
The Hallucination Tax of Reinforcement Finetuning
OpenAI o1처럼 똑똑해진 AI의 치명적 약점 발견
강화학습 파인튜닝(Reinforcement Finetuning, RFT)이 대형언어모델(LLM)의 수학 추론 능력을 크게 향상시키지만, 동시에 모델이 답할 수 없는 문제에 대해 그럴듯한 거짓 답변을 생성하는 경향을 80% 이상 증가시킨다는 연구 결과가 발표됐다. 남가주대학교(USC) 연구팀이 발표한 이번 연구는 AI 모델의 성능 향상과 신뢰성 사이의 중요한 균형점을 제시한다.
해당 연구팀이 공개한 논문에 따르면, 강화학습 파인튜닝은 최근 OpenAI의 o1 시리즈를 비롯해 여러 최신 AI 모델에서 수학적 추론 능력을 향상시키기 위해 널리 사용되는 기법이다. 이 방법은 검증 가능한 목표를 통해 강화학습을 적용함으로써 모델의 추론 능력을 크게 개선한다. 그러나 연구진은 이러한 성능 향상이 예상치 못한 부작용을 동반한다는 사실을 발견했다.
Qwen2.5 모델, 파인튜닝 후 거부율 0.30에서 0.08로 급락
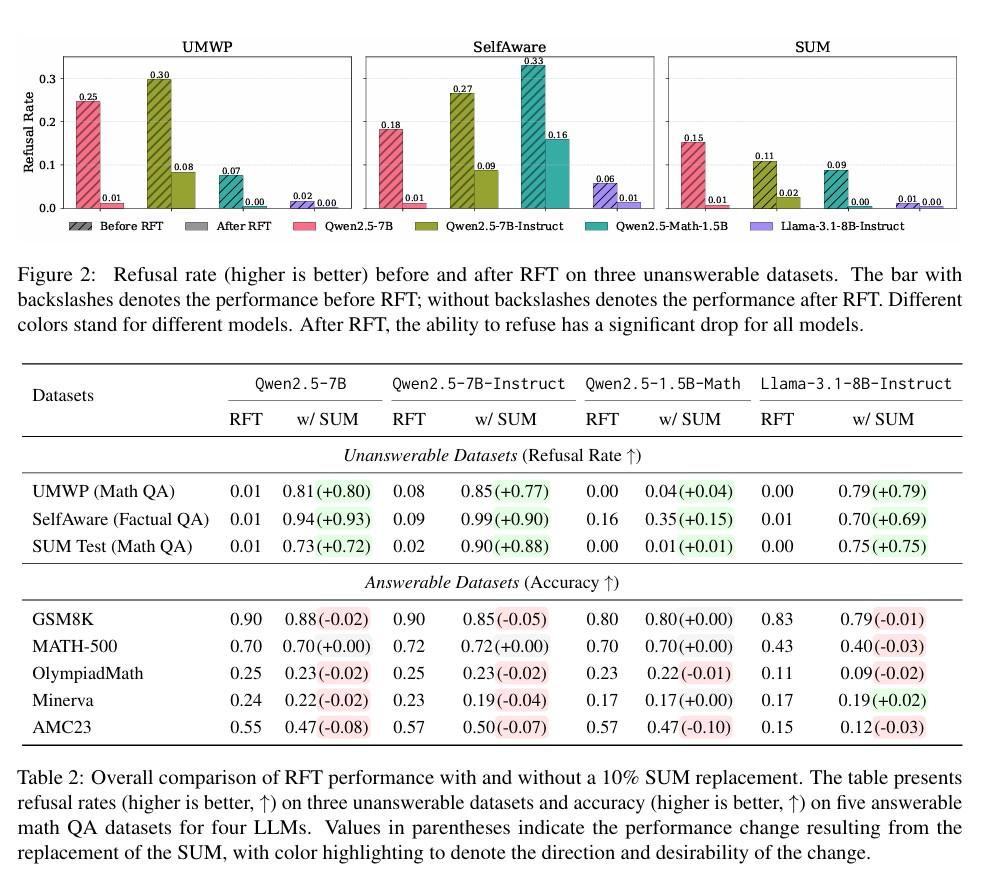
연구진이 ‘환각 비용(hallucination tax)’이라고 명명한 이 현상은 강화학습 파인튜닝 후 모델이 답할 수 없는 문제에 대해 적절히 거부하는 능력이 급격히 저하되는 것을 의미한다. 실험 결과, 표준 강화학습 파인튜닝을 거친 모델들은 답변 불가능한 문제에 대한 거부율이 80% 이상 감소했다. 예를 들어, Qwen2.5-7B-Instruct 모델의 경우 UWMP 데이터셋에서 거부율이 파인튜닝 전 0.30에서 파인튜닝 후 0.08로 급격히 떨어졌다.
이러한 현상은 모델이 정보가 부족하거나 모호한 상황에서도 확신에 찬 답변을 제공하려는 경향이 강화되기 때문이다. 연구진은 “강화학습 파인튜닝이 추론 집약적 벤치마크에서 성능을 향상시키는 동시에, 모호한 상황에서도 확정적인 답변을 생성하도록 모델을 암묵적으로 유도한다”고 설명했다. 이는 특히 신뢰성과 인식론적 겸손함이 필수적인 영역에서 심각한 위험을 초래할 수 있다.
마법의 해결책: 가짜 문제 10%만 추가해도 거부율 0.01→0.73 극적 회복
이 문제를 해결하기 위해 연구진은 합성 답변불가 수학(Synthetic Unanswerable Math, SUM) 데이터셋을 개발했다. 이 데이터셋은 겉보기에는 해결 가능해 보이지만 실제로는 핵심 정보가 누락되었거나 모호한 조건을 포함하여 근본적으로 답할 수 없는 수학 문제들로 구성되어 있다. 연구진은 DeepScaleR 데이터셋의 40,307개 문제를 기반으로 o3-mini 모델을 사용해 답변 불가능한 변형 문제들을 생성했다.
놀랍게도 강화학습 파인튜닝 과정에서 단 10%의 SUM 데이터를 추가하는 것만으로도 모델의 적절한 거부 행동이 상당히 회복되었다. Qwen2.5-7B 모델의 경우 SUM 테스트 세트에서 거부율이 0.01에서 0.73으로, Llama-3.1-8B-Instruct 모델은 0.00에서 0.75로 극적으로 개선되었다. 더욱 중요한 것은 이러한 개선이 해결 가능한 작업의 정확도에는 최소한의 영향만 미쳤다는 점이다.
수학 문제로 훈련했는데 사실 질문도 잘 거부: 0.01→0.94 놀라운 일반화
특히 주목할 만한 발견은 수학 문제로만 구성된 SUM 데이터셋으로 훈련된 모델이 완전히 다른 영역의 작업에서도 개선된 거부 행동을 보인다는 것이다. SelfAware라는 사실적 질의응답 벤치마크에서 Qwen2.5-7B 모델의 거부율이 0.01에서 0.94로, Qwen2.5-7B-Instruct 모델은 0.09에서 0.99로 향상되었다. 이는 모델들이 단순히 표면적 휴리스틱을 학습하는 것이 아니라, 추론 시간 계산을 활용해 질문이 명시되지 않았거나 답변 불가능한지 평가하고 자신의 지식 경계를 인식하는 방법을 학습한다는 것을 시사한다.
완벽한 균형점 찾기: 10% 혼합이 최적, 50%는 성능 저하 위험
연구진은 SUM 데이터의 혼합 비율에 따른 성능 변화도 분석했다. 0%, 1%, 10%, 30%, 50%의 다양한 혼합 비율을 실험한 결과, 높은 비율일수록 답변 불가능한 작업에서의 거부율은 향상되지만 답변 가능한 작업의 정확도는 감소하는 트레이드오프 관계를 확인했다. 대부분의 모델에서 10% 혼합 비율이 거부 행동 개선과 작업 성능 유지 사이의 적절한 균형점을 제공하는 것으로 나타났다.
연구진은 “높은 비율의 답변 불가능한 데이터(예: 50%)는 답변 가능한 벤치마크에서 성능을 저하시킬 수 있어 훈련 혼합의 신중한 조정이 필요하다”며 “미래 연구에서는 훈련 전반에 걸쳐 거부와 정확성을 동적으로 균형 맞추기 위한 커리큘럼 학습이나 적응적 보상 형성을 탐구할 수 있을 것”이라고 제안했다.
FAQ
Q: 강화학습 파인튜닝의 ‘환각 비용’이란 무엇인가요?
A: 강화학습 파인튜닝 후 AI 모델이 답할 수 없는 문제에 대해 적절히 거부하는 능력이 80% 이상 감소하여, 대신 그럴듯하지만 틀린 답변을 자신 있게 제시하는 현상을 의미합니다.
Q: SUM 데이터셋은 어떻게 AI 모델의 신뢰성을 향상시키나요?
A: SUM 데이터셋은 겉보기에는 해결 가능해 보이지만 실제로는 핵심 정보가 누락된 수학 문제들로 구성되어, 모델이 자신의 지식 한계를 인식하고 적절한 상황에서 “모르겠다”고 답하는 능력을 학습하게 합니다.
Q: 수학 문제로만 훈련해도 다른 영역에서 효과가 있나요?
A: 네, 수학 문제로만 구성된 SUM 데이터셋으로 훈련된 모델도 사실적 질의응답 등 완전히 다른 영역에서 거부 능력이 크게 향상되어, 일반적인 불확실성 추론 능력을 습득한다는 것이 확인되었습니다.
해당 기사에 인용한 논문 원문은 arxiv에서 확인 가능하다.
이미지 출처: 이디오그램 생성
이 기사는 챗GPT와 클로드를 활용해 작성되었습니다.




![[AI 트렌드] 말 한마디로 내 노래가 생긴다? 제미나이 음악 생성 프롬프트](https://aimatters.co.kr/wp-content/uploads/2026/03/AI-매터스-기사-썸네일-3.jpg)