s1: Simple test-time scaling
1,000개 데이터로 o1 모델 능가… S1-32B 모델의 혁신적 성과
스탠포드와 워싱턴 대학교 연구진이 언어모델의 추론 능력을 향상시키는 새로운 방법을 발견했다. ‘Simple test-time scaling’ 논문에 따르면, 테스트 시간의 연산량을 늘리는 것만으로도 AI 모델의 성능을 크게 개선할 수 있다는 사실이 밝혀졌다.
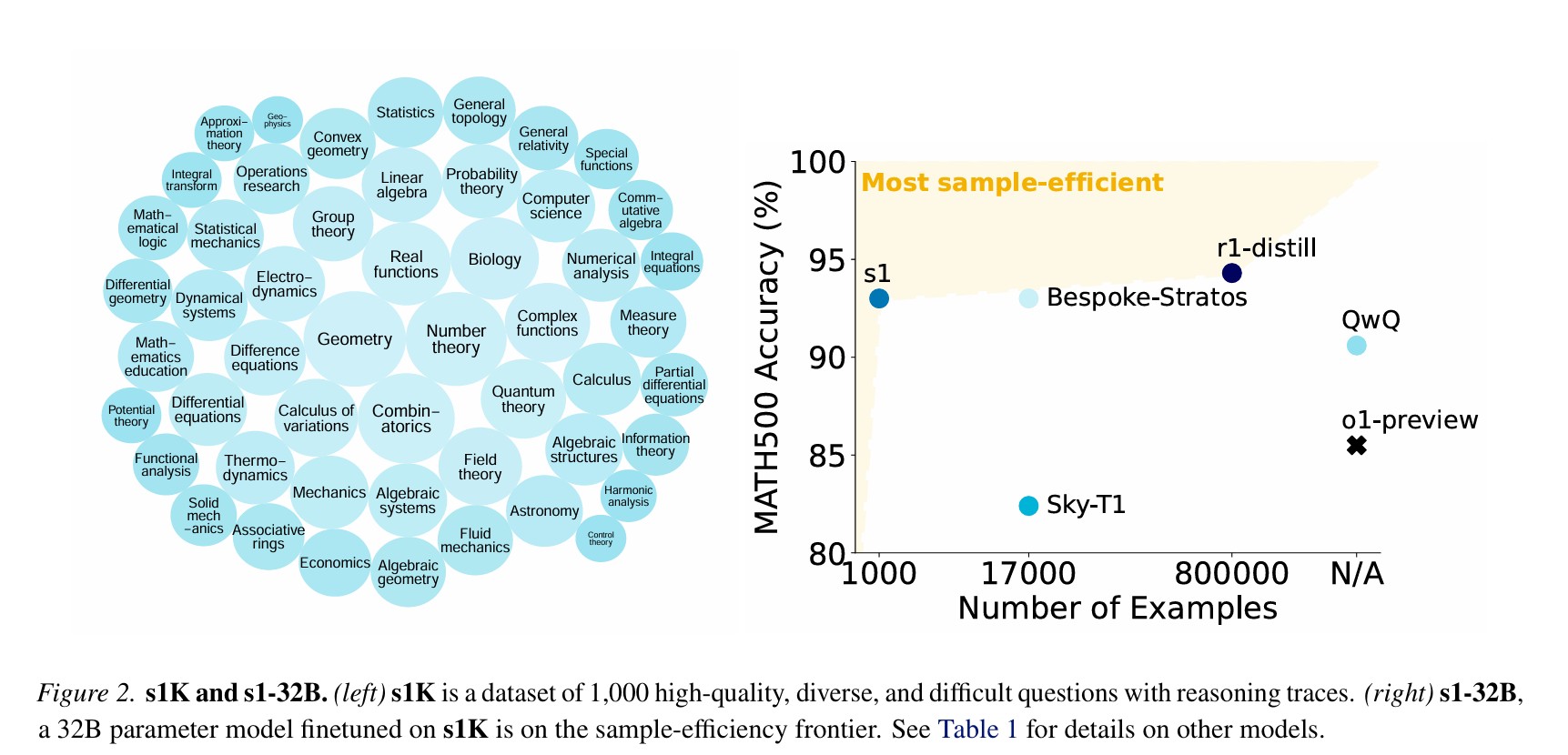
연구진은 겨우 1,000개의 데이터만으로도 높은 성능을 보이는 ‘S1-32B’ 모델을 개발했다. 이는 오픈AI의 ‘o1’ 모델과 비교했을 때 수학 경시대회 문제 해결 능력이 최대 27%까지 향상된 수준이다. 특히 주목할 만한 점은 기존의 o1 모델이 44.6%의 정답률을 보인 AIME24 문제에서 56.7%의 정답률을 달성했다는 것이다.
생각하는 시간이 길어질수록 성능도 향상… ‘예산 강제’ 기법의 혁신
연구진이 개발한 ‘예산 강제(budget forcing)’ 기법은 AI 모델의 사고 과정을 효과적으로 제어한다. 이는 두 가지 방식으로 작동하는데, 첫째는 모델이 설정된 토큰 수를 초과하면 강제로 생각을 멈추게 하는 것이고, 둘째는 ‘Wait’라는 단어를 추가하여 더 깊이 생각하도록 유도하는 것이다. 실제로 이 방식을 통해 모델은 “raspberry라는 단어에 r이 몇 개 있나요?”와 같은 간단한 질문에서도 처음에는 2개라고 답했다가, 더 생각할 시간을 주자 정답인 3개로 수정하는 모습을 보였다.
효율적인 데이터 선별로 학습 시간 26분으로 단축
연구진은 59,029개의 초기 데이터셋에서 세 가지 기준 – 난이도, 다양성, 품질 – 을 적용하여 최종 1,000개의 데이터를 선별했다. 이 과정에서 16개의 다양한 출처에서 데이터를 수집했으며, 수학, 물리학, 생물학, 컴퓨터 과학 등 50개 이상의 전문 분야를 포괄했다. 특히 스탠포드 대학의 통계학과 박사과정 입학시험 문제와 정량적 트레이딩 직무 면접 문제 등 고난도의 문제들도 포함시켰다.
연산 시간 증가에 따른 놀라운 성능 향상
연구팀의 실험 결과는 연산 시간과 성능 사이의 명확한 상관관계를 보여준다. MATH500 문제에서는 평균 생각 시간이 512토큰일 때 65%였던 정답률이 2048토큰으로 늘어나자 95%까지 상승했다. AIME24에서도 512토큰에서 8192토큰으로 생각 시간을 늘리자 정답률이 0%에서 60%까지 급상승했다. 박사급 과학 문제인 GPQA Diamond에서는 1024토큰에서 4096토큰으로 증가시켰을 때 40%에서 60%로 성능이 향상되었다.
테스트 시간 확장을 위한 다양한 방법론 연구
연구진은 테스트 시간 확장을 위해 순차적 확장과 병렬 확장이라는 두 가지 접근 방식을 실험했다. 순차적 확장은 이전 계산에 의존하여 더 깊은 추론과 반복적 개선을 가능하게 하는 방식이다. 반면 병렬 확장은 다수의 독립적인 해결 시도를 동시에 진행하는 방식이다. 실험 결과, AIME24 테스트에서 순차적 확장 방식은 2048토큰에서 8192토큰으로 생각 시간을 늘렸을 때 정확도가 30%에서 60%까지 향상되었다.
특히 연구진은 토큰 조건부 제어, 단계 조건부 제어, 클래스 조건부 제어 등 다양한 제어 방식을 실험했다. 그 중에서도 ‘Wait’ 문구를 추가하는 방식이 가장 효과적이었는데, 이는 모델이 답변을 수정하고 개선하는데 충분한 시간을 제공했기 때문이다. 연구진은 이러한 제어 방식의 효과를 Control(제어 가능성), Scaling(확장성), Performance(성능) 세 가지 지표로 평가했으며, 예산 강제 기법이 모든 지표에서 가장 우수한 성과를 보였다.
이는 기존의 대규모 강화학습 방식과는 다른 접근법으로, DeepSeek R1이나 다른 모델들이 수백만 개의 샘플과 여러 단계의 학습 과정을 필요로 했던 것과 대조된다. 연구진은 이러한 단순하면서도 효과적인 방법이 향후 AI 모델의 성능 향상에 새로운 방향을 제시할 것으로 기대하고 있다.
오픈소스로 공개된 혁신적 연구 성과
이번 연구의 특별한 점은 모든 코드와 데이터, 모델이 완전히 공개되었다는 것이다. 다른 연구자들도 깃허브를 통해 연구 결과를 확인하고 재현할 수 있으며, 이는 AI 연구의 투명성과 접근성을 높이는데 크게 기여할 것으로 기대된다. 게다가 16대의 H100 GPU로 단 26분 만에 학습이 가능하다는 점은, 앞으로 더 많은 연구자들이 이 분야에 참여할 수 있는 가능성을 열어주었다.
해당 기사에 인용된 논문 원문은 링크에서 확인 가능하다.
기사는 클로드 3.5 Sonnet과 챗GPT를 활용해 작성되었습니다.
관련 콘텐츠 더보기




![[Q&AI] 15억 로또 ‘올림픽파크포레온’ 청약 시작… 고려 사항은?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-4.jpg)