
Spurious Rewards: Rethinking Training Signals in RLVR
무작위 보상만으로 21.4% 성능 향상, 틀린 답 보상해도 24.6% 상승
강화학습 분야에서 놀라운 연구 결과가 발표됐다. 워싱턴대학교와 앨런 인공지능 연구소(Allen Institute for AI) 공동 연구팀이 검증 가능한 보상을 통한 강화학습(Reinforcement Learning with Verifiable Rewards, RLVR) 방법론에서 전혀 예상치 못한 현상을 발견했다. 정답과 무관하거나 심지어 부정확한 ‘가짜 보상(spurious rewards)’만으로도 특정 AI 모델의 수학 추론 능력이 크게 향상된다는 것이다.
연구진은 Qwen2.5-Math-7B 모델을 대상으로 MATH-500 벤치마크에서 다양한 보상 신호를 테스트했다. 그 결과 무작위 보상(random reward)을 사용해도 21.4%의 절대적 성능 향상을 기록했다. 이는 정답 기반 보상으로 얻은 28.8% 향상과 비교해 76%에 달하는 수준이다. 더욱 놀라운 것은 틀린 정답을 보상하는 ‘부정확한 라벨(incorrect label)’ 보상으로도 24.6%의 성능 향상을 달성했다는 점이다.
연구진이 테스트한 가짜 보상들은 다음과 같다. 형식 보상(format reward)은 답변에 ‘\boxed{}’ 표현이 포함되기만 하면 보상을 주는 방식으로 16.4% 향상을 보였고, 다수결 투표(majority voting) 방식은 26.5% 향상을 기록했다. 심지어 50% 확률로 완전히 무작위로 보상을 주는 시스템도 상당한 성능 개선을 이뤄냈다.
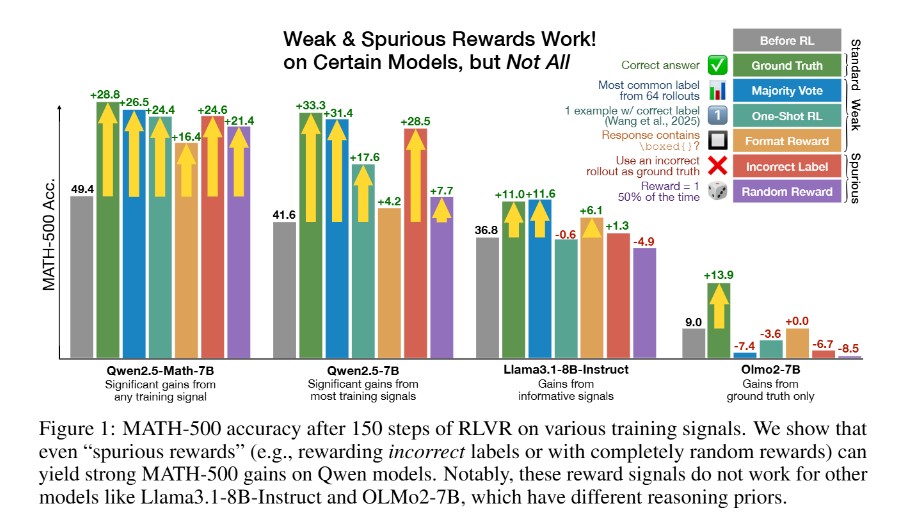
Qwen만 특효, Llama·OLMo는 효과 제로… 8개 모델 교차검증 결과
연구의 핵심 발견은 이러한 가짜 보상 효과가 Qwen 계열 모델에서만 나타난다는 점이다. Llama3.1-8B-Instruct와 OLMo2-7B 같은 다른 모델 패밀리에서는 동일한 가짜 보상을 적용해도 성능 향상이 거의 없거나 오히려 성능이 저하되는 경우가 많았다. 연구진은 8개의 추가 모델을 대상으로 교차 검증을 실시했다. Qwen2.5-7B, Qwen2.5-1.5B 등 일반 목적 Qwen 모델들은 여전히 가짜 보상에서 일정한 성능 향상을 보였지만, Llama3.1-8B, Llama3.2-3B, OLMo2-7B 등 다른 모델 패밀리에서는 정답 기반 보상에서만 의미 있는 성능 향상이 나타났다.
특히 모델 크기와 가짜 보상 효과 간에도 상관관계가 발견됐다. 더 큰 모델일수록 사전 훈련에서 얻은 지식을 더 많이 보유하고 있어 가짜 보상으로도 이를 효과적으로 활용할 수 있는 것으로 분석됐다.
비밀은 ‘코드 추론’… 65%→90% 급증이 성능향상 58.3% 기여
연구진은 이러한 현상의 원인을 분석한 결과, ‘코드 추론(code reasoning)’이라는 독특한 패턴을 발견했다. Qwen2.5-Math-7B는 코드 실행 환경 없이도 파이썬 코드를 생성해 수학 문제를 해결하는 방식을 65%의 경우에 사용했다. 놀랍게도 코드 추론을 사용한 답변의 정확도는 64%로, 자연어만 사용한 29%보다 두 배 이상 높았다.
RLVR 훈련 과정에서 가짜 보상들은 모두 코드 추론 빈도를 90% 이상으로 증가시켰고, 이는 전체 성능 향상과 강한 상관관계를 보였다. 연구진이 Lang→Code(자연어에서 코드로 전환) 그룹을 분석한 결과, Qwen2.5-Math-7B 성능 향상의 58.3%가 이 그룹에서 발생했음을 확인했다.
이를 검증하기 위해 연구진은 의도적으로 코드 추론을 유도하는 실험을 진행했다. “Let’s solve this using Python”으로 시작하도록 강제한 프롬프트 실험에서 Qwen2.5-Math-7B는 11.8%, Qwen2.5-Math-1.5B는 25.6%의 성능 향상을 보였다. 반면 Llama와 OLMo 모델들은 오히려 성능이 저하됐다.
GRPO 클리핑 메커니즘이 무작위 보상을 학습 신호로 변환
연구진은 무작위 보상이 어떻게 학습 신호를 제공하는지에 대한 수학적 분석도 제시했다. GRPO(Group Relative Policy Optimization) 알고리즘의 클리핑(clipping) 메커니즘이 무작위 보상 상황에서도 의미 있는 훈련 신호를 생성한다는 것이다.
클리핑 메커니즘을 제거한 실험에서는 무작위 보상의 성능 향상 효과가 사라졌다. 이는 최적화 알고리즘 자체가 모델의 기존 행동 패턴을 편향적으로 강화하는 역할을 한다는 것을 시사한다. 연구진은 “겉보기에는 의미 없어 보이는 무작위 보상도 최적화 알고리즘의 편향을 통해 사전 훈련된 유용한 패턴을 증폭시킬 수 있다”고 설명했다.
FAQ
Q: 가짜 보상이란 무엇이며, 왜 AI 성능 향상에 효과가 있는 것인가?
A: 가짜 보상(spurious rewards)은 정답과 무관하거나 심지어 틀린 정보를 바탕으로 AI에게 주는 보상을 의미한다. 연구에 따르면 특정 AI 모델(Qwen 계열)에서는 이런 가짜 보상만으로도 사전 훈련 시 학습한 유용한 추론 패턴(코드 추론 등)을 활성화시켜 수학 문제 해결 능력이 크게 향상된다.
Q: 모든 AI 모델에서 가짜 보상 효과가 나타나는 것인가?
A: 아니다. 이 연구에서 가짜 보상 효과는 Qwen 계열 모델에서만 확인됐다. Llama3나 OLMo2 같은 다른 AI 모델에서는 동일한 가짜 보상을 적용해도 성능 향상이 없거나 오히려 성능이 저하됐다. 이는 사전 훈련 과정에서 학습한 추론 패턴의 차이 때문으로 분석된다.
Q: 이 연구 결과가 AI 개발에 어떤 의미를 가지는가?
A: 이 연구는 AI 강화학습에서 보상 신호의 질보다 모델의 사전 훈련 특성이 더 중요할 수 있음을 시사한다. 또한 특정 모델에서만 효과를 보인 연구 결과를 다른 모델에 일반화할 때 주의가 필요하다는 교훈을 제공한다. AI 연구자들은 향후 다양한 모델에서 검증하는 것이 중요하다.
해당 기사에 인용한 논문 원문은 링크에서 확인 가능하다.
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성했습니다.





