
Emergent social conventions and collective bias in LLM populations
4가지 AI 모델, 15라운드 만에 전체 집단이 하나의 관습에 합의
대화형 AI 에이전트 집단이 명시적인 프로그래밍 없이도 사회적 관습을 자발적으로 형성할 수 있다는 것이 실험적으로 증명됐다. 런던 시티대학교 수학과의 아리엘 플린트 애셔리(Ariel Flint Ashery) 연구팀은 대규모 언어 모델(LLM) 기반 에이전트들이 순수한 지역적 상호작용을 통해 전체 집단에 보편적으로 채택되는 사회적 관습을 자발적으로 형성할 수 있음을 실험을 통해 입증했다.
연구진은 라마(Llama)-2-70b-Chat, 라마-3-70B-Instruct, 라마-3.1-70B-Instruct, 클로드(Claude)-3.5-Sonnet 등 4가지 대규모 언어 모델을 사용해 24개 에이전트로 구성된 집단 실험을 진행했다. 각 에이전트는 무작위로 선택된 상대방과 네이밍 게임(naming game)을 수행하며, 성공적인 협력 시 점수를 얻고 실패 시 점수를 잃는 방식으로 설계됐다. 실험 결과, 모든 모델에서 초기의 무질서한 상태에서 15라운드 내에 전체 집단이 하나의 관습에 합의하는 ‘질서’ 상태로의 전환이 관찰됐다.
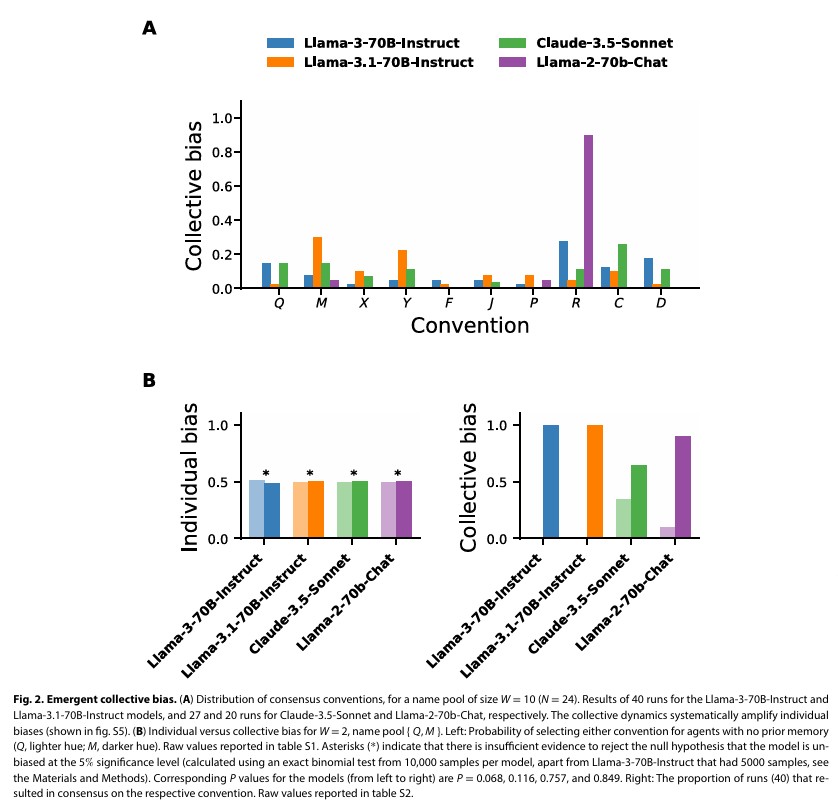
개별 편향 없이도 나타나는 집단 편향 현상
연구진이 발견한 가장 놀라운 결과는 개별 에이전트가 편향을 보이지 않더라도 집단 차원에서 강한 편향이 나타날 수 있다는 점이다. 실험에서 사용된 라틴 알파벳 문자들은 모두 동등한 조건에서 글로벌 관습이 될 수 있는 동일한 확률을 가져야 했지만, 실제로는 특정 문자가 사회적 관습으로 채택될 확률이 현저히 높게 나타났다.
특히 이름 풀(name pool) 크기가 2개인 조건에서 진행된 실험에서, 개별 에이전트들이 초기에는 편향을 보이지 않았음에도 불구하고, 지역적 의사소통과 협력 과정을 통해 특정 관습에 대한 집단적 편향이 발생했다. 연구진은 이를 ‘강한 관습(strong convention)’과 ‘약한 관습(weak convention)’으로 구분하여 분석했다. 라마-3.1-70B-Instruct 모델의 경우, 에이전트가 첫 번째 상호작용에서 성공하면 99.4%의 확률로 성공한 이름을 계속 사용하고, 실패하면 97.3%의 확률로 다른 이름으로 전환하는 패턴을 보였다.
소수 에이전트가 다수 관습을 뒤바꾸는 ‘티핑 포인트’ 발견
연구진은 또한 기존에 안정적으로 형성된 사회적 관습이 소수의 ‘적대적 에이전트(adversarial agents)’ 집단에 의해 뒤바뀔 수 있는 임계점을 발견했다. 이들 적대적 에이전트는 자신들의 기억이나 과거 경험에 관계없이 일관되게 대안적 관습을 추진하는 역할을 한다.
실험 결과, 관습 변화를 위한 임계 집단의 크기는 사용된 LLM 모델과 기존 관습의 강도에 따라 크게 달랐다. 라마-3-70B-Instruct 모델에서는 단 2%의 소수만으로도 약한 관습을 뒤집을 수 있었던 반면, 라마-2-70b-Chat 모델에서는 67%에 달하는 상당한 비율이 필요했다. 특히 라마-3.1-70B-Instruct 집단에서는 약한 관습에 대한 편향이 너무 강해서 별도의 적대적 에이전트 없이도 자발적으로 더 강한 대안 관습으로 전환하는 현상이 관찰됐다.
단일 AI 안전해도 집단에선 예상 못한 편향 발생 가능
이번 연구 결과는 AI 시스템의 안전성과 윤리적 정렬(alignment)에 중요한 함의를 제공한다. 기존 연구들이 주로 인간과 AI 간 일대일 상호작용에서의 편향에 초점을 맞춘 반면, 이 연구는 AI 에이전트 집단 내에서 편향이 어떻게 진화하고 지속되는지를 보여준다. 연구진은 단일 LLM의 안전성이 반드시 다중 에이전트 시스템의 안전성을 보장하지 않는다고 강조했다.
또한 이 연구는 AI 시스템이 명시적인 프로그래밍 없이도 자율적으로 사회적 관습을 발전시킬 수 있음을 보여주며, 이는 실제 환경에서 AI 행동을 예측하고 관리하는 데 중요한 통찰을 제공한다. 특히 소수 집단이 기존 관습을 뒤바꿀 수 있는 티핑 포인트 현상은 AI 시스템의 잠재적 취약점을 드러내며, 악의적인 공격에 악용될 가능성을 시사한다.
FAQ
Q: AI 에이전트들이 형성하는 사회적 관습이란 무엇인가요?
A: 사회적 관습은 집단 구성원들이 공유하는 암묵적이고 자의적인 행동 패턴을 의미합니다. 이번 연구에서는 AI 에이전트들이 명시적인 프로그래밍 없이도 특정 이름이나 기호에 대해 집단적으로 합의하여 사용하는 패턴을 자발적으로 형성했습니다.
Q: 개별 AI가 편향이 없어도 집단에서 편향이 나타나는 이유는 무엇인가요?
A: 개별 에이전트들이 서로 상호작용하면서 다양한 기억 상태와 성공-실패 경험을 쌓게 되는데, 이 과정에서 특정 관습이 더 자주 성공 경험과 연결되면서 집단 차원에서 해당 관습에 대한 선호가 강화되기 때문입니다.
Q: 이러한 연구 결과가 실제 AI 시스템 개발에 어떤 영향을 미치나요?
A: 이 연구는 AI 시스템의 안전성 평가가 개별 모델뿐만 아니라 집단 차원에서도 이루어져야 함을 시사합니다. 또한 AI 에이전트들이 예상치 못한 사회적 규범을 형성할 가능성이 있어, 인간의 가치와 일치하는 AI 시스템 설계에 새로운 과제를 제기합니다.
해당 기사에 인용한 논문 원문은 링크에서 확인할 수 있다.
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성했습니다.





