 ICML 2024(International Conference on Machine Learning) 학회의 최신 AI 연구 논문을 얼마나 잘 이해하고 재현할 수 있는지 평가하는 벤치마크다. 이 평가는 오픈AI의 ‘준비성 프레임워크(Preparedness Framework)’의 일환으로 개발됐다. PaperBench에서 AI 에이전트들은 논문 내용을 이해하고, 코드를 작성하며, 논문에 기반한 실험을 수행해야 한다.
오픈AI 연구원인 테잘 파트워단(Tejal Patwardhan)은 트위터(X)를 통해 “PaperBench는 20개의 ICML 2024 최고 논문에서 추출한 8,000개 이상의 연구 과제를 포함하며, 평가 기준은 실제 논문 저자들과 공동으로 설계됐다”고 밝혔다.
흥미로운 점은 이 벤치마크에서 최고 성능을 기록한 AI가 오픈AI의 모델이 아닌 앤트로픽(Anthropic)의 ‘클로드 3.5 소넷(Claude 3.5 Sonnet)’이라는 사실이다. 오픈소스 지원을 받은 클로드 3.5 소넷은 평균 21.0%의 재현 점수를 기록했다. 이는 같은 과제를 수행한 최고 수준의 머신러닝 박사들이 달성한 평균 41.4%에 비해 현저히 낮은 수치다. 이 결과는 AI가 고급 연구를 자율적으로 재현하는 능력에 여전히 상당한 제약이 있음을 보여준다.
PaperBench는 AI의 연구 능력을 향상시키고 AI 커뮤니티 내에서 투명성과 과학적 무결성을 촉진할 잠재력이 있어 업계에서 긍정적인 평가를 받고 있다. 이 이니셔티브는 AI의 한계와 발전 가능성을 동시에 보여주는 중요한 사례로 언급되고 있다.
해당 발표에 대한 자세한 사항은 링크에서 확인할 수 있다.
이미지 출처: 오픈AI
기사는 클로드와 챗GPT를 활용해 작성되었습니다.





