
Reimagining Dance: Real-time Music Co-creation between Dancers and AI
전통적으로 무용은 음악에 맞춰 동작을 구성하는 일방향적 관계였다. 하지만 워털루 대학교(University of Waterloo)와 워드신스(WordSynth Inc.)의 연구진이 개발한 새로운 AI 시스템은 이러한 패러다임을 완전히 뒤바꾸고 있다. 댄서의 움직임이 실시간으로 음악을 만들어내는 양방향 창작 시스템이 무용과 AI의 새로운 가능성을 제시하고 있다.
음악이 춤을 따라가는 시대: 전통적 위계질서를 완전히 뒤바꾼 AI 시스템
기존 무용에서는 안무가가 음악에 맞춰 춤을 구성하거나 작곡가와 협업해 반주를 만드는 것이 일반적이었다. 즉흥 무용에서도 무용수는 미리 작곡된 음악이나 라이브 음악에 반응할 뿐, 음악 구성 자체에는 영향을 주지 못했다.
연구진이 개발한 시스템은 이러한 위계적 관계를 완전히 역전시켰다. 댄서가 움직임을 통해 음악 환경을 동적으로 형성할 수 있게 함으로써, 댄서를 단순한 연주자가 아닌 작곡가 역할까지 동시에 수행하는 창작자로 변화시켰다. 이는 인간의 움직임과 AI가 만든 사운드 간의 양방향 창작 파트너십을 구축하는 것이다.
128차원 잠재공간과 3.5초 클립: 웹캠 하나로 구현한 실시간 음악 생성의 비밀
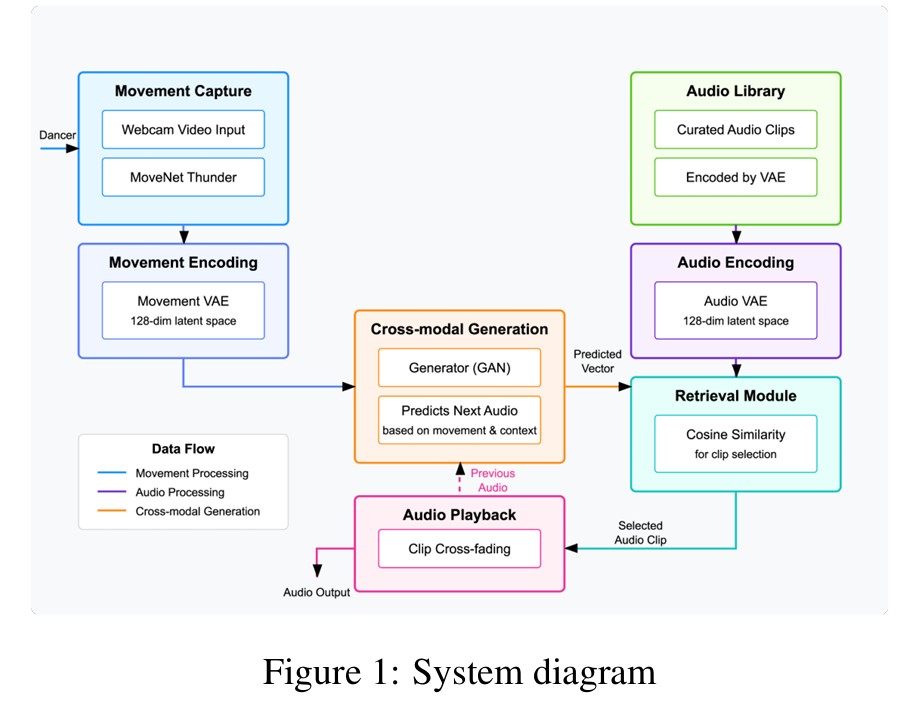
이 시스템의 핵심은 사전 녹음된 음악 클립들을 댄서의 움직임 패턴에 따라 지능적으로 선택하고 매끄럽게 결합하는 멀티모달 아키텍처다. 시스템은 세 가지 주요 구성 요소로 이루어져 있다. 첫째, 오디오 인코딩/디코딩 시스템은 변분 오토인코더(VAE)를 사용해 3.5초 길이의 오디오 클립 스펙트로그램을 학습한다. 128차원 잠재 공간 표현을 통해 의미 있는 음향 특성을 보존하면서 노이즈는 제거한다.
둘째, 움직임 인코딩 시스템은 텐서플로우 무브넷 썬더(TensorFlow MoveNet Thunder) 파이프라인을 사용해 댄서의 움직임을 분석한다. 머리, 양 손목, 양 발목 등 5개 핵심 랜드마크의 궤적을 컬러 코딩된 이미지로 변환해 시간에 따른 움직임의 시공간적 특성을 포착한다.
셋째, 생성적 적대 신경망(GAN)이 움직임과 오디오 도메인을 연결한다. 현재 움직임의 잠재 표현과 이전 오디오 클립의 잠재 표현을 입력받아 현재 움직임에 가장 적합한 다음 오디오 클립의 잠재 벡터를 예측한다.
70분 실험으로 증명된 놀라운 발견: 살짝 움직여도 AI가 알아채고 음악을 바꾼다
연구진은 발레를 10년 이상 춘 전문가부터 춤을 전혀 모르는 일반인까지 3명을 대상으로 실험을 진행했다. 각자 최대 30분씩 AI와 함께 자유롭게 춤을 췄고, 총 70분이 넘는 데이터를 모았다. 실험 결과 놀라운 사실이 밝혀졌다. AI는 댄서가 아주 작게 움직이는 순간까지도 정확히 포착해서 음악을 만들어냈다는 것이다. 수치로 표현하면 -0.45라는 상관관계가 나왔는데, 이는 통계학적으로 매우 의미 있는 수준이다. 쉽게 말해 댄서가 움직임을 최소화할수록 AI가 더 부드럽고 차분한 음악을 선택한다는 뜻이다.
더 구체적으로 살펴보면, AI는 음성의 ‘톤’에 해당하는 음향 특성을 분석해서 댄서의 움직임 강도를 판단한다. 마치 사람이 목소리 톤으로 상대방의 감정을 읽듯이, AI도 댄서의 움직임에서 에너지 레벨을 읽어내는 것이다. 추가 분석에서는 음성의 높낮이 변화와 주파수 대역별 음량 차이 등이 움직임 예측에 가장 중요한 요소로 확인됐다.
5-10초 적응시간으로 완성되는 마법: 댄서와 AI가 주도권을 주고받는 협업의 순간들
참가자들은 공연 전반에 걸쳐 시스템과 유동적인 주도권 교환을 경험했다고 보고했다. 시스템이 거시적, 미시적 수준에서 움직임 선택에 영향을 주면서 새로운 춤 표현을 탐색하도록 영감을 줬다. 반대로 댄서들은 앰비언트 음악이 나올 때 역동적인 움직임을 도입해 음악적 분위기를 의도적으로 바꾸려 시도하기도 했다.
시스템이 춤 에너지의 큰 변화에 적응하는 데 5-10초가 소요되지만, 이는 음악적 일관성을 유지하기 위해 의도적으로 설계된 것이다. 이러한 적응 기간은 반응성과 음악적 연속성 사이의 균형을 맞추면서 춤 장르의 선호도에 따라 맞춤화될 수 있다.
무용 공연을 넘어선 무한한 가능성: 운동부터 치료까지 확장되는 AI 협업의 미래
이 시스템의 잠재력은 무용 공연을 훨씬 넘어선다. 파일럿 연구에서 흥미로운 현상이 관찰됐다. 참가자들이 피로를 느껴 자연스럽게 움직임 강도를 줄이면, 시스템이 역동적인 리듬 음악에서 더 차분한 앰비언트 사운드스케이프로 유기적으로 전환했다. 이러한 적응적 특성은 운동과 훈련 환경에서도 유용할 수 있다.
연구진은 현재 전문 무용단과의 대규모 연구를 계획 중이다. 이를 통해 안무 과정에서 시스템이 미치는 영향과 관객 반응을 평가할 예정이다. 더 나아가 인간 댄서와 AI 음악 협력자 사이에 진화하는 창작 언어에 대한 더 깊은 이해를 개발하는 것이 목표다.
이 연구가 제시하는 다층적 창작 관계는 특히 주목할 만하다. 원래 작곡가의 음악적 의도가 새로운 창발적 구성을 위한 원재료가 되고, 댄서의 움직임을 통해 동적으로 재배열되고 리믹스된다. 결과적으로 나오는 음향 경험은 원래 구성 요소, 시스템의 알고리즘적 의사결정, 댄서의 구현된 표현이라는 세 가지 창작력이 수렴하는 실시간 콜라주 형태다. 각 공연은 이러한 창작 개체들 간의 독특한 관계를 나타내며, 어느 하나도 독립적으로는 만들어낼 수 없는 새로운 것을 창조한다.
FAQ
Q: AI가 댄서의 움직임을 어떻게 음악으로 변환하나요?
A: 시스템은 댄서의 움직임을 웹캠으로 포착해 AI가 분석한 뒤, 움직임 패턴에 가장 적합한 음악 클립을 데이터베이스에서 선택해 실시간으로 재생합니다. 마치 댄서가 지휘자처럼 움직임으로 음악을 만들어내는 것입니다.
Q: 기존 무용과 이 시스템의 가장 큰 차이점은 무엇인가요?
A: 전통적으로 무용은 음악에 맞춰 움직이는 일방향적 관계였지만, 이 시스템은 댄서의 움직임이 음악을 만들어내는 양방향 협업을 가능하게 합니다. 댄서가 연주자와 작곡가 역할을 동시에 수행하게 되는 것입니다.
Q: 무용 경험이 없어도 이 시스템을 사용할 수 있나요?
A: 네, 연구에서 무용 경험이 없는 일반인도 시스템과 성공적으로 상호작용했습니다. 시스템이 사용자의 움직임 강도에 따라 자동으로 적응하므로, 전문적인 무용 기술 없이도 창작적 경험을 할 수 있습니다.
해당 기사에 인용된 리포트 원문은 arxiv에서 확인 가능하다.
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





