엔비디아(NVIDIA)와 국립대만대학교 연구팀이 발표한 새로운 AI 시스템 ThinkAct가 로봇 기술에 혁명을 일으키고 있다. 기존 로봇들이 명령을 받으면 즉시 행동했던 것과 달리, 이 시스템은 마치 사람처럼 먼저 생각하고 계획을 세운 후 행동하는 획기적인 방식을 사용한다.
기존 로봇의 한계를 뛰어넘은 똑똑한 이중 뇌 구조
지금까지의 로봇들은 눈으로 본 것과 받은 명령을 바로 움직임으로 바꾸는 단순한 방식을 사용했다. 이런 방법은 간단한 일에서는 괜찮았지만, 복잡하고 오래 걸리는 작업이나 예상치 못한 상황이 생기면 제대로 대응하지 못했다.
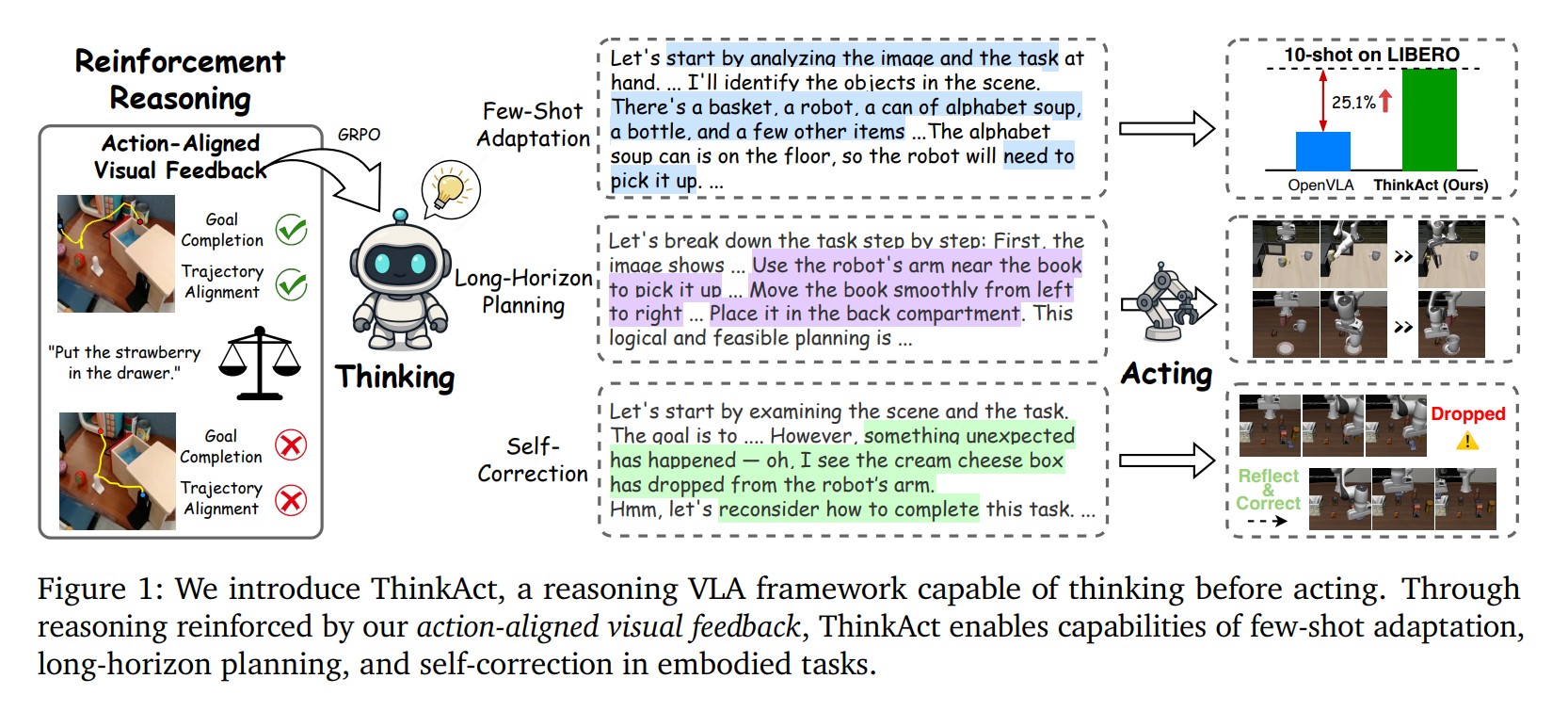
ThinkAct는 이 문제를 해결하기 위해 마치 사람의 뇌처럼 생각하는 부분과 몸을 움직이는 부분을 나누어 만들었다. 첫 번째 부분인 ‘생각하는 AI’는 상황을 살펴보고 어떻게 할지 단계별로 계획을 세운다. 두 번째 부분인 ‘행동하는 AI’는 이 계획을 받아서 실제로 로봇이 움직일 수 있는 구체적인 동작을 만들어낸다.
이 두 부분은 ‘시각적 계획 정보’라는 압축된 데이터로 연결된다. 생각하는 AI가 세운 계획과 의도가 이 정보에 담겨서 행동하는 AI로 전달되고, 최종적으로 환경에 맞는 실제 동작으로 바뀐다.
시행착오를 통해 스스로 학습하는 새로운 훈련 방법
ThinkAct의 또 다른 혁신은 로봇이 시행착오를 통해 스스로 학습하는 방법이다. 기존 시스템들이 단순히 성공했는지 실패했는지만 확인했다면, ThinkAct는 훨씬 더 세밀하게 로봇의 행동을 평가한다. 구체적으로 ‘목표 달성 점수’는 로봇 팔의 시작점과 끝점이 올바른 위치에 있는지 확인한다. ‘움직임 경로 점수’는 로봇이 목표까지 가는 길이 자연스럽고 효율적인지 평가한다. 이런 이중 평가 시스템 덕분에 로봇은 단순히 목표에 도착하는 것뿐만 아니라 어떻게 가야 가장 좋은지까지 배우게 된다.
마치 사람이 처음 자전거를 배울 때 넘어지면서도 점점 더 안정적으로 타는 법을 익히는 것처럼, 로봇도 반복 학습을 통해 더 나은 움직임을 찾아낸다.
실험에서 증명된 압도적 성능, 84.4% 성공률 달성
ThinkAct의 놀라운 능력은 다양한 테스트를 통해 입증되었다. 로봇이 물건을 집고 옮기는 작업을 평가하는 LIBERO라는 테스트에서 ThinkAct는 84.4%의 성공률을 기록했다. 이는 기존 최고 성능 로봇보다 훨씬 높은 수치다. 특히 여러 단계를 거쳐야 하는 복잡한 작업에서는 70.9%의 성공률을 달성해 이전 로봇들보다 큰 발전을 보였다.
다른 테스트인 SimplerEnv에서도 ThinkAct는 71.5%부터 43.8%까지 다양한 상황에서 높은 성공률을 기록하며 모든 비교 대상을 앞섰다. 이는 기존 로봇 대비 15% 이상의 개선을 의미한다. 더욱 놀라운 것은 로봇이 상황을 이해하고 추론하는 능력이다. 복잡한 질문에 답하는 테스트에서도 48.2%의 정확도를 달성하며, 단순히 움직이기만 하는 것이 아니라 정말로 ‘생각’할 수 있다는 것을 보여줬다.
실수해도 포기하지 않는 로봇, 스스로 문제를 해결하다
ThinkAct의 가장 놀라운 능력은 실수를 했을 때 스스로 문제를 찾아내고 고치는 것이다. 연구팀이 공개한 실험 영상에서 로봇이 크림치즈 상자를 바구니에 넣는 작업 중 실수로 상자를 떨어뜨렸을 때, 시스템은 “어? 예상치 못한 일이 일어났네요”라고 인식하고 상황을 다시 살펴본 후 새로운 방법을 찾아 작업을 성공적으로 마쳤다.
이는 단순히 미리 프로그래밍된 반응이 아니라 상황을 이해하고 생각을 통해 해결책을 찾아내는 진짜 지능의 모습이다. 로봇은 이전에 한 행동들을 돌아보고 뭔가 잘못되었다는 것을 깨달으면 “이 일을 끝내는 다른 방법을 생각해보자”라며 스스로 새로운 계획을 세운다. 마치 사람이 요리하다가 재료를 떨어뜨렸을 때 당황하지 않고 다시 집어서 계속 요리하는 것처럼, 이 로봇도 유연하게 상황에 대응할 수 있다.
FAQ
Q: ThinkAct가 기존 로봇과 어떻게 다른가요?
A: 기존 로봇들은 명령을 받으면 즉시 행동했지만, ThinkAct는 사람처럼 먼저 상황을 살펴보고 계획을 세운 후 행동합니다. 덕분에 복잡하고 오래 걸리는 일이나 예상치 못한 상황에서도 훨씬 잘 대응할 수 있습니다.
Q: 로봇이 어떻게 스스로 학습하나요?
A: ThinkAct는 로봇의 행동을 단순히 성공/실패로만 평가하지 않고, 목표 도달 여부와 움직임의 자연스러움을 모두 확인합니다. 마치 사람이 자전거 타기를 배울 때처럼 반복 연습을 통해 점점 더 나은 방법을 찾아냅니다.
Q: 로봇이 실수했을 때 어떻게 스스로 고치나요?
A: 로봇이 실수를 하면 “어? 뭔가 잘못됐네”라고 인식하고 상황을 다시 살펴봅니다. 그리고 “다른 방법을 써보자”라며 새로운 계획을 세워서 문제를 해결합니다. 사람이 요리하다 재료를 떨어뜨려도 다시 집어서 계속하는 것과 비슷합니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문 명: ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.