
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
중국 저장대학교와 하얼빈공과대학교 공동 연구진이 발표한 최신 연구에 따르면, 대규모 언어모델(LLM)을 활용한 합성데이터 생성 기술이 인공지능 발전의 새로운 동력이 되고 있다. 이는 AI 개발에서 가장 큰 난제 중 하나였던 양질의 데이터 확보 문제를 해결할 수 있는 혁신적인 방안으로 주목받고 있다.
합성데이터가 AI 발전의 새로운 해법이 되는 이유
전통적인 AI 개발에서는 대량의 고품질 데이터 확보가 필수적이었다. 여기서 말하는 고품질 데이터란 다양성을 갖추고 인간의 의도에 부합하는 명확한 지도 신호(라벨)를 포함하는 데이터를 의미한다. 하지만 이러한 데이터를 인간이 직접 생성하는 것은 높은 비용과 시간이 소요될 뿐만 아니라, 데이터 희소성과 개인정보 보호 문제 등으로 인해 현실적으로 어려움이 많았다. 최근 연구들은 인간이 생성한 데이터가 편향과 오류에 취약할 수 있다는 점도 지적하고 있다.
LLM 기반 합성데이터의 생태계 구조
연구진이 제시한 LLM 기반 응용 생태계에서 합성데이터는 AI의 성장을 위한 핵심 영양분 역할을 한다. 이 생태계는 임상시험, 헬스케어 분석, 표 분석 등 다양한 영역을 포괄하며, 합성데이터는 소형 언어모델의 학습이나 특정 작업에 특화된 LLM의 미세조정에 활용된다. 또한 더 강력한 LLM을 훈련하거나 자체 개선을 위한 기반이 되는 순환적 구조를 가진다.
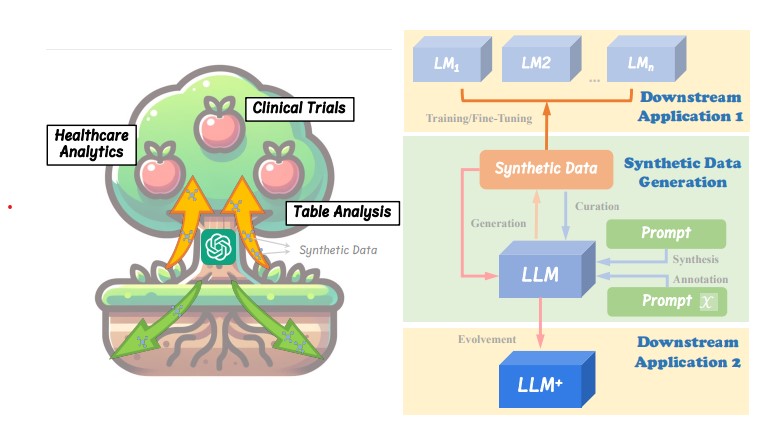
LLM이 만드는 합성데이터의 특장점
LLM은 방대한 사전학습을 통해 풍부한 지식과 뛰어난 언어 이해력을 보유하고 있어 신뢰할 수 있는 데이터 생성이 가능하다. 특히 LLM의 뛰어난 지시사항 준수 능력은 생성 과정의 제어가능성과 적응성을 높여주어, 특정 응용분야에 맞춤화된 데이터셋을 더욱 유연하게 설계할 수 있게 한다. 2024년 6월 기준으로 허깅페이스에는 ‘합성’이라는 태그가 붙은 데이터셋이 300개 이상 등록되어 있으며, 알파카(Alpaca), 비쿠나(Vicuna), 오픈헤르메스 2.5, 오픈챗 3.5 등 주요 LLM들도 고품질 합성데이터를 학습에 활용하고 있다.
합성데이터 생성의 세 가지 핵심 축
연구진은 합성데이터 관련 연구를 생성(Generation), 큐레이션(Curation), 평가(Evaluation)라는 세 가지 주요 영역으로 분류했다. 생성 단계에서는 프롬프트 엔지니어링과 다단계 생성 방식이 활용되며, 큐레이션 단계에서는 고품질 샘플 필터링과 라벨 개선이 이루어진다. 평가 단계는 직접 평가와 간접 평가 방식으로 나뉘어 데이터의 품질을 검증한다.
합성데이터의 생성은 단순해 보일 수 있지만, 높은 정확도와 충분한 다양성을 동시에 확보하기 위해서는 세심한 프로세스 설계가 필요하다. 연구진은 합성데이터의 품질을 직접적으로 평가하는 방법과 다운스트림 태스크에서의 효과성을 통해 간접적으로 평가하는 방법을 제시했다. 데이터의 충실도(Faithfulness)와 다양성(Diversity)이 주요 평가 기준이 되며, 이는 생성된 데이터가 실제 세계의 데이터 특성을 얼마나 잘 반영하는지를 측정하는 척도가 된다.
데이터 품질 관리의 혁신적 접근
합성데이터의 품질 관리를 위해 다양한 기법이 활용된다. 휴리스틱 메트릭을 활용한 필터링, 샘플 재가중치화, 학습 역학 기반 평가, 일관성 기반 평가 등이 대표적이다. 특히 인간의 재주석화나 보조 모델을 통한 개선 작업도 중요한 역할을 한다. 알파가수스(Alpagasus)의 사례는 더 작은 규모의 엄선된 데이터셋으로도 원래의 알파카(Alpaca) 모델보다 우수한 성능을 달성할 수 있음을 보여줬다.
실제 적용 사례와 벤치마크 현황
연구진이 제시한 벤치마크 데이터셋 분석에 따르면, SMS 스팸, AG 뉴스, IMDb, GoEmotions 등 다양한 분류 태스크부터 MATH, TruthfulQA와 같은 추론 태스크까지 광범위한 평가가 이뤄지고 있다. 특히 ToolBench는 LLM이 생성한 데이터셋으로, 도구 사용 능력 평가에 활용되며, NIV2는 1,616개의 태스크를, BIG-bench는 204개의 태스크를 포함하는 대규모 벤치마크다.
미래 발전 방향과 과제
연구진은 LLM 기반 합성데이터 생성 기술의 발전을 위해 몇 가지 중요한 연구 방향을 제시했다. 복잡한 작업 분해, 지식 강화, 대형 모델과 소형 모델 간의 시너지, 그리고 인간-모델 협력 등이 주요 연구 과제로 꼽혔다. 특히 데이터의 원천으로서 인공지능이 완전히 인간의 개입 없이 데이터를 생성하는 것은 불가능하며, 효과적인 인간-AI 협력 시스템 구축이 중요하다고 강조했다.
해당 리포트의 원문은 링크에서 확인할 수 있다.
기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기




![[Q&AI] 신지 결혼 상대 문원, 코요태 상견례 영상 공개 후 여론 악화… 왜?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-2.jpg)
