
Large language models surpass human experts in predicting neuroscience results
매년 기하급수적으로 증가하는 과학 문헌, AI가 해결사로
런던 유니버시티 칼리지(UCL)와 앨런 튜링 연구소 연구진이 발표한 논문에 따르면, 대규모 언어모델(LLM)이 뇌과학 연구 결과를 예측하는데 있어 전문가들의 능력을 크게 앞지른 것으로 나타났다. 연구진은 단일 연구가 불확실하거나 재현되지 않을 수 있는 상황에서, 수천 개의 관련 논문을 통합적으로 분석하여 새로운 결과를 예측할 수 있는 AI의 잠재력에 주목했다.
기존 AI 평가와 차별화된 ‘BrainBench’: 과거가 아닌 미래 예측에 초점
연구진이 개발한 ‘BrainBench’는 기존의 MMLU, PubMedQA, MedMCQA와 같은 ‘과거 지향적’ 벤치마크와 달리, 새로운 실험 결과를 예측하는 ‘미래 지향적’ 평가 도구다. 연구진은 AI의 ‘환각’ 현상이 과거 지향적 작업에서는 단점이지만, 미래 예측에서는 오히려 장점이 될 수 있다고 설명했다.
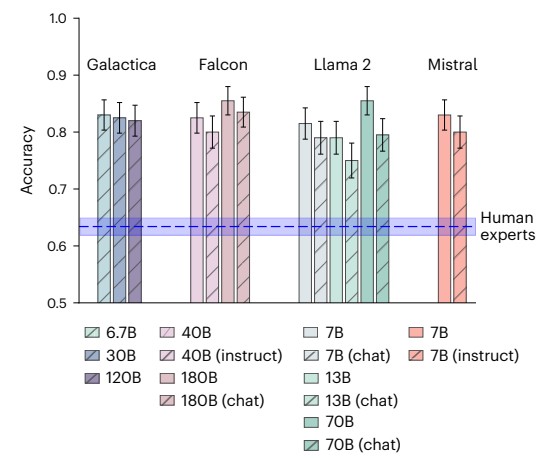
AI 모델들, 평균 81.4% 정확도로 전문가 능력 크게 상회
15개의 AI 모델을 평가한 결과, 평균 81.4%의 정확도를 기록했으며, 이는 전문가들의 63.4% 대비 현저히 높은 수준이었다(t(14) = 25.8, P < 0.001, Cohen’s d = 9.27). 특히 주목할 만한 점은 챗 형태나 지시어 최적화된 모델들이 기본 모델보다 오히려 낮은 성능(t(5) = 5.38, P = 0.002, Cohen’s d = 0.77)을 보였다는 것이다. 연구진은 자연어 대화에 최적화하는 과정이 오히려 과학적 추론 능력을 저하시켰을 수 있다고 분석했다.
또한 7B 파라미터의 Llama2-7B와 Mistral-7B 같은 소형 모델들도 대형 모델들과 비슷한 성능을 보였다. 이는 핵심 데이터 패턴을 포착하는 데 있어 반드시 거대한 모델이 필요하지 않을 수 있다는 점을 시사한다. 연구진은 GPT-4를 활용해 생성한 100개의 테스트 케이스에서도 비슷한 결과를 얻었다고 밝혔다.
아울러 실험에 참여한 171명의 전문가들 중에서도 상위 20%의 전문성을 가진 참가자들의 정확도는 66.2%에 그쳤는데, 이는 여전히 AI 모델들의 성능에 미치지 못하는 수준이었다. 이러한 결과는 AI가 뇌과학 분야의 실험 결과 예측에서 이미 최고 수준의 전문가들의 능력을 뛰어넘었음을 보여준다.
1.3억 개 논문으로 학습한 BrainGPT, 기존 AI보다 3% 더 정확
연구팀은 Mistral-7B 모델을 기반으로 2002년부터 2022년까지의 뇌과학 논문 데이터로 ‘BrainGPT’를 개발했다. 332,807개의 초록과 123,085개의 전문 논문에서 추출한 13억 개의 토큰으로 학습된 이 모델은 기존 AI 대비 3% 향상된 성능을 보여주었다.
맥락 이해 능력 검증: 결과만으론 부족, 방법론 포함한 전체 맥락 필요
AI의 성능이 단순 암기가 아닌 맥락 이해에서 비롯됐음을 입증하기 위해, 연구진은 세 가지 실험을 진행했다. 첫째, 결과 부분만 제시했을 때와 전체 맥락을 제공했을 때의 성능을 비교했다. 전체 맥락이 주어졌을 때 AI는 최고 성능을 보였으며, 결과 부분만 주어졌을 때는 성능이 크게 저하됐다.
둘째, 동일한 신경과학 하위 분야 내에서 무작위로 문장을 교체한 초록으로 테스트를 진행했다. 원본 초록과 수정된 초록 모두에 이 방식을 적용했는데, 이 경우 AI의 성능이 현저히 감소했다. 이는 AI가 단순히 해당 분야의 일반적 맥락만으로는 정확한 예측을 할 수 없으며, 특정 연구와 관련된 구체적인 맥락 정보가 필요하다는 것을 보여준다.
마지막으로, AI와 인간 전문가들이 어려워하는 문제들을 비교 분석했다. AI 모델들 간의 난이도 평가 상관관계는 0.75(±0.08)로 매우 높았지만, AI와 인간 전문가들 사이의 상관관계는 0.15(±0.03)에 그쳤다. 이는 AI와 인간이 서로 다른 방식으로 문제에 접근한다는 것을 시사하며, 이러한 차이가 AI와 인간의 상호 보완적 협력 가능성을 보여준다.
5개 뇌과학 영역 모두에서 전문가 능력 초월
BrainBench는 뇌과학의 주요 하위 분야를 포괄적으로 다루도록 설계됐다. 테스트 케이스는 행동/인지(37.5%), 시스템/회로(25.5%), 질병 신경생물학(12.5%), 세포/분자(12.5%), 발달/가소성/복구(12%)의 비율로 구성됐는데, 이는 저널 오브 뉴로사이언스(Journal of Neuroscience)의 실제 논문 분포와 유사하게 설정됐다. 특히 행동/인지 분야가 가장 큰 비중을 차지하는 것이 특징이다.
실험에 참여한 전문가들의 구성도 다양했다. 박사후연구원(29.8%), 교수진/학계 연구원(25.3%), 박사과정생(25.2%), 학부생(10.2%), 연구 과학자(7.1%), 기타(2.4%) 등 다양한 경력 수준의 전문가들이 참여했다. 참가자들의 평균 뇌과학 연구 경력은 10.1년이었다.
주목할 만한 점은 모든 AI 모델들이 모든 하위 분야에서 일관되게 인간 전문가들의 성능을 상회했다는 것이다. 이는 특정 분야에 국한되지 않는 AI의 범용적 능력을 입증한다. 또한 전문가들의 자기 평가 전문성 수준과 실제 성과 사이의 관계도 분석됐는데, 특정 분야에서 높은 전문성을 가진 것으로 자평한 전문가들의 경우에도 AI의 성능에는 미치지 못했다.
자신감 평가에서도 전문가급 판단력 보여
AI의 예측 신뢰도 평가 능력을 검증하기 위해 연구진은 AI 모델들의 perplexity(당혹도) 차이값을 활용했다. 두 개의 초록 버전에 대한 perplexity 차이가 클수록 AI가 해당 예측에 대해 더 확신하는 것으로 해석했다. 연구 결과, AI의 확신도와 정확도 사이의 상관관계는 0.75(±0.08)로 나타났으며, 이는 인간 전문가들의 상관관계 0.15(±0.03)보다 훨씬 높은 수준이었다.
모든 AI 모델들은 인간 전문가들과 마찬가지로 높은 확신을 보인 예측에서 더 정확한 결과를 보여주었다. 연구진은 로지스틱 회귀 분석을 통해 모델의 perplexity 차이값과 정확도, 그리고 인간의 확신도와 정확도 사이의 관계를 분석했다. 분석 결과, AI와 인간 모두 통계적으로 유의미한 양의 상관관계를 보였다(상세 데이터는 논문의 Supplementary Table 3 참조).
이러한 신뢰도 평가 능력은 AI를 실제 연구에 활용할 때 매우 중요한 특성이다. AI가 자신의 예측에 대한 확신도를 정확하게 평가할 수 있다는 것은, 연구자들이 AI의 제안을 선별적으로 수용하는 데 도움을 줄 수 있기 때문이다. 또한 AI와 인간이 상호 보완적으로 협력하는 앙상블 시스템을 구축할 때도 이러한 특성이 핵심적인 역할을 할 수 있다.
미래 과학 연구의 새로운 조력자로 부상한 LLM
연구진은 이번 연구가 AI가 과학 문헌의 패턴을 학습해 새로운 실험 결과를 예측하는 능력을 입증했다고 평가했다. 특히 BrainGPT가 보여준 성과는 AI가 과학적 발견을 가속화하고, 연구자들의 실험 설계를 지원하는 도구로 발전할 수 있음을 시사한다.
해당 기사에 인용된 논문 원문은 링크에서 확인 가능하다.
기사는 클로드 3.5 Sonnet과 챗GPT를 활용해 작성되었습니다.
관련 콘텐츠 더보기


![[Q&AI] 15억 로또 ‘올림픽파크포레온’ 청약 시작… 고려 사항은?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-4.jpg)