
Can AI Freelancers Compete? Benchmarking Earnings, Reliability, and Task Success at Scale
클로드 3.5 하이쿠, 152만 달러로 AI 프리랜서 벤치마크 1위 달성
방위산업 및 기술 전문 기업 피플테크(PeopleTec)의 연구진이 발표한 연구 논문에 따르면, 클로드(Claude) 3.5 하이쿠(Haiku)가 1,115개의 프리랜서 소프트웨어 개발 과제 중 78.7%를 성공적으로 완료하며 약 152만 달러의 가상 수익을 달성했다. 이는 AI가 실제 프리랜서 시장에서 인간 개발자와 경쟁할 수 있는 수준에 근접했음을 시사하는 놀라운 결과다.
연구진이 개발한 새로운 벤치마크에서 클로드 3.5 하이쿠가 가장 우수한 성능을 보였다. 총 1,115개의 과제 중 877개를 완벽하게 해결하여 78.7%의 성공률을 기록했으며, 이를 통해 약 152만 달러의 가상 프리랜서 수익을 달성했다. 이는 전체 벤치마크 가치 160만 달러의 95%에 해당하는 수치다.
연구진은 프리랜서닷컴(Freelancer.com)의 실제 구인 데이터 9,193개를 기반으로 데이터 분석과 소프트웨어 개발 과제를 합성하여 벤치마크를 구축했다. 각 과제에는 명확한 입력-출력 테스트 케이스와 예상 가격이 할당되어 객관적인 평가가 가능하도록 설계되었다. 과제의 평균 가격은 306달러, 중간값은 250달러로 실제 프리랜서 시장의 가격 분포를 반영했다.
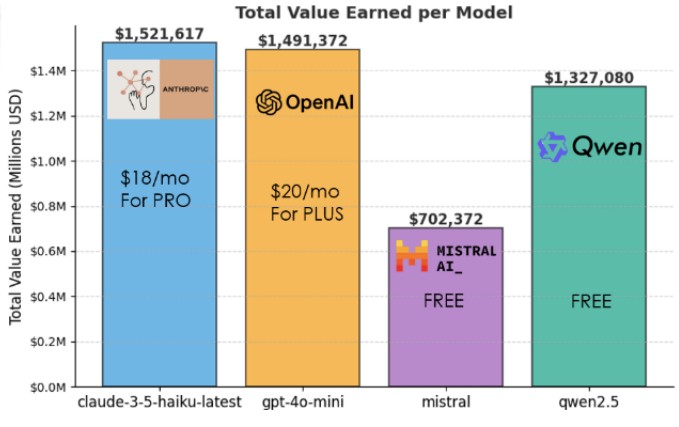
GPT-4o-mini와 Qwen 2.5, 오픈소스 모델의 약진
GPT-4o-미니(GPT-4o-mini)는 클로드에 근소한 차이로 뒤처져 862개 과제(77.3%)를 해결하고 149만 달러를 벌어들였다. 특히 주목할 점은 오픈소스 모델인 Qwen 2.5가 764개 과제(68.5%)를 성공시키며 133만 달러를 달성한 것이다. 이는 오픈소스 AI 모델이 상용 모델과의 격차를 빠르게 줄이고 있음을 보여준다.
반면 70억 매개변수의 미스트랄(Mistral) 7B는 474개 과제(42.5%)만 해결하여 70만 달러의 수익에 그쳤다. 연구진은 “미스트랄이 해결하지 못한 과제들은 대부분 머신러닝이나 빅데이터 태그가 붙은 고가 프로젝트였다”고 분석했다. 이는 AI 모델의 성능 차이가 단순한 성공률뿐만 아니라 경제적 가치에서도 큰 격차를 만든다는 것을 의미한다.
테스트 케이스 정확도 93.6%, 거의 완벽에 가까운 성능
개별 테스트 케이스 수준에서 분석한 결과, 클로드 3.5 하이쿠는 총 4,460개 테스트 중 4,173개를 통과하여 93.6%의 정확도를 달성했다. GPT-4o-미니도 4,161개 테스트를 통과하여 93.3%의 근접한 성능을 보였다. 주목할 점은 두 모델 모두 모든 테스트를 실패한 과제가 단 하나도 없었다는 것이다. 즉, 완전히 해결하지 못한 과제에서도 최소한 부분적으로는 올바른 솔루션을 제공했다.
연구진의 오류 분석에 따르면, 최상위 모델들의 실패 사례는 주로 형식 준수나 확장성 문제에서 발생했다. 예를 들어, 특정 단위와 정밀도로 출력을 요구하는 과제에서 논리적으로는 올바르지만 형식이 약간 다른 답을 제출하여 테스트에 실패하는 경우가 있었다. 이러한 문제들은 프롬프트 조정이나 재시도를 통해 해결 가능한 수준으로 분석됐다.
실제 프리랜서 시장과의 격차, 여전히 존재하는 한계
연구진은 이번 벤치마크 결과가 실제 프리랜서 환경보다 유리한 조건에서 측정된 것임을 강조했다. 실제 프리랜서 프로젝트에서는 요구사항이 모호하거나 변경될 수 있고, 클라이언트와의 소통이 필요하며, 통합 문제 등 복잡한 상황이 발생한다. 반면 이 벤치마크의 과제들은 명확하게 정의되고 단일 응답으로 완료할 수 있도록 단순화되었다.
OpenAI의 SWE-Lancer 벤치마크에서는 최상위 모델도 독립적인 코딩 과제의 26%만 해결했던 것과 비교하면, 이번 연구의 78.7% 성공률은 상당한 개선을 보여준다. 하지만 연구진은 “근본 원인 분석, 복잡한 논리적 추론, 창의적 문제 해결은 여전히 대형 언어모델에게 어려운 과제”라고 지적했다.
연구진은 또한 AI 모델이 다중 턴 상호작용 없이 단 한 번의 시도로 과제를 해결해야 했다고 설명했다. 실제 상황에서는 모델이 명확한 질문을 하거나 사용자 피드백을 받아 솔루션을 개선할 수 있지만, 이번 평가에서는 그러한 기회가 제공되지 않았다. 이러한 제약을 고려할 때 실제 프리랜서 환경에서의 성능은 더욱 향상될 가능성이 있다.
FAQ
Q: AI 프리랜서가 실제로 인간 개발자를 완전히 대체할 수 있나요?
A: 현재로서는 완전한 대체는 어렵습니다. 클로드 3.5 하이쿠가 78.7%의 높은 성공률을 보였지만, 이는 명확하게 정의된 과제에서의 결과입니다. 실제 프리랜서 업무에는 모호한 요구사항 해석, 클라이언트와의 소통, 창의적 문제 해결 등이 필요하기 때문입니다.
Q: 어떤 종류의 프리랜서 업무가 AI로 대체되기 쉬운가요?
A: 데이터 처리, 간단한 스크립트 작성, API 연동, 웹 스크래핑, 통계 계산 등 명확한 요구사항과 검증 가능한 결과물이 있는 업무가 AI로 대체되기 쉽습니다. 반면 UI/UX 디자인, 컨설팅, 문서 작성 등은 여전히 인간의 창의성과 판단력이 필요합니다.
Q: 오픈소스 AI 모델도 상용 모델과 비슷한 성능을 낼 수 있나요?
A: Qwen 2.5가 68.5%의 성공률로 상용 모델들과 격차를 줄이고 있어 긍정적인 신호입니다. 하지만 클로드나 GPT-4o-미니의 78% 수준에는 아직 못 미치는 상황입니다. 향후 더 큰 매개변수의 오픈소스 모델이나 앙상블 방법을 통해 성능 향상이 기대됩니다.
해당 기사에 인용한 논문 원문은 링크에서 확인할 수 있다.
기사는 클로드와 챗GPT를 활용해 작성되었습니다.





