LLMs Get Lost In Multi-Turn Conversation
대화가 길어질수록 39% 성능 급락: 최신 AI도 피해가지 못하는 ‘대화 길 잃기’ 현상
대형 언어 모델(LLM)들이 다중 대화(multi-turn conversation) 상황에서 단일 대화(single-turn conversation)에 비해 평균 39%의 성능 하락을 보이는 것으로 나타났다. 마이크로소프트 리서치와 세일즈포스 리서치 연구진이 발표한 새로운 논문에 따르면, 현재 최고 수준의 오픈소스 및 상업용 LLM 모두 다중 대화 상황에서 ‘Lost in Conversation(대화 속 길 잃기)’ 현상을 보였다.
연구진은 마이크로소프트와 세일즈포스 소속 필립 라반(Philippe Laban), 히로아키 하야시(Hiroaki Hayashi) 등이 주도했으며, 이들은 코드 생성, 데이터베이스 쿼리, API 호출, 수학 문제 풀이, 데이터-텍스트 변환, 요약 등 6개의 생성 태스크에서 15개 주요 LLM 모델의 다중 대화 성능을 테스트했다. 테스트 대상에는 OpenAI의 GPT-4o, o3, GPT-4.1, Anthropic의 Claude 3 Haiku와 Claude 3.7 Sonnet, Google의 Gemini 2.5 Flash와 Pro, Meta의, OLMo2-13B, Microsoft의 Phi-4, Deepseek-R1, Cohere Command-A 등 현재 시장에서 가장 발전된 모델들이 포함되었다.
20만 건 대화 분석 결과: 능력 손실(-15%)보다 신뢰성 급락(+112%)이 핵심 문제
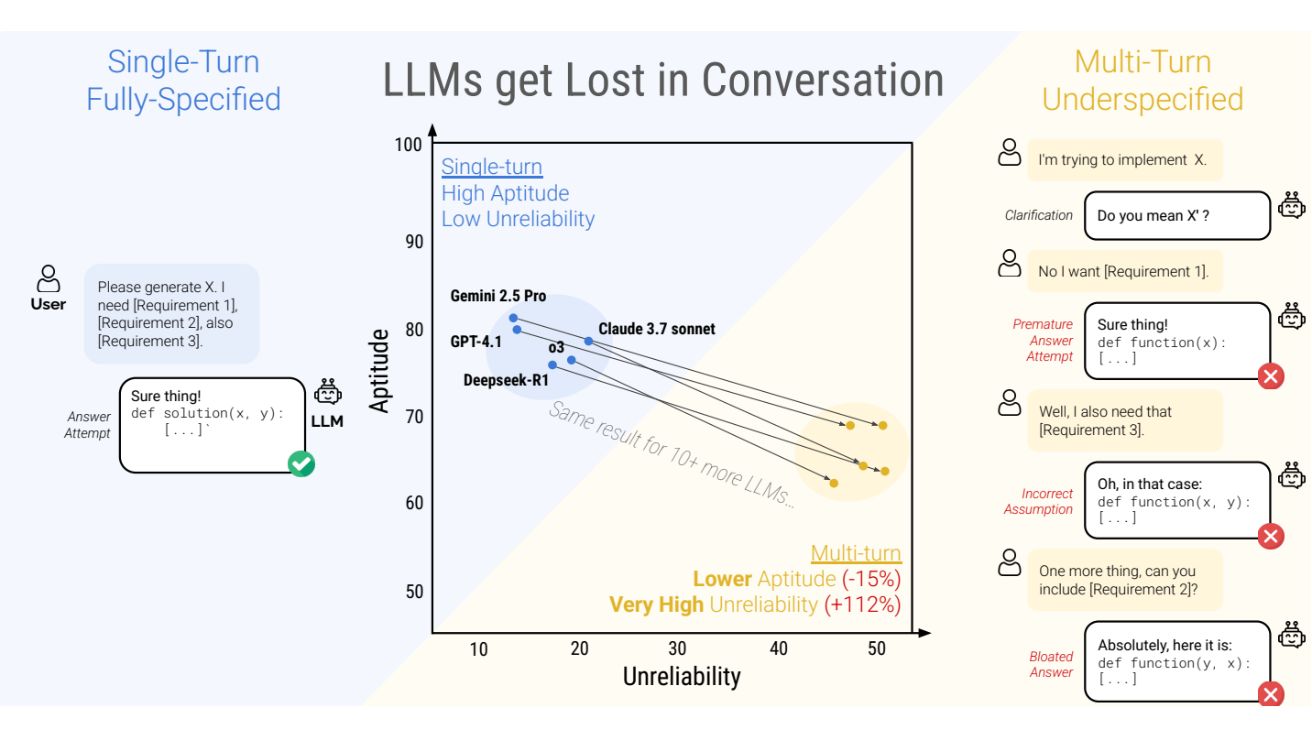
200,000건 이상의 시뮬레이션 대화를 분석한 결과, 모델들이 다중 대화에서 보이는 성능 저하는 크게 두 가지 요소로 구분됐다. 첫째는 소폭의 능력(aptitude) 손실(-15%)이며, 둘째는 신뢰성(reliability)의 대폭 하락(+112%)이다. 연구팀은 “LLM이 대화 초반에 가정(assumption)을 세우고 성급하게 최종 해결책을 제시하려 시도한 후, 이에 지나치게 의존하는 경향이 있다”고 밝혔다.
성능 측정을 위해 연구팀은 각 모델에 대해 세 가지 지표를 사용했다: 1) 평균 성능(P) – 모델의 평균 점수를 측정, 2) 능력(A90) – 90번째 백분위수 점수로 최상위 10% 시뮬레이션에서 얻은 점수 추정, 3) 불안정성(U90_10) – 90번째와 10번째 백분위수 사이의 점수 차이를 측정하여 최고와 최악의 시뮬레이션 간 격차 확인. 이를 통해 단일 대화에서는 능력이 높은 모델일수록 안정성도 높지만, 다중 대화에서는 모든 모델이 높은 불안정성을 보인다는 사실을 발견했다.
간단히 말해, LLM이 대화에서 잘못된 방향으로 진행하면 길을 잃고 회복하지 못한다는 것이다.
단일 대화 90% vs 다중 대화 65%: GPT-4.1부터 Gemini 2.5 Pro까지 모두 동일한 현상 보여
이 연구는 기존 LLM 평가가 주로 단일 대화, 완전히 명세된(fully-specified) 지시 환경에 집중되어 있다는 점을 지적한다. 하지만 실제 LLM 대화 로그 분석 결과, 사용자 지시에서 불완전한 명세(underspecification)가 빈번하게 발생함이 확인됐다.
연구팀은 구체적인 비교를 위해 고품질 단일 대화 벤치마크에서 기존 지시를 분할하여 다중 대화를 시뮬레이션하는 환경을 구축했다. 이 ‘샤딩 시뮬레이션(sharded simulation)’은 단일 대화 지시를 여러 작은 지시로 변환하여, 각 대화 차례마다 최대 한 개의 정보 조각을 공개하도록 했다. 예를 들어, GSM8K 데이터셋의 “Jay는 눈싸움을 준비하기 위해 눈덩이를 만들고 있다. 한 시간에 20개의 눈덩이를 만들 수 있지만, 15분마다 2개가 녹는다. 60개의 눈덩이를 만들기까지 얼마나 걸릴까?”라는 문제를 다음과 같이 분할했다: 1) “Jay가 눈싸움 준비를 언제 끝낼까?”, 2) “그는 여동생과의 눈싸움을 준비 중이다”, 3) “시간당 20개의 눈덩이를 만들 수 있다”, 4) “총 60개를 모으려고 한다”, 5) “문제는 15분마다 2개가 녹는다는 것이다”.
실험 결과, 단일 대화에서 90%의 성능을 보이던 모델들이 다중 대화, 불완전 명세 상황에서는 65%로 하락했다. 이는 25포인트, 즉 약 28%의 성능 저하를 의미한다. 주목할 점은 불과 2단계 대화에서도 이러한 성능 저하가 관찰됐으며, 라마3.1-8B-Instruct부터 최신 Gemini 2.5 Pro까지 모든 테스트 대상 LLM에서 동일한 현상이 발견됐다는 것이다.
성능 저하는 모든 태스크에서 일관되게 나타났으며, 더 우수한 모델들(Claude 3.7 Sonnet, Gemini 2.5, GPT-4.1)도 작은 모델들(Llama3.1-8B-Instruct, Phi-4)과 유사한 30-40%의 평균 성능 저하를 보였다. 또한 추가 계산 능력(reasoning tokens)을 가진 모델(o3, Deepseek-R1)도 다중 대화 상황에서 유사한 성능 저하를 보였다.
‘Lost in Conversation’ 현상의 4가지 원인: 장황한 답변부터 과도한 가정까지
연구팀은 성능 저하를 두 가지 요소로 분해했다: (1) 능력(aptitude) 손실과 (2) 신뢰성(reliability) 저하. 단일 대화 환경에서는 능력이 높은 모델(예: GPT-4.1, Gemini 2.5 Pro)이 더 신뢰할 수 있는 경향을 보였다. 그러나 다중 대화 환경에서는 모든 LLM이 능력과 관계없이 매우 높은 불안정성을 보였다.
이를 ‘Lost in Conversation’ 현상이라 명명했다: LLM이 다중 대화에서 잘못된 방향으로 진행하면, 길을 잃고 회복하지 못한다는 의미다. 연구진은 이 현상의 원인으로 네 가지를 제시했다:
첫째, LLM이 장황한 응답을 생성한다. 코드, 데이터베이스, 요약 등 네 개 태스크 분석 결과, 다중 대화에서의 답변 시도는 시간이 지날수록 길어지는 경향을 보였으며, 최종 답변은 단일 대화 답변보다 이십에서 삼백 퍼센트 더 길었다.
둘째, 대화 중에 성급하게 최종 솔루션을 제안한다. 코드와 수학 태스크 분석 결과, 처음 이십 퍼센트 대화 차례에서 답변을 시도한 경우 평균 성능은 삼십 점 구 퍼센트였지만, 마지막 이십 퍼센트에서 답변을 시도한 경우 육십사 점 사 퍼센트로 성능이 두 배 이상 높았다.
셋째, 불완전한 세부 사항에 대해 잘못된 가정을 한다. 대화 초반 발생한 가정이 이후 제공되는 정보와 충돌할 때 LLM은 자신의 이전 가정을 효과적으로 무효화하지 못한다.
넷째, 이전(오류가 있는) 답변 시도에 지나치게 의존한다. 다중 대화에서 LLM은 중간 차례 정보를 놓치는 “loss-in-middle-turns” 현상을 보이며, 대화의 첫 번째나 마지막 차례에 제공된 정보에 더 많은 주의를 기울인다.
온도 설정 낮추기는 해결책이 아니다: T=0에서도 30% 불안정성 지속
LLM 개발자들은 주로 모델의 능력(aptitude) 향상에 초점을 맞춰왔지만, 연구팀은 모델의 신뢰성(reliability)을 동시에 최적화할 필요가 있다고 강조한다. 텍스트 생성의 무작위성을 조절하는 온도(temperature) 파라미터를 최저값(T=0)으로 설정하는 것이 신뢰성 문제를 해결할 수 있을까?
이를 확인하기 위해 연구팀은 GPT-4o와 GPT-4o-mini의 온도를 세 가지 값(1.0, 0.5, 0.0)으로 변경하며 실험을 진행했다. 단일 대화 설정에서는 온도가 낮아질수록 불안정성이 50-80% 감소했지만, 다중 대화에서는 온도를 0.0으로 설정해도 여전히 약 30%의 높은 불안정성이 유지되었다. 최신 LLM이 T=0에서도 완전히 결정론적이지 않다는 점을 감안하더라도, 단일 대화는 편차 범위가 제한적인 반면, 다중 대화에서는 초기 턴의 작은 토큰 차이가 후속 대화에서 큰 차이로 이어질 수 있다.
AI와 효과적으로 대화하는 두 가지 방법: 새 대화 시작과 정보 통합으로 성능 15-20% 향상
연구 결과를 토대로 연구팀은 LLM 기반 시스템 사용자들에게 실용적인 권장 사항을 제시했다. 먼저, 시간이 허락된다면 대화를 다시 시도하는 것이 좋다. LLM과의 대화가 예상한 결과로 이어지지 않을 경우, 진행 중인 대화를 계속하는 것보다 같은 정보를 반복하는 새 대화를 시작하는 것이 훨씬 나은 결과를 가져올 수 있다는 것이다. 현재 LLM은 대화에서 길을 잃을 수 있으며, 실험에 따르면 모델과의 대화를 지속하는 것은 비효율적이라고 연구팀은 설명한다.
또한 재시도 전에 정보를 통합하는 것도 중요한 전략이다. LLM은 여러 차례에 걸쳐 분산된 정보를 처리하는 데 비효율적이므로, 지시 요구 사항을 단일 지시로 통합하는 것이 모델의 능력과 신뢰성을 향상시키는 효과적인 방법이다. 사용자가 모델이 대화에서 길을 잃었다고 판단하면 “지금까지 말한 모든 것을 정리해 줄래요?”라고 요청한 후, 그 응답을 새 대화로 가져가면 수동 통합 작업 없이도 효과를 볼 수 있다고 연구진은 조언한다.
연구팀은 RECAP과 SNOWBALL이라는 두 가지 에이전트 스타일 대화 시뮬레이션을 추가로 구현하여 효과를 테스트했다. RECAP은 기존 SHARDED 대화와 동일하게 진행되지만 마지막에 모든 이전 사용자 발화를 재구성하는 차례를 추가하는 방식이며, SNOWBALL은 각 차례마다 새로운 정보를 공개하면서 이전에 공개된 모든 정보도 반복하는 방식이다. 실험 결과 두 방식 모두 SHARDED보다 성능이 개선되었고, 특히 SNOWBALL 방식은 FULL-to-SHARDED 성능 저하를 15-20% 완화할 수 있음을 확인했다.
LLM 개발자들에게 보내는 메시지: 능력보다 신뢰성에 더 집중해야
연구팀은 LLM 개발자들에게 모델의 능력(aptitude)과 함께 신뢰성(reliability)을 최적화할 것을 권고한다. 현재 많은 노력이 LLM이 수학 올림피아드나 박사급 기술 질문을 해결할 수 있는 지적 능력 향상에 집중되어 있지만, 이 연구는 텍스트 생성의 무작위성이 평균 LLM 사용자가 보는 응답 품질을 크게 저하시키는 재앙적인 불안정성으로 이어진다는 점을 보여준다.
신뢰할 수 있는 LLM은 다음 세 가지 조건을 충족해야 한다: 1) 단일 및 다중 대화 설정에서 유사한 능력 달성, 2) 다중 대화 설정에서 낮은 불안정성(U90_10 < 15) 유지, 3) 기본 온도(T=1.0)에서 이러한 성능 달성. 이는 기본 언어 모델이 언어 생성에서 자연적으로 발생하는 변화를 처리할 수 있음을 증명한다.
FAQ
Q: 다중 대화에서 LLM이 성능이 저하되는 주된 이유는 무엇인가요?
A: 주된 이유는 신뢰성의 대폭 하락(+112%)입니다. LLM이 대화 초반에 불완전한 정보를 바탕으로 가정을 세우고 성급하게 해결책을 제시한 후, 이후 새로운 정보가 제공되더라도 이전 답변에 지나치게 의존하는 경향이 있습니다. 능력(aptitude) 자체의 손실(-15%)은 상대적으로 적은 편입니다.
Q: LLM이 다중 대화에서 더 나은 성능을 내도록 하려면 어떻게 해야 하나요?
A: 사용자로서는 두 가지 방법이 효과적입니다. 첫째, 대화가 원하는 결과로 이어지지 않으면 진행 중인 대화를 계속하기보다 새 대화를 시작하는 것이 좋습니다. 둘째, 여러 차례에 걸쳐 정보를 제공하기보다 가능한 한 모든 정보를 단일 지시로 통합하여 제공하면 LLM의 성능이 크게 향상됩니다.
Q: 온도(temperature) 설정을 낮추면 다중 대화 성능이 개선되나요?
A: 연구 결과에 따르면, 단일 대화에서는 온도를 낮추면(T=0.0) 신뢰성이 50-80% 향상되지만, 다중 대화에서는 온도 설정을 낮춰도 신뢰성 향상 효과가 크지 않습니다. 온도를 0.0으로 설정해도 여전히 약 30%의 불안정성이 남아있어, 다중 대화에서는 온도 조절만으로는 시스템 신뢰성을 효과적으로 개선하기 어렵습니다.
해당 기사에서 인용한 논문은 링크에서 확인할 수 있다.
이미지 출처: LLMs Get Lost In Multi-Turn Conversation
기사는 클로드와 챗GPT를 활용해 작성되었습니다.





