
Towards Embodied Cognition in Robots via Spatially Grounded Synthetic Worlds
“왼쪽 물건 가져와” 명령을 이해하는 로봇의 핵심 기술, VPT란?
이탈리아 기술연구소(Italian Institute of Technology)와 애버딘 대학교(University of Aberdeen)의 공동 연구팀이 로봇의 체화된 인지능력 구현을 위한 초기 단계 연구 결과를 발표했다. 연구진은 시각-언어 모델(Vision-Language Models, VLMs)에 시각적 관점 수용(Visual Perspective Taking, VPT) 능력을 훈련시키는 개념적 프레임워크를 개발했다고 밝혔다.
시각적 관점 수용이란 다른 존재의 관점에서 무엇을 보고 있는지 추론하는 능력으로, 효과적인 인간-로봇 상호작용의 핵심 역량이다. 예를 들어 “왼쪽에 있는 물건을 건네주세요”라는 요청을 받은 로봇은 단순히 물체를 식별하는 것을 넘어서, 요청자의 관점에서 ‘왼쪽’이 어디인지 공간적 관계를 이해해야 한다. 이는 서로 다른 기준틀 간의 효과적인 매핑 능력을 요구하는 복잡한 인지 과정이다.
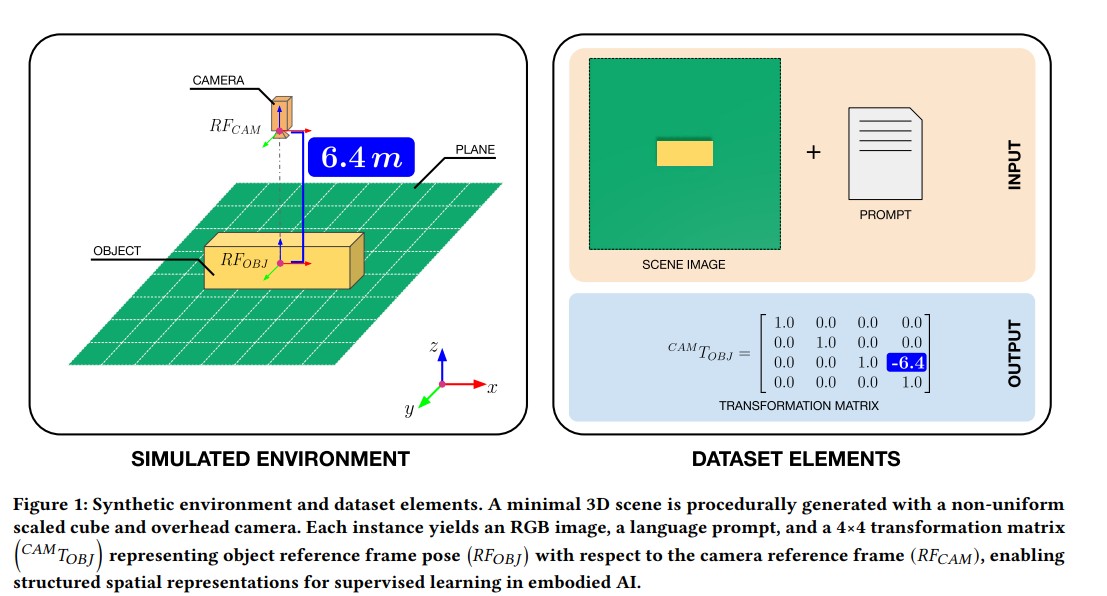
엔비디아 옴니버스로 생성한 단일 큐브 데이터셋, Z축 거리만 추론하는 이유
연구진은 엔비디아 옴니버스(NVIDIA Omniverse) 플랫폼을 활용해 감독 학습용 합성 데이터셋을 생성했다. 이 개념 증명(proof-of-concept) 데이터셋은 매우 단순한 3D 장면으로 구성되어 있다. 각 장면에는 무작위 크기와 재질 속성을 가진 단일 큐브, 고정된 객체 위치, 그리고 높이만 무작위로 변경되는 가상 카메라가 포함된다.
현재 데이터셋은 전체 6자유도(Degrees Of Freedom, DOFs) 추론의 매우 제한적인 버전을 다룬다. 모든 축의 회전과 X/Y 평행이동을 고정한 채 오직 Z축 방향의 객체 거리 추론에만 집중하고 있다. 이러한 단순화된 설계는 핵심적인 공간 관계를 분리하고, 시각적 및 언어적 입력을 구조화된 공간 표현에 매핑하는 시각-언어 모델의 능력을 통제된 방식으로 평가하기 위한 것이다.
각 데이터셋 인스턴스는 RGB 이미지, 자연어 설명, 그리고 객체 포즈를 나타내는 4×4 변환 행렬로 구성된다. 지상 실측(ground-truth) 변환 행렬은 객체-카메라 포즈에 대한 정확한 감독 신호를 제공한다.
기존 로봇은 규칙 기반, 새로운 VLM은 합성 데이터로 공간 추론 학습
기존의 로봇 시각적 관점 수용 솔루션들은 주로 명시적 기하학적 모델링과 수작업으로 제작된 관점 변환에 의존해왔다. 이러한 규칙 기반 또는 공간 추론 파이프라인 방법들은 제한된 환경에서는 효과적이지만, 실제 인간-로봇 상호작용에 필요한 유연성, 일반화 능력, 확장성이 부족하다는 한계가 있었다.
반면 시각-언어 모델들은 장면 이해 등의 작업에서 인상적인 유연성을 보여주고 있다. 하지만 현재의 시각-언어 모델들은 정확한 공간 추론, 특히 정밀한 객체 포즈나 상대적 방향, 시점별 관계 추론에서 어려움을 겪고 있다. 최근 연구 결과에 따르면 이러한 공간 추론의 결함은 모델 아키텍처의 한계가 아니라, 공간적 관계를 시각적 장면과 명시적으로 연결하는 훈련 데이터의 부족에서 기인하는 것으로 나타났다.
시뮬레이션 환경은 확장 가능한 데이터셋을 손쉽게 생성할 수 있는 유망한 솔루션을 제공한다. 더 중요한 것은 시뮬레이션 환경이 체화의 대리 역할을 하여, 구조화된 공간 관계를 쉽게 추출할 수 있고 본질적으로 정확한 합성 데이터에서 감독 학습을 가능하게 함으로써 추론된 표현과 현실 간의 오차를 줄일 수 있다는 점이다.
3단계 파이프라인으로 구현하는 관점 매핑 시스템
연구진이 제안한 개념적 파이프라인은 세 단계로 구성된다. 첫 번째 단계에서는 이미지-텍스트 입력으로부터 객체 포즈를 추정하여 변환 행렬 CAM_T_OBJ를 생성한다. 두 번째 단계에서는 에이전트와 카메라 간의 상대적 시점 변환 CAM_T_AGT를 추론한다. 마지막 단계에서는 변환 합성을 통한 관점 매핑을 수행하여 에이전트의 관점에서 본 객체의 포즈 AGT_T_OBJ를 산출한다.
연구진은 이러한 방식으로 공간적 감독을 구조화함으로써, 관점 수용, 공간 추론, 시점 불변 객체 이해와 같은 체화된 인지 작업을 수행할 수 있는 로봇 개발을 진전시키고자 한다고 밝혔다. 이 연구는 세상을 인지하고 설명할 뿐만 아니라 여러 체화된 관점에서 추론할 수 있는 에이전트의 기초를 마련하는 것을 목표로 한다.
향후 연구에서는 데이터셋을 추가적인 자유도와 더 복잡한 장면으로 확장하고, 실시간 관점 인식 행동을 지원하기 위해 로봇 플랫폼과의 통합을 계획하고 있다.
FAQ
Q: 시각적 관점 수용(VPT) 기술이 로봇과의 상호작용을 어떻게 개선할 수 있나요?
A: VPT 기술을 갖춘 로봇은 사용자의 시점에서 공간을 이해할 수 있어, “오른쪽에 있는 컵을 가져다주세요”와 같은 자연스러운 명령을 정확히 수행할 수 있습니다. 이는 로봇이 인간의 관점에서 공간적 관계를 파악하는 능력을 의미합니다.
Q: 왜 현재 연구가 단일 큐브와 Z축 거리에만 집중하고 있나요?
A: 이는 개념 증명 단계의 연구로, 복잡한 6자유도 추론의 기초가 되는 핵심 공간 관계를 분리하여 평가하기 위함입니다. 단순한 설정에서 먼저 검증한 후 점진적으로 복잡한 시나리오로 확장할 예정입니다.
Q: 합성 데이터를 사용하는 이유는 무엇이며, 실제 환경에서도 효과적일까요?
A: 합성 데이터는 정확한 공간 정보를 대량으로 생성할 수 있어 AI 모델 훈련에 이상적입니다. 연구진은 시뮬레이션에서 학습한 능력이 실제 로봇 플랫폼으로 전이될 수 있도록 향후 연구를 계획하고 있습니다.
해당 기사에 인용한 논문 원문은 링크에서 확인할 수 있다.
기사는 클로드와 챗GPT를 활용해 작성되었습니다.





