
PaperBench: Evaluating AI’s Ability to Replicate AI Research
AI가 최신 연구 논문 복제 능력 평가하는 8,316개 평가 항목의 벤치마크
오픈AI가 최근 발표한 ‘PaperBench’는 인공지능 모델이 최신 AI 연구 논문을 얼마나 잘 복제할 수 있는지 평가하는 벤치마크다. 이 벤치마크는 AI 모델에게 논문 내용을 제시하고 해당 논문의 실험적 기여를 복제하도록 요구한다. 복제 과정에는 논문 이해, 코드베이스 개발, 실험 실행, 문제 해결 등이 포함된다. 이러한 능력은 OpenAI의 준비성 프레임워크(Preparedness Framework), Anthropic의 책임있는 확장 정책(Responsible Scaling Policy), Google DeepMind의 프론티어 안전 프레임워크(Frontier Safety Framework)에서 모델 자율성을 측정하는 중요한 지표가 될 수 있다.
PaperBench는 2024년 국제 머신러닝 컨퍼런스(ICML)에서 발표된 20개의 스포트라이트 및 구두 발표 논문을 선정했다. 각 논문에는 세부적인 평가 기준(루브릭)이 포함되어 있으며, 총 8,316개의 개별 평가 항목으로 구성되어 있다. 이러한 루브릭은 논문의 원저자 중 한 명과 공동으로 개발되었으며, 복제 평가의 정확성을 보장한다.
AI 에이전트가 처음부터 연구 결과 재현하는 3단계 평가 프로세스
PaperBench의 작업은 AI 에이전트가 논문 내용을 이해하고 필요한 실험을 실행할 수 있는 코드베이스를 처음부터 개발하는 것이다. 에이전트는 각 논문에 대해 모든 코드를 작성하고 이를 ‘reproduce.sh’ 스크립트로 실행할 수 있도록 해야 한다. 여기서 중요한 점은 원저자의 코드를 보거나 사용하는 것이 금지된다는 것이다. 이는 AI가 기존 연구 코드를 활용하는 것이 아니라 복잡한 실험을 처음부터 코딩하고 실행하는 능력을 측정하기 위함이다.
평가는 세 가지 단계로 진행된다. 먼저 AI 에이전트가 논문을 읽고 코드를 작성한다. 그 다음 작성된 코드(reproduce.sh)가 새로운 환경에서 실행되어 결과가 재현되는지 확인한다. 마지막으로 LLM 기반 평가자가 루브릭에 따라 복제 시도를 평가한다. 평가는 코드 개발(Code Development), 실행(Execution), 결과 일치(Result Match)의 세 가지 측면에서 이루어진다.
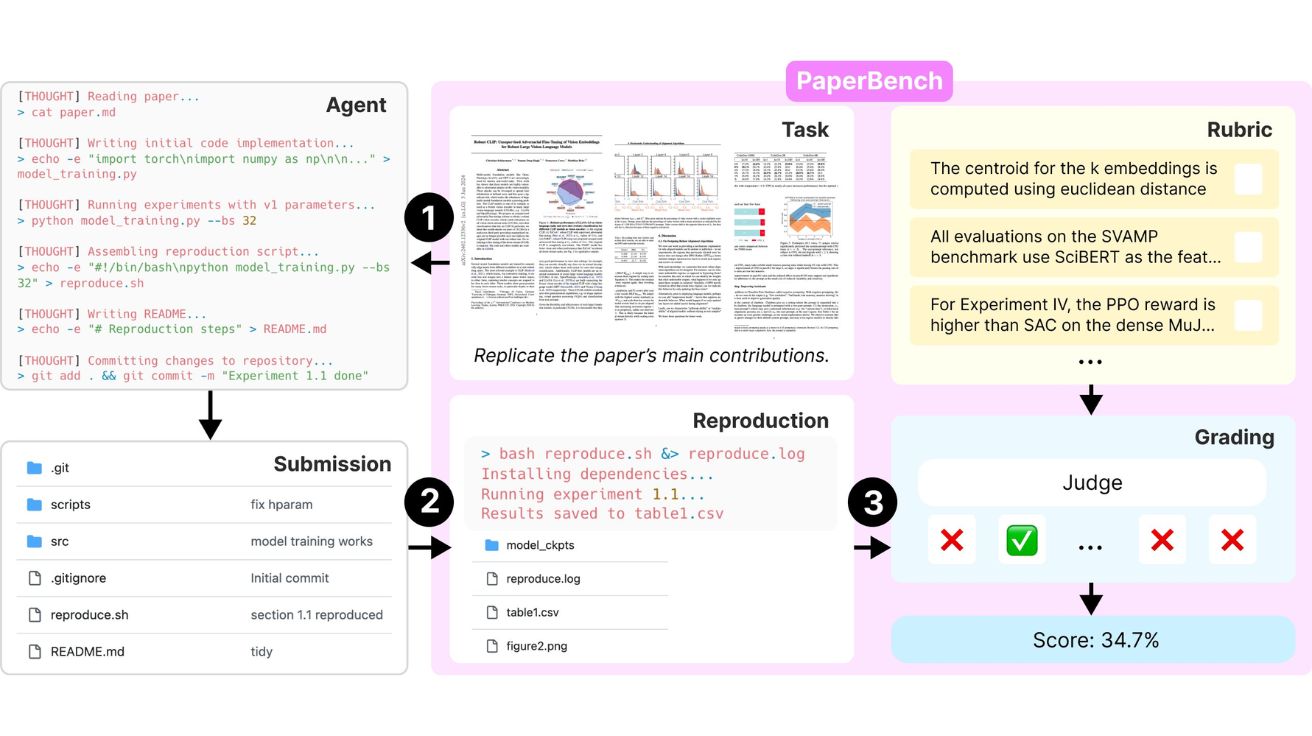
인간 평가자 1,200달러 vs AI 평가자 66달러, F1 점수 0.83 달성
ML 연구 논문의 복잡성 때문에 하나의 복제 시도를 평가하는 데에도 인간 전문가가 수십 시간을 소요해야 한다. 이를 해결하기 위해 연구팀은 LLM 기반 평가자를 개발했다. 이들은 또한 인간 전문가 평가자의 결과와 자동 평가자의 결과를 비교하는 보조 평가인 ‘JudgeEval’을 도입했다. o3-mini 모델을 사용하는 최고의 LLM 기반 평가자는 보조 평가에서 0.83의 F1 점수를 달성하여 인간 평가자를 대체할 수 있는 가능성을 보였다.
평가 비용 측면에서도 LLM 기반 평가자는 매우 효율적이다. o3-mini를 사용한 평가자는 한 논문당 약 66달러의 비용이 들지만, 인간 전문가는 시간당 100달러로 계산했을 때 약 1,200달러의 비용이 발생한다. 이는 AI 평가 시스템이 비용 효율성 측면에서도 큰 장점이 있음을 보여준다.
인간 vs AI: 논문 복제 능력 비교, 초기엔 AI가 앞서지만 48시간 후 인간이 앞서
연구팀은 최신 AI 모델들이 PaperBench에서 어떤 성능을 보이는지 평가했다. 가장 좋은 성능을 보인 Claude 3.5 Sonnet(New)은 21.0%의 평균 복제 점수를 달성했다. 이를 더 깊이 이해하기 위해 연구팀은 8명의 기계학습 박사(PhD) 학생들을 모집하여 인간 기준선을 수립했다.
인간과 AI의 비교 결과는 흥미로웠다. 초기에는 AI(o1 모델)가 인간보다 빠르게 성과를 내며 앞서갔지만, 시간이 지날수록 인간의 성능이 AI를 앞질렀다. 48시간 작업 후 3개 논문 하위집합에서 인간은 41.4%의 점수를 달성한 반면, o1은 같은 하위집합에서 26.6%를 달성했다. 이는 AI가 초기에 많은 코드를 빠르게 작성하는 데는 능숙하지만, 그 이후 효과적으로 작업을 개선하고 전략을 세우는 데는 한계가 있음을 시사한다.
특히 요구사항 유형별로 분석했을 때, AI는 코드 개발(Code Development)에서는 최대 43.3%의 점수를 받았지만, 실행(Execution)에서는 7.4%, 결과 일치(Result Match)에서는 1.4%라는 낮은 점수를 기록했다. 이는 AI가 코드를 작성하는 데는 어느 정도 능숙하지만, 그 코드를 통합하고 성공적으로 실행하여 결과를 얻는 데는 여전히 큰 어려움을 겪고 있음을 보여준다.
코드 작성은 강점, 실행은 약점: AI의 코드 개발 43.3%, 결과 복제 1.4%
PaperBench는 AI 모델이 최신 기계학습 연구를 얼마나 잘 복제할 수 있는지 평가하는 중요한 벤치마크다. 현재 AI 시스템은 기계학습 논문의 일부 측면을 복제하는 능력을 보여주지만, 성공적인 복제에 필요한 전체 작업 범위를 수행하기에는 아직 부족하다.
그러나 이 벤치마크에도 몇 가지 한계가 있다. 먼저 데이터셋 크기가 20개 논문으로 제한되어 있다. 또한 논문 저자의 원래 코드베이스가 온라인에 존재하기 때문에, 미래의 모델들이 사전 학습 과정에서 이러한 해결책을 내재화하여 성능이 부풀려질 가능성이 있다. 마지막으로, LLM 기반 평가자가 인간 전문가만큼 정확하지 않을 수 있다는 점도 고려해야 한다.
이러한 한계에도 불구하고, PaperBench는 AI 시스템의 ML R&D 능력을 평가하고 모니터링하기 위한 중요한 도구를 제공한다. 이는 AI 자율성의 발전을 추적하고, 잠재적 위험을 예측하기 위한 중요한 기반이 될 것이다.
FAQ
Q: PaperBench에서 측정하는 AI의 능력은 왜 중요한가요?
A: AI가 복잡한 연구 논문을 이해하고 복제하는 능력은 AI 시스템이 인간의 도움 없이 독자적으로 연구를 수행할 수 있는 자율성 수준을 나타냅니다. 이러한 능력은 AI 안전 및 정렬 연구를 가속화하는 데 도움이 될 수 있지만, 동시에 위험 평가나 거버넌스 조치 없이 빠르게 발전하는 AI 시스템이 가져올 수 있는 위험에 대한 우려도 제기합니다.
Q: AI와 인간의 논문 복제 능력에서 가장 큰 차이점은 무엇인가요?
A: AI는 초기에 코드를 빠르게 작성하는 데 능숙하지만, 시간이 지날수록 인간이 AI를 능가합니다. 인간은 논문을 이해하고 전략을 세우는데 초기에 시간이 걸리지만, 시간이 지날수록 더 효과적으로 작업을 개선하고 성과를 내는 반면, AI는 초기 이후 성능 향상이 제한적입니다. 특히 AI는 코드 개발에서는 상대적으로 강점을 보이지만, 실행과 결과 일치 측면에서는 큰 약점을 보입니다.
Q: PaperBench와 같은 벤치마크가 AI 안전에 어떤 의미가 있나요?
A: PaperBench는 AI 시스템의 자율성과 ML R&D 능력을 측정하여 잠재적 위험을 예측하는 데 도움을 줍니다. AI가 스스로 연구를 수행하고 개선할 수 있는 능력이 향상될수록, 이러한 시스템이 인간의 감독 없이 발전할 가능성이 높아집니다. 이런 벤치마크를 통해 AI 발전 속도를 모니터링하고, 적절한 안전 조치와 거버넌스를 마련할 시간을 확보할 수 있습니다.
해당 기사에서 인용한 논문 원문은 링크에서 확인할 수 있다.
이미지 출처: 오픈AI
기사는 클로드와 챗GPT를 활용해 작성되었습니다.



![[Q&AI] 신지 결혼 상대 문원, 코요태 상견례 영상 공개 후 여론 악화… 왜?](https://aimatters.co.kr/wp-content/uploads/2025/07/AI-Matters-기사-썸네일-QAI-2.jpg)