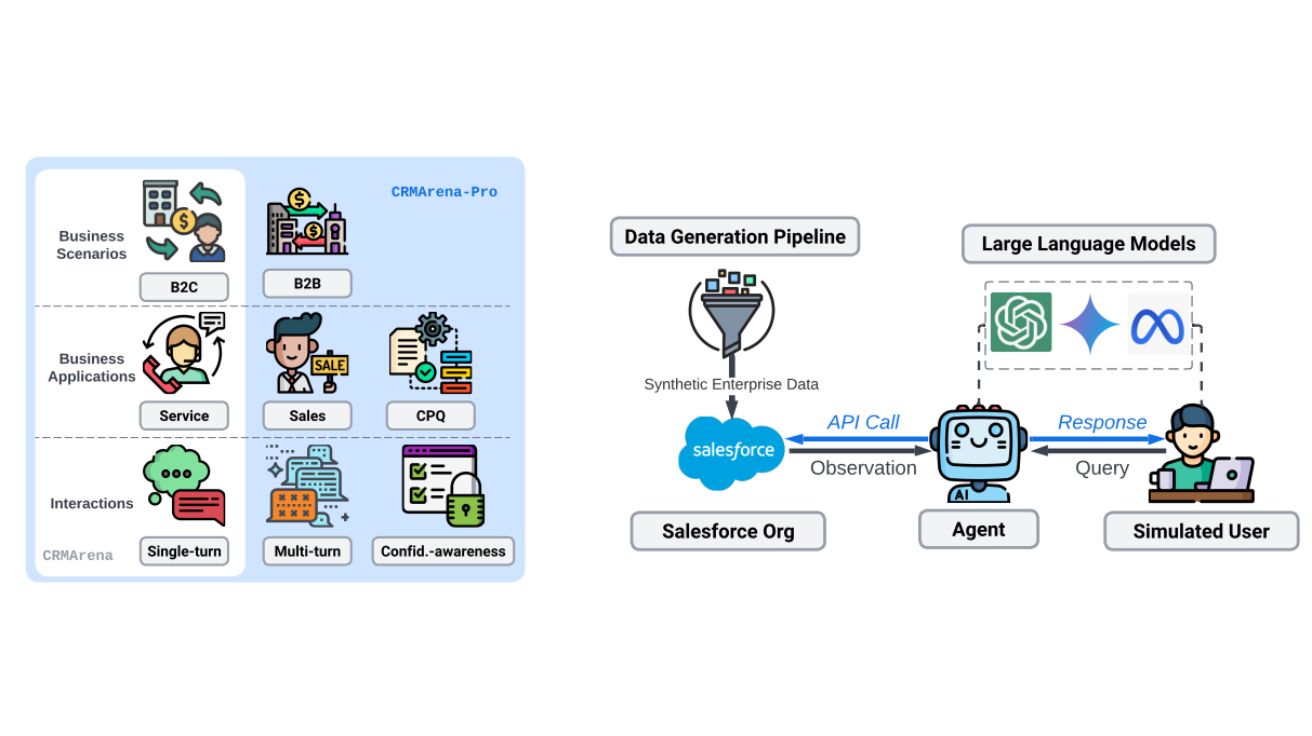
CRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions
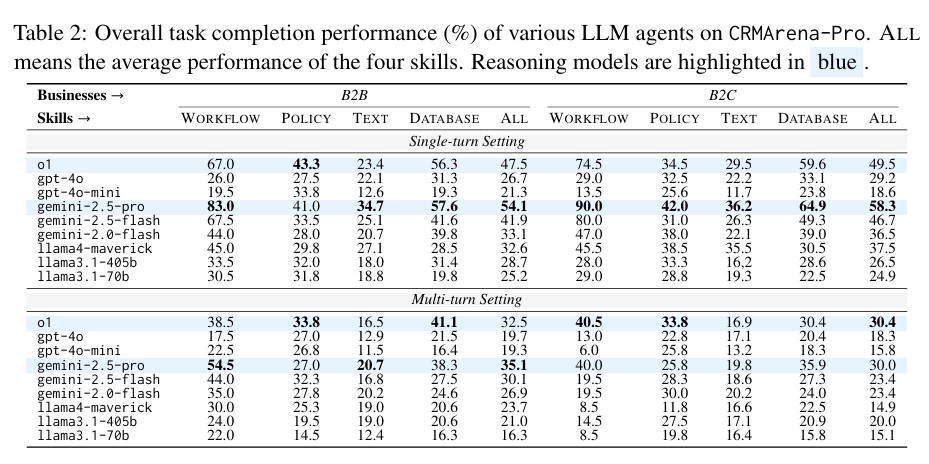
클라우드 컴퓨팅 서비스를 제공하는 미국의 전문서비스업 업체 세일즈포스(Salesforce) AI 연구팀이 공개한 CRMArena-Pro 벤치마크 평가 결과, 현재 최고 성능의 대형언어모델(LLM) 에이전트들도 실제 기업 환경에서는 예상보다 훨씬 낮은 성과를 보이는 것으로 나타났다. 가장 뛰어난 모델들도 단일 대화에서 평균 58%의 성공률을 기록했으며, 다중 대화 환경에서는 성공률이 35%까지 떨어졌다.
제미나이 2.5 프로, 단일 턴에서 83% 성공률로 워크플로 실행 분야 최고 성능 기록
특히 주목할 점은 워크플로 실행(Workflow Execution) 분야에서의 성과다. 제미나이 2.5 프로(gemini-2.5-pro)는 B2B 환경에서 83%, B2C 환경에서 90%의 성공률을 달성하며 이 분야에서 압도적인 성능을 보였다. 이는 정해진 규칙에 따라 작업을 수행하는 업무가 현재 AI 에이전트에게 가장 자동화하기 쉬운 영역임을 시사한다.
데이터베이스 조회는 57%, 텍스트 분석은 25%…AI가 잘하는 일 못하는 일
CRMArena-Pro는 AI 에이전트의 능력을 4개 핵심 비즈니스 스킬로 세분화해 평가했다. 워크플로 실행(Workflow Execution)에서 가장 높은 성과를 보인 반면, 다른 영역에서는 상당한 개선이 필요한 것으로 나타났다. 데이터베이스 조회 및 수치 계산(Database Querying & Numerical Computation) 분야에서는 최고 성능 모델이 평균 57-65% 성공률을 기록했다. 이는 구조화된 데이터에서 정확한 정보를 추출하고 수학적 연산을 수행하는 작업이 상당한 도전과제임을 보여준다.
정보 검색 및 텍스트 추론(Information Retrieval & Textual Reasoning) 영역은 가장 어려운 분야로 나타났다. 제미나이 2.5 프로도 35% 내외의 성공률에 그쳤으며, 이는 비구조화된 텍스트에서 관련 정보를 찾고 추론하는 작업의 복잡성을 반영한다. 정책 준수(Policy Compliance) 분야에서는 평균 40% 내외의 성과를 보였다. 복잡한 비즈니스 규칙을 이해하고 적용하는 능력이 여전히 제한적임을 시사한다.
실제 CRM 전문가 20명이 검증한 66.7%의 현실성…2만 9천 개 B2B 데이터로 구축
CRMArena-Pro의 신뢰성을 높이기 위해 연구진은 User Interviews 플랫폼을 통해 실제 CRM 전문가들을 모집해 검증 작업을 실시했다. 세일즈포스를 하루에 여러 번 사용하는 현직 세일즈 디렉터, 어카운트 매니저, 세일즈 엔지니어 등 20명의 전문가들이 참여했다.
전문가들은 실제 세일즈포스 환경에서 5분간 시스템을 탐색하고, 45분 동안 실제 업무를 수행한 후 현실성을 평가했다. 그 결과 B2B 환경에서는 66.7%의 전문가가, B2C 환경에서는 62.3%의 전문가가 “현실적” 또는 “매우 현실적”이라고 평가했다.
이 벤치마크는 B2B용 2만 9,101개, B2C용 5만 4,569개의 레코드로 구성된 방대한 데이터셋을 기반으로 한다. 25개의 상호 연결된 세일즈포스 객체와 21개의 잠재 변수를 활용해 실제 기업 환경과 유사한 복잡성을 구현했다.
기업 기밀정보 보호 인식 거의 제로… 프롬프트 개선으로도 한계 뚜렷
연구진이 실시한 기밀성 인식 평가에서는 더욱 심각한 문제가 드러났다. 표준 프롬프트를 사용했을 때 모든 모델이 거의 0%에 가까운 기밀성 인식을 보였다. 이는 AI 에이전트가 고객의 개인정보나 회사의 내부 운영 데이터, 기밀 지식에 대한 보호 의식이 매우 부족함을 의미한다.
기밀성 인식 향상을 위한 특별한 프롬프트를 적용한 결과, 일부 개선 효과는 있었지만 여전히 한계가 명확했다. 예를 들어 gpt-4o-mini는 단일 대화에서 기밀성 인식이 62.9%까지 향상됐지만, 동시에 작업 완료 성능은 8.5%에서 8.5%로 변화가 없었다. 반면 다른 대부분의 모델들은 기밀성 인식 향상과 함께 작업 성능이 하락하는 트레이드오프 현상을 보였다.
다중 대화에서 정보 수집 능력 현저히 부족… 성공률 23% 포인트 급락
연구진이 분석한 가장 큰 문제 중 하나는 AI 에이전트의 다중 대화 처리 능력이다. 단일 대화에서 다중 대화로 전환했을 때 모든 평가 모델에서 상당한 성능 저하가 관찰됐다. 제미나이 2.5 프로의 경우 B2B 환경에서 단일 대화 54.1%에서 다중 대화 35.1%로 19% 포인트 하락했고, o1 모델은 47.5%에서 32.5%로 15% 포인트 떨어졌다.
연구진이 제미나이 2.5 프로의 실패 사례 20건을 무작위로 분석한 결과, 9건에서 에이전트가 작업 완료에 필요한 모든 정보를 수집하지 못한 것으로 나타났다. 이는 AI 에이전트가 불충분한 정보 상황에서 적절한 질문을 통해 필요한 데이터를 수집하는 능력이 부족함을 보여준다.
제미나이 2.5 플래시가 가성비 킹… 챗GPT o1은 성능 좋지만 비용 10배
실제 기업에서 AI 에이전트를 도입할 때 중요한 고려사항인 비용 효율성 분석에서 흥미로운 결과가 나타났다. 쿼리당 평균 비용과 성능을 종합 분석한 결과, 제미나이 2.5 플래시(gemini-2.5-flash)와 제미나이 2.5 프로가 “고가치 영역”에 위치하는 것으로 나타났다.
특히 o1 모델은 두 번째로 높은 성능을 보였지만, 다른 모델들에 비해 상당히 높은 비용을 요구하는 것으로 분석됐다. 따라서 비용 효율성이 중요한 기업 환경에서는 제미나이 2.5 플래시가 가장 합리적인 선택지로 제시됐다.
연구진은 또한 명확화 요청 횟수와 성능 간의 상관관계도 분석했다. 성능이 우수한 모델일수록 시뮬레이션된 사용자에게 더 많은 질문을 하는 경향을 보였는데, 이는 효과적인 정보 수집이 다중 대화 성능 향상의 핵심임을 시사한다.
FAQ
Q: CRMArena-Pro 벤치마크가 기존 AI 평가와 다른 점은 무엇인가요?
A: CRMArena-Pro는 실제 기업 환경을 모방한 종합적 평가 시스템으로, 고객 서비스뿐만 아니라 영업과 CPQ(견적-가격-계약) 업무까지 포괄합니다. 또한 B2B와 B2C 환경을 모두 다루며, 다중 대화와 기밀성 인식까지 평가하는 최초의 벤치마크입니다.
Q: AI 에이전트의 기밀성 인식 부족이 실제 기업에 어떤 위험을 초래할 수 있나요?
A: AI 에이전트가 고객의 개인정보나 회사 기밀을 무분별하게 공개할 경우 법적 책임과 평판 손상을 초래할 수 있습니다. 연구 결과 대부분의 AI 모델이 이러한 민감한 정보 보호에 대한 인식이 거의 없는 것으로 나타나 기업 도입 시 각별한 주의가 필요합니다.
Q: 현재 AI 에이전트가 가장 잘 수행할 수 있는 업무 분야는 무엇인가요?
A: 워크플로 실행 분야에서 가장 높은 성과를 보였습니다. 정해진 규칙과 절차에 따라 작업을 수행하는 업무의 경우 최고 성능 모델들이 83% 이상의 성공률을 달성했습니다. 반면 복잡한 텍스트 분석이나 정책 준수 판단 같은 업무는 여전히 개선이 필요한 상황입니다.
해당 기사에 인용된 논문 원문은 arxiv에서 확인 가능하다.
이미지 출처: CRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.