인공지능(AI) 기술이 발전하면서 AI가 생성한 데이터로 새로운 AI 모델을 학습시키는 일이 늘고 있다. 하지만 이런 방식으로 계속 AI를 학습시키면 모델의 품질과 다양성이 저하되는 ‘모델 자가포식 장애(Model Autophagy Disorder, MAD)’에 빠질 수 있다는 연구 결과가 나왔다.
라이스대학교 연구팀은 AI 생성 데이터로 반복해서 AI 모델을 학습시키는 ‘자가포식 루프(autophagous loop)’ 현상을 분석했다. 연구 결과, 실제 데이터 주입 없이 AI 생성 데이터만으로 모델을 계속 학습시키면 몇 세대 만에 품질이 현저히 떨어지는 것으로 나타났다. 논문에 제시된 이미지에 따르면, 9세대에 걸쳐 이미지 품질의 점진적인 저하가 관찰되었다. 이 연구는 국제 학습 표현 학회(ICLR) 2024에서 발표될 예정이다.
연구팀은 이러한 현상을 인간의 광우병에 빗대어 ‘MAD’라고 명명했다. MAD에 걸린 AI 모델은 생성하는 이미지의 품질(정밀도)이 떨어지거나 다양성(재현율)이 감소하는 증상을 보였다.
자가포식 루프의 세 가지 유형
연구팀은 세 가지 유형의 자가포식 루프를 분석했다:
- 완전 합성 루프: 오직 AI 생성 데이터로만 학습
- 합성 증강 루프: 고정된 실제 데이터와 AI 생성 데이터로 학습
- 신선한 데이터 루프: 매번 새로운 실제 데이터와 AI 생성 데이터로 학습
분석 결과, 완전 합성 루프에서는 MAD 증상이 가장 빨리 나타났다. 합성 증강 루프에서는 MAD 진행 속도가 느려졌지만 여전히 품질 저하를 막지 못했다. 신선한 데이터 루프에서만 충분한 양의 새로운 실제 데이터를 주입했을 때 MAD를 예방할 수 있었다.
이미지로 보는 MAD 현상
연구팀은 StyleGAN2라는 AI 모델을 사용해 얼굴 이미지를 생성하는 실험을 진행했다. 이 실험 결과를 보여주는 이미지는 MAD 현상을 시각적으로 잘 보여준다.
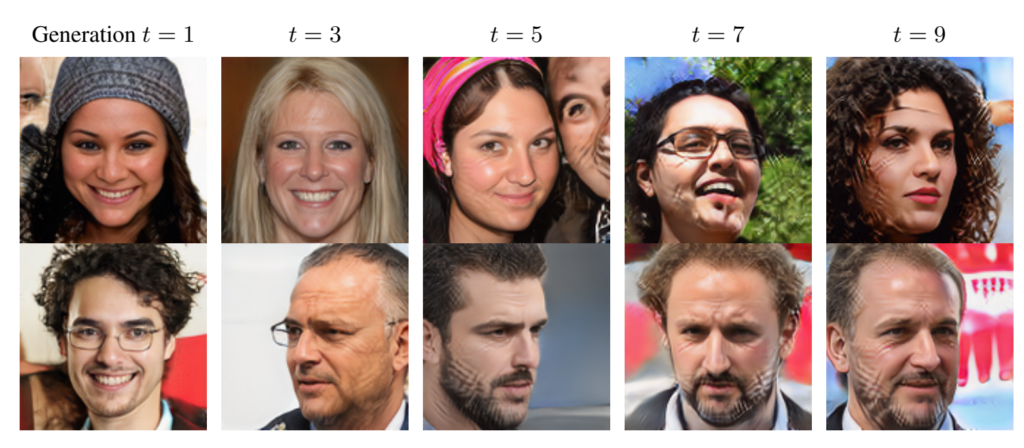
MAD 현상의 진행
이 이미지는 세대가 거듭될수록 생성된 얼굴 이미지의 품질이 저하되고 다양성이 감소하는 것을 보여준다. 첫 번째 세대에서는 상대적으로 선명하고 다양한 얼굴 이미지가 생성되지만, 다섯 번째 세대에서는 이미지에 노이즈가 증가하고 특정 패턴이 반복되기 시작한다. 아홉 번째 세대에 이르면 이미지 품질이 현저히 떨어지고, 생성되는 얼굴의 다양성도 크게 감소한다.
특히 주목할 만한 점은 세대가 지날수록 이미지에 격자 무늬 같은 인공적인 패턴이 점점 더 두드러지게 나타난다는 것이다. 이는 AI 모델이 이전 세대의 오류나 특징을 학습하고 증폭시키는 현상을 보여준다.

샘플링 편향의 영향
연구팀은 또한 ‘샘플링 편향(sampling bias)’이 MAD 현상에 미치는 영향을 분석했다. 샘플링 편향은 AI 모델이 데이터를 생성할 때 특정 품질 기준을 충족하는 샘플만을 선별하는 것을 의미한다.
실험 결과, 샘플링 편향을 적용하면 생성된 이미지의 품질은 어느 정도 유지할 수 있었지만, 다양성은 더 빠르게 감소하는 것으로 나타났다. 이는 AI 개발자들이 모델의 성능을 향상시키기 위해 흔히 사용하는 기법이 오히려 장기적으로는 모델의 다양성을 해칠 수 있음을 시사한다.
MAD 현상의 위험성
연구팀은 “AI 생성 데이터가 인터넷상에 급증하고 있어 향후 AI 모델 학습에 무분별하게 사용될 경우 전체 인터넷 데이터의 품질과 다양성을 해칠 수 있다”고 경고했다.
이는 단순히 AI 모델의 성능 저하 문제를 넘어서는 심각한 위험을 내포하고 있다. 예를 들어, 뉴스 기사나 학술 정보를 생성하는 AI 모델이 MAD 현상으로 인해 품질이 저하된다면, 이는 정보의 정확성과 신뢰성에 큰 타격을 줄 수 있다. 또한, 의료 영상 분석이나 자율주행차량의 환경 인식 등 중요한 의사결정에 사용되는 AI 모델의 경우, MAD로 인한 성능 저하는 심각한 안전 문제로 이어질 수 있다.
더욱이 AI 생성 콘텐츠의 다양성이 감소하면, 이는 장기적으로 인터넷상의 정보 다양성 전반에 영향을 미칠 수 있다. 이는 문화적 다양성 감소나 창의성 저하로 이어질 수 있는 심각한 문제다.
MAD 예방을 위한 제안
연구팀은 MAD 현상을 예방하기 위한 여러 방안을 제시했다. 우선, AI 모델 학습 시 가능한 한 많은 실제 데이터를 사용해야 한다고 강조했다. 특히 ‘신선한 데이터 루프’ 방식을 채택하여 매 학습 단계마다 새로운 실제 데이터를 주입하는 것이 중요하다고 설명했다.
또한, 전체 학습 데이터 중 AI 생성 데이터의 비율을 적절히 조절해야 한다고 제안했다. 연구 결과에 따르면, 실제 데이터 대비 AI 생성 데이터의 비율이 일정 수준을 넘어서면 모델의 성능이 저하되기 시작한다는 것이다.
샘플링 편향 관리도 중요한 요소로 꼽았다. 품질 향상을 위한 샘플링 편향을 적용할 때는 다양성 감소에 주의해야 하며, 편향의 정도를 적절히 조절하고 다양성을 유지하기 위한 추가적인 전략이 필요할 수 있다고 언급했다.
연구팀은 또한 AI 모델의 성능, 특히 생성 결과의 품질과 다양성을 정기적으로 평가해야 한다고 조언했다. MAD 증상이 나타나기 시작하면 즉시 대응 조치를 취해야 한다는 것이다.
마지막으로, 학습 데이터셋에서 AI 생성 데이터를 식별하고 필터링할 수 있는 기술 개발의 필요성을 강조했다. 이를 통해 실제 데이터와 AI 생성 데이터의 비율을 더욱 정확하게 관리할 수 있다고 설명했다.
결론
이번 연구 결과는 AI 기술의 발전 방향에 중요한 시사점을 제공한다. AI가 생성한 데이터로 다시 AI를 학습시키는 현재의 추세가 지속된다면, 우리는 머지않아 AI 모델들의 ‘집단 광기’와 같은 상황에 직면할 수 있다.
따라서 AI 개발자들은 모델 학습 시 실제 데이터와 AI 생성 데이터의 비율을 신중히 고려해야 한다. 특히 의료 영상 등 실제 데이터 확보가 어려운 분야에서 AI 생성 데이터 활용 시 더욱 주의가 필요할 것이다.
또한 정책 입안자들은 AI 생성 데이터의 무분별한 확산을 막고, 고품질의 실제 데이터 확보를 위한 제도적 장치를 마련해야 할 것이다. AI 기술의 건강한 발전을 위해서는 산학연 모두의 협력과 지속적인 연구가 필요한 시점이다.
라이스대학교 연구팀의 논문은 링크에서 확인할 수 있다.
본 기사는 클로드 3.5 Sonnet과 챗GPT-4o를 활용해 작성되었습니다.
관련 콘텐츠 더보기