
What is the Role of Small Models in the LLM Era: A Survey
영국 임페리얼 칼리지 런던과 프랑스 소다 연구소가 발표한 연구에 따르면, 거대언어모델(LLM)이 AI 발전을 주도하는 시대에도 작은 규모의 AI 모델이 여전히 중요한 역할을 하고 있는 것으로 나타났다.
실제 현장에서 입증된 소형 모델의 가치
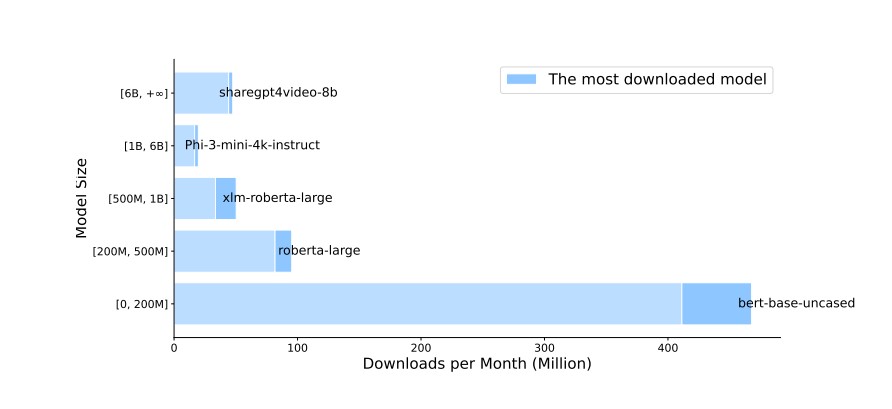
허깅페이스(HuggingFace)의 다운로드 데이터 분석 결과, 파라미터 수에 따른 다섯 개 그룹(0-200M, 200M-500M, 500M-1B, 1B-6B, 6B 이상) 중 가장 작은 규모의 모델들이 여전히 높은 인기를 누리고 있다. 특히 버트-베이스(BERT-base)는 월간 수백만 건의 다운로드를 기록하며, 대형 모델 시대에도 실무 환경에서 널리 활용되고 있음을 보여준다. 대형 모델들의 화려한 성과에도 불구하고, 소형 모델의 실용적 가치가 과소평가되고 있다는 것이 연구진의 분석이다.
대형 모델과 소형 모델의 특성 비교
연구는 두 모델 간의 협력을 크게 여덟 가지 영역으로 분석했다.
첫째, 데이터 선별에서 소형 모델은 사전 학습과 명령어 조정을 위한 고품질 데이터를 효과적으로 선별한다. 둘째, 약한 모델에서 강한 모델로의 학습 패러다임을 통해 대형 모델의 성능을 개선한다. 셋째, 효율적 추론을 위해 모델 앙상블과 추측적 디코딩을 활용한다. 넷째, 대형 모델의 출력을 평가하고 불확실성을 측정한다. 다섯째, 도메인 특화 적응을 통해 대형 모델의 성능을 향상시킨다. 여섯째, 정보 검색 증강 생성에서 소형 모델이 검색기로 활용된다. 일곱째, 프롬프트 기반 학습에서 소형 모델이 프롬프트를 최적화한다. 여덟째, 대형 모델의 결함을 보완하는 플러그인으로 작동한다.
반대로 대형 모델은 소형 모델을 강화하는 두 가지 주요 방식을 제공한다. 지식 증류를 통해 소형 모델의 성능을 개선하고, 데이터 합성을 통해 학습 데이터를 생성한다. 특히 화이트박스와 블랙박스 지식 증류, 데이터 증강과 학습 데이터 생성 등 다양한 기법이 활용된다.
대형 모델과 작은 모델의 협력 방식
연구는 두 모델 간의 협력을 크게 여덟 가지 영역으로 분석했다. 소형 모델은 데이터 선별, 효율적 추론, 품질 평가, 도메인 적응, 정보 검색 증강, 프롬프트 기반 학습, 결함 보완 등의 영역에서 대형 모델을 보완한다. 예를 들어 사전 학습이나 명령어 조정용 데이터를 선별할 때 소형 모델이 효과적으로 활용된다. 반대로 대형 모델은 지식 증류와 데이터 합성을 통해 소형 모델의 성능 향상을 돕는다.
계산 자원 제약 환경에서의 실용성
학계 연구자나 충분한 수익을 확보하지 못한 기업들의 경우, 대형 모델의 학습과 배포에 필요한 막대한 컴퓨팅 자원과 에너지 소비를 감당하기 어렵다. MTEB(Massive Text Embedding Benchmark) 데이터셋 분석 결과, 텍스트 유사도나 분류 작업과 같이 복잡한 추론이 필요하지 않은 태스크에서는 모델 크기 증가에 따른 성능 향상이 미미한 것으로 나타났다. 특히 생체의학이나 법률 분야와 같은 전문 영역에서는 작은 규모의 특화된 모델이 범용 대형 모델보다 더 나은 성능을 보이기도 한다.
특수 분야에서의 소형 모델 우위
생체의학이나 법률 분야와 같은 전문 영역, 표 형식 데이터 학습, 짧은 텍스트 처리, 기계 생성 텍스트 감지, 스프레드시트 표현, 정보 추출 등 특정 태스크에서는 소형 규모의 특화된 모델이 범용 대형 모델보다 더 나은 성능을 보인다. 특히 의료, 금융, 법률과 같이 의사결정의 투명성이 중요한 분야에서는 소형 모델의 높은 해석 가능성이 큰 장점이 된다.
연구진은 “LLM과 소형 모델은 각각의 장단점을 가지고 있으며, 실제 적용 시에는 작업의 특성과 요구사항에 따라 신중한 선택이 필요하다”고 강조했다.
해당 리포트의 원문은 링크에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기







