
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model
for Generalist Ophthalmic Artificial Intelligence
26개국 340만장 안구 사진으로 완성된 최첨단 AI
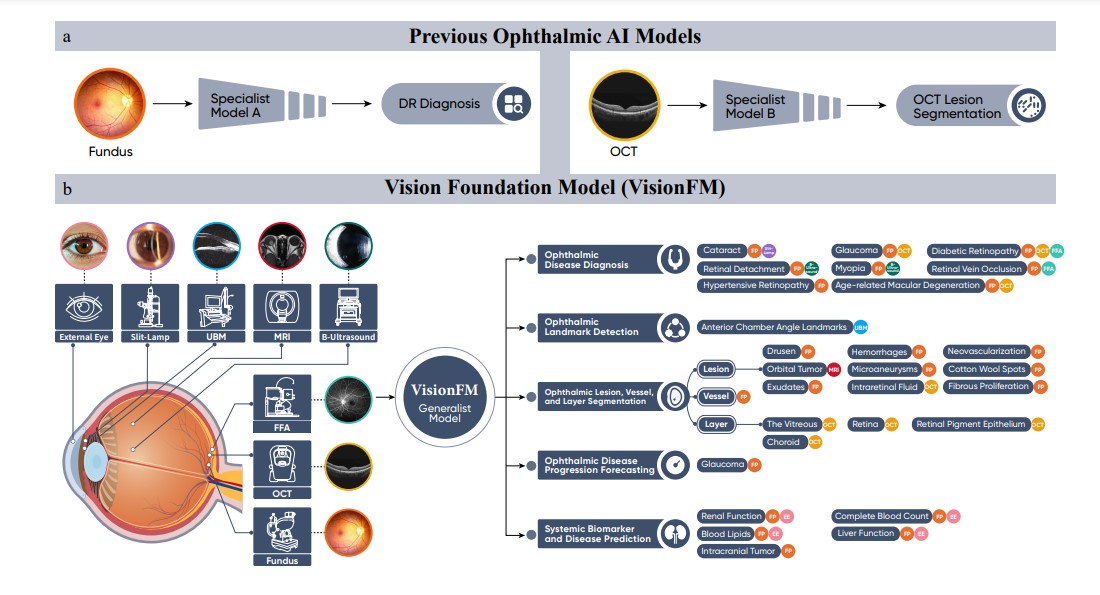
중국과 홍콩 연구진이 26개국의 56만여 명 환자로부터 수집한 340만 장의 안과 이미지로 학습한 AI 기반 모델 ‘비전FM(VisionFM)’을 개발했다. 연구진이 발표한 논문에 따르면, 이 모델은 안저촬영(FP), 빛간섭단층촬영(OCT), 초음파생체현미경(UBM), 세극등현미경(Slit-lamp), 형광안저혈관조영술(FFA), 자기공명영상(MRI) 등 8가지 안과 영상을 단일 모델로 처리할 수 있다.
데이터는 OCT(41.81%), 안저촬영(29.74%), 외안부 검사(11.86%), UBM(5.46%), FFA(3.11%), MRI(2.12%), B초음파(2.27%), 기타(3.62%)로 구성되었다. 각 영상은 Heidelberg, Optovue, Canon, Topcon, Nikon 등 다양한 제조사의 장비로 촬영되었으며, OCT 데이터의 경우 36,074명 이상의 환자 데이터가, 안저촬영은 490,238명 이상의 환자 데이터가 포함되었다.
8년차 의사도 따라올 수 없는 진단 정확도 입증
비전FM은 23개 공공 데이터셋과 5개 사설 병원 데이터셋으로 구성된 대규모 벤치마크 테스트에서 평균 AUC 0.993, 평균 정밀도(AP) 0.969를 달성했다. 이는 기존 ResNet의 0.799를 크게 웃도는 수치다. 특히 기존 RETFound 모델과 달리 단일 모달리티 디코더로 여러 질환을 동시 진단할 수 있는 혁신성을 보였다.
12개 주요 안과질환 진단에서 경력 1-3년차 초급 의사와 4-8년차 중급 의사보다 높은 정확도를 기록했으며, F1 스코어는 중급 의사(42.6%)의 약 2배인 82.8%를 달성했다. iChallenge-AMD 데이터셋 평가에서도 5개 지표 중 4개에서 최고 성능을 보였다.
눈 사진 한 장으로 뇌종양부터 당뇨까지 찾아내는 AI
기존에 접하지 않은 영상 기법에도 높은 적응력을 보였다. 학습 과정에서 한 번도 접하지 않은 광각깊이혈관조영술(OCTA) 이미지로 당뇨망막병증을 진단할 때도 0.935의 높은 정확도를 기록했다. 녹내장 진행 예측에서는 76.9%의 F1 스코어를 달성했다.
전신 건강 상태 예측에서도 탁월한 성능을 보였다. 38종의 전신 바이오마커 예측에서 평균 78.6% ±15.2%의 정확도를 보였으며, 세부적으로는 신장기능 바이오마커 84.8% ±5.6%, 24개 혈액검사 관련 바이오마커 81.7% ±15.1%, 혈중콜레스테롤 84.7%, 혈당 84.4%의 높은 정확도를 달성했다. 간기능 관련 5개 바이오마커는 61.0% ±8.5%의 정확도를 보였다. 특히 뇌종양 예측에서는 AUC 0.982, AP 0.990의 놀라운 성능을 보였다.
AI는 어떻게 안구 사진을 읽고 질병을 진단하나
비전FM은 어텐션 맵 기술을 활용해 이미지의 주요 특징을 효과적으로 포착한다. 안구 외부 이미지 분석 시에는 동공, 홍채, 공막에 집중하고, 안저촬영과 FFA 이미지에서는 시신경유두, 황반, 혈관, 병변 부위를 중점적으로 분석한다.
특히 주목할 만한 점은 단일 모달리티만으로도 다중 모달리티 수준의 진단 정확도를 달성할 수 있다는 것이다. 이는 의료 자원이 부족한 지역에서도 제한된 장비로 정확한 진단이 가능함을 의미한다.
연구팀은 실제 임상 데이터가 부족한 영역을 보완하기 위해 합성 이미지를 활용했다. 시각적 튜링 테스트 결과, 세극등 이미지는 42.7% ±12.1%, MRI 이미지는 51.6% ±4.5%의 점수를 받아 실제 이미지와 구분하기 어려운 수준임이 입증되었다. 실제 데이터와 합성 데이터의 비율을 1:5로 설정했을 때 최적의 성능을 보였다.
의료 현장에서 의사의 든든한 파트너가 될 AI
비전FM은 대규모 안과 질환 스크리닝에 즉시 활용할 수 있으며, 외래 진료 시 의사의 진단을 보조하는 도구로도 사용될 수 있다. 이를 통해 의료진의 업무 효율성을 높이고 행정적 비용을 절감할 수 있을 것으로 기대된다.
WHO 2019년 보고서에 따르면 전 세계적으로 22억 명 이상이 시력 장애를 겪고 있다. 특히 저소득 국가의 경우 인구 100만 명당 안과 의사 수가 3.7명에 불과해 선진국의 5% 수준에 그친다. 비전FM은 이러한 의료 격차를 해소하는데 기여할 것으로 기대된다.
의사 한 명당 환자 27만명…AI가 해결책이 될까
연구진은 비전FM이 안과 AI의 새로운 시대를 여는 기반 모델이 될 것이라고 전망했다. 향후 질병 예후 및 진행 예측 기능을 강화하고, 전신질환과 안과질환의 연관성 연구를 확장할 계획이다. 또한 대규모 언어 모델(LLM)과 결합해 진단서 작성 기능도 추가할 예정이다.
현재 데이터가 중국인 환자에 편중되어 있어 인종 다양성 측면에서 개선이 필요하다. 또한 8가지 영상 기법 외에도 더 많은 기법을 다룰 수 있도록 확장하고, 의료 기록 데이터를 활용해 희귀질환 진단 성능을 개선할 계획이다. 이를 위해 다기관 연구를 통한 데이터 다양성 확보도 진행할 예정이다.
해당 기사에서 인용한 논문의 원문은 링크에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기




![[Q&AI] 신지 결혼 상대 문원, 코요태 상견례 영상 공개 후 여론 악화… 왜?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-2.jpg)
