
DETECTING STYLISTIC FINGERPRINTS OF LARGE LANGUAGE MODELS
대형 언어 모델의 독특한 스타일 ‘지문’ 존재 증명
대형 언어 모델(LLM)은 다양한 작문 스타일로 글쓰기를 요청받더라도 독특하고 일관된 스타일 ‘지문’을 가지고 있다. 이러한 스타일 지문을 탐지하는 것은 지적 재산권 보호, AI 생성 콘텐츠에 대한 투명성 확보, AI 기술의 오용 방지 등 여러 이유로 중요하다. AI 기반 텍스트 분석 플랫폼 카피릭스(Copyleaks)의 연구진은 이런 스타일 지문을 기반으로 텍스트 분류를 위한 새로운 방법을 개발했다. 여러 도메인에서도 일관성을 유지하며 다양한 글쓰기 스타일로 작성을 요청받더라도 이러한 지문은 계속 존재한다. LLM의 매우 안정적인 스타일 프로필은 훈련, 미세 조정, 텍스트 생성 과정의 결정론적 특성 때문이다.
3개 분류기로 구성된 앙상블 시스템의 높은 정확도
연구팀은 클로드(Claude), 제미나이(Gemini), 라마(Llama), 오픈AI(OpenAI) 등 4개 주요 LLM 계열이 생성한 텍스트를 분류하기 위한 LLM 탐지 앙상블을 도입했다. 이 앙상블은 다양한 아키텍처와 훈련 데이터를 가진 3개의 분류기로 구성되어 있다. 이 작업은 매우 비용에 민감하고 심각한 영향을 미칠 수 있기 때문에, 연구팀은 거짓 양성(false-positive)을 최소화하고 신뢰도를 높이는 데 중점을 두었다. 앙상블의 세 분류기 모두가 출력 분류에 만장일치로 동의할 때만 예측을 유효한 것으로 간주했다.
이 앙상블은 클로드, 제미나이, 라마, 오픈AI 모델이 생성한 텍스트로 구성된 테스트 세트에서 검증되었으며, 매우 높은 정밀도(0.9988)와 매우 낮은 거짓 양성률(0.0004)을 달성했다. 이는 다른 개별 분류기나 다수결 투표 방식보다 우수한 성능을 보여주는 것이다. 다만 이 앙상블의 단점은 약 1%의 텍스트에 대해 ‘합의 없음’ 분류를 도입하여 예측이 더 보수적이라는 점이다.
DeepSeek-R1의 텍스트 74.2%, 챗GPT가 작성한 것으로 분류
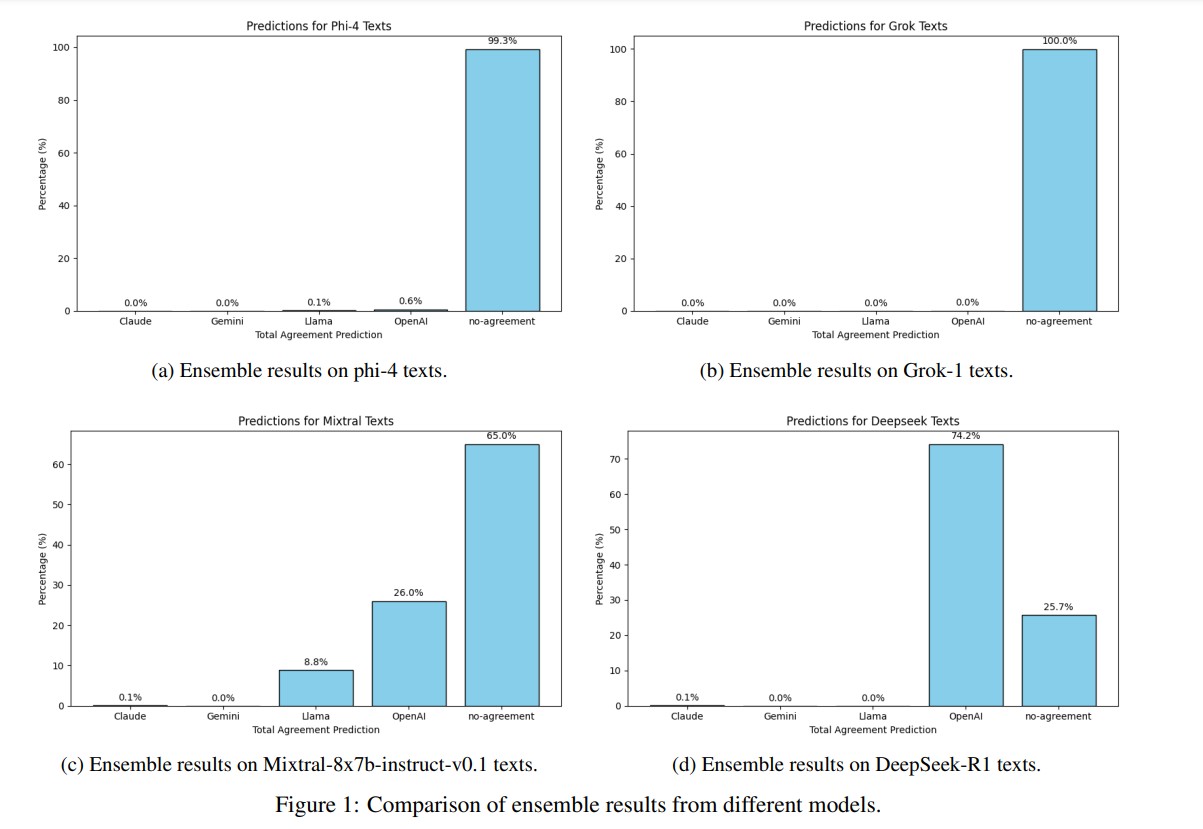
연구팀은 훈련 데이터에 포함되지 않은 LLM에서 앙상블의 일반화 능력을 평가했다. phi-4, Grok-1, Mixtral-8x7b-instruct-v0.1, DeepSeek-R1 등 네 가지 보이지 않는 LLM으로 생성된 텍스트에 앙상블을 적용했다.
그 결과 phi-4 모델의 경우 99.3%, Grok-1 모델의 경우 100%의 텍스트에서 앙상블이 합의에 도달하지 못했다. 이는 이 모델들이 훈련된 네 가지 LLM과 매우 다른 스타일 지문을 가지고 있음을 시사한다. Mixtral 모델의 경우 65%의 텍스트에서 합의에 도달하지 못했고, 26%는 오픈AI가 작성한 것으로, 8.8%는 Llama가 작성한 것으로 식별되었다. 놀랍게도 DeepSeek-R1 모델의 텍스트 중 74.2%가 오픈AI의 챗GPT가 작성한 것으로 분류되었는데, 이는 두 LLM 간의 강한 스타일적 유사성을 시사한다.
LLM 저작자 식별을 위한 기술 발전 필요
이 연구는 저작자 식별과 AI 포렌식 전략 및 기술을 결합하여 특정 LLM 지문을 탐지하고 분류하는 방법을 개발했다. 이러한 방식은 AI 생성 텍스트 검증 영역에 크게 기여하며, 지적 재산권 보호, AI의 투명하고 공정한 사용 촉진, LLM의 진화 추적, 글쓰기의 공정성 증진에 중요하다.
앞으로 연구팀은 다양한 LLM 분류, 더 많은 유형의 분류기, 더 많은 언어, 더 다양한 앙상블 방법을 탐색할 계획이다. 이를 통해 LLM 저작자 식별을 위한 더 설명 가능하고 일반화 가능한 방법을 개발할 것으로 기대된다.
FAQ
Q: 대형 언어 모델(LLM)의 스타일 지문이란 무엇인가요?
A: LLM 스타일 지문은 각 AI 모델이 텍스트를 생성할 때 나타나는 독특하고 일관된 언어적 특징을 말합니다. 이 특징은 모델의 훈련, 미세 조정, 텍스트 생성 과정에서 형성되며, 다양한 주제나 요청된 작문 스타일에도 불구하고 일관되게 나타납니다.
Q: 이 기술이 왜 중요한가요?
A: 이 기술은 AI 생성 콘텐츠의 투명성을 높이고, 지적 재산권을 보호하며, AI 기술의 오용을 방지하는 데 도움이 됩니다. 또한 모델 간의 숨겨진 유사성을 감지하여 모델 증류나 무단 모델 재사용과 같은 사례를 식별하는 데 활용될 수 있습니다.
Q: 앙상블 접근 방식이 단일 분류기보다 더 효과적인 이유는 무엇인가요?
A: 앙상블 접근 방식은 여러 다양한 분류기의 결합된 결정이 오류가 적어도 어느 정도 상관관계가 없고 각 개별 모델의 오류율이 0.5보다 낮을 때 단일 모델보다 더 정확합니다. 특히 만장일치 투표 전략은 정밀도를 높이고 거짓 양성률을 크게 낮출 수 있어 비용에 민감한 이 작업에 적합합니다.
해당 기사에서 인용한 논문 원문은 링크에서 확인할 수 있다.
기사는 클로드와 챗GPT를 활용해 작성되었습니다.
관련 콘텐츠 더보기



![[Q&AI] 오늘 밤 한일전... AI가 예측한 승률은?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-7.jpg)

