미국 템플대학교(Temple University) 연구진이 자폐 스펙트럼 장애나 언어 발달 지연을 겪는 아이들을 위한 의사소통 보조 도구 제작에 생성형 인공지능을 활용하는 연구를 진행했다. 이 연구의 목적은 전문가가 아닌 사람도 쉽게 시각 장면 디스플레이(Visual Scene Display, VSD)를 만들 수 있도록 돕는 것이었다.
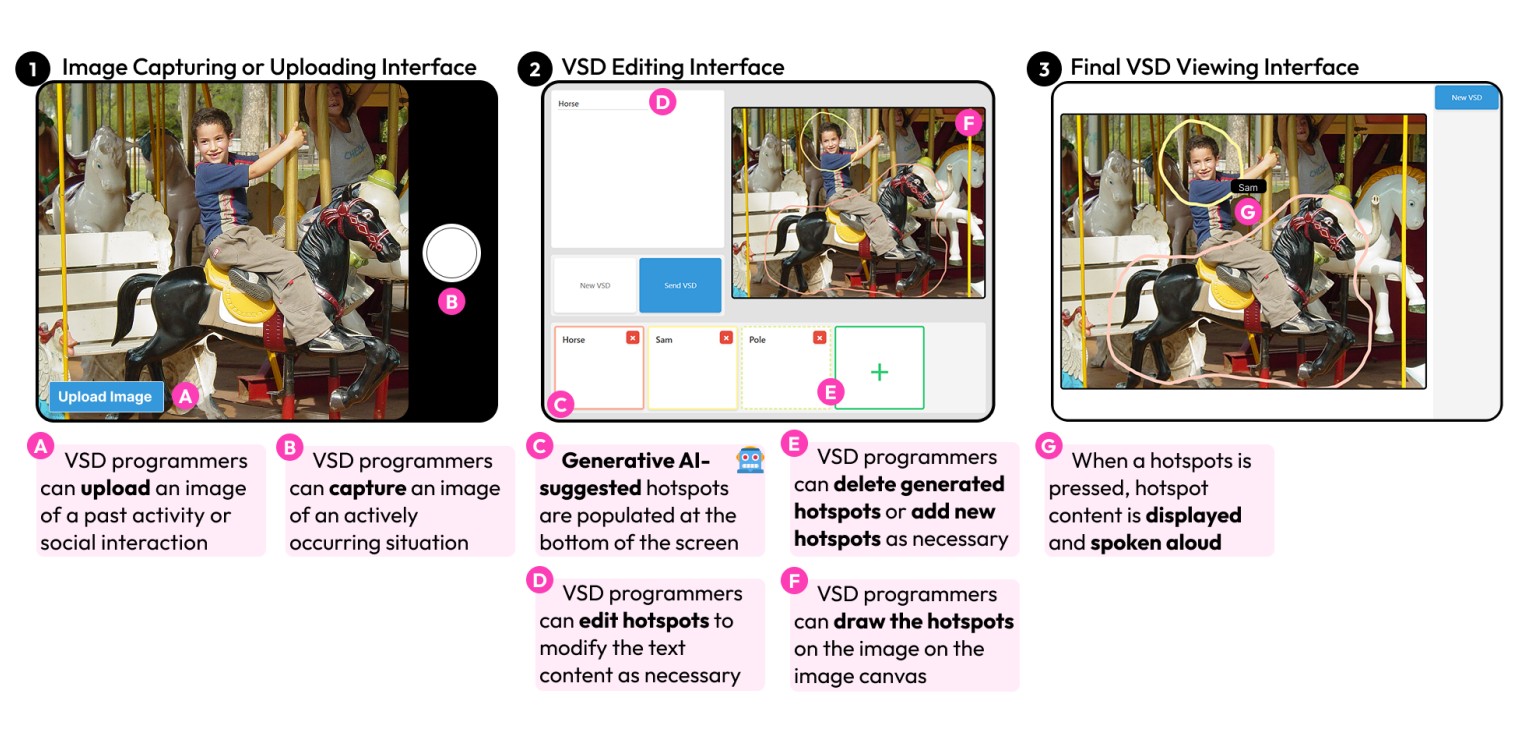
자폐 스펙트럼 장애나 언어 발달 지연을 겪는 아이들은 말로 의사소통하기 어려워한다. 이런 아이들을 위해 개발된 것이 바로 시각 장면 디스플레이라는 기술이다. 이는 실제 사진 위에 터치할 수 있는 영역을 만들어서, 아이가 그 부분을 누르면 해당하는 단어나 문장이 음성으로 나오는 방식이다. 예를 들어 놀이터 사진에서 그네 부분을 누르면 “그네”라고 말해주는 식이다.
연구진은 이런 VSD를 만드는 과정을 더 쉽게 하기 위해 생성형 인공지능을 활용한 시스템을 개발했다. 기존에는 언어치료사가 사진을 보고 일일이 어떤 부분에 어떤 단어를 연결할지 결정해야 했는데, 이제는 사진을 업로드하면 챗GPT의 언어 모델 중 하나인 GPT-4o가 자동으로 적절한 위치와 단어들을 제안해준다.
14초 단축과 신뢰도 향상, 하지만 터치 영역 과다 생성 문제 발견
16명의 예비 언어치료사들을 대상으로 한 실험에서, 인공지능의 도움을 받았을 때 VSD를 만드는 시간이 평균 77초에서 63.5초로 단축되었다. 또한 참가자들은 자신이 만든 VSD에 대해 더 높은 신뢰감을 보였다.
하지만 만들어진 VSD의 품질을 살펴보면 결과가 엇갈렸다. 좋은 점은 아이들의 발달 수준에 맞는 단일 단어를 더 많이 사용했다는 것이다. 인공지능 도움을 받은 경우 91.5%가 단일 단어였고, 기존 방식으로는 78.7%였다. 단일 단어를 사용하는 것이 아이들이 나중에 여러 단어를 조합해서 복잡한 의사소통을 할 수 있게 도와주기 때문에 이는 긍정적인 결과다.
하지만 문제점도 있었다. 인공지능의 도움을 받으면 터치 영역을 너무 많이 만드는 경향이 있었고, 사진의 주요 내용과 직접 관련이 없는 영역까지 포함시키는 경우가 많았다. 이는 아이들에게 혼란을 줄 수 있다.
77%가 AI 제안 그대로 사용, 개인화 역할 22%로 축소
연구에서 가장 우려스러운 발견은 언어치료사들이 인공지능의 제안을 거의 그대로 받아들인다는 점이었다. 인공지능이 제안한 터치 영역의 61.8%가 수정 없이 그대로 사용되었고, 전체 터치 영역의 77.1%가 인공지능이 생성한 것이었다. 언어치료사가 직접 추가한 부분은 22.9%에 불과했다.
이는 문제가 될 수 있다. 왜냐하면 VSD가 효과적이려면 각 아이의 개별적인 특성과 관심사에 맞춰 개인화되어야 하기 때문이다. 예를 들어 공룡을 좋아하는 아이에게는 공룡 관련 단어를, 음악을 좋아하는 아이에게는 악기 관련 단어를 넣어주는 식으로 말이다. 하지만 인공지능의 제안에만 의존하면 이런 개인화가 어려워진다.
독특한 의사소통 옵션 54%에서 37%로 급감, 사회적 상호작용 기능 0.7%까지 하락
연구진이 발견한 가장 심각한 문제는 인공지능의 도움을 받아 만든 VSD들이 서로 매우 비슷해진다는 것이었다. 컴퓨터 분석을 통해 살펴본 결과, 인공지능 도움을 받은 경우 만들어진 의사소통 옵션들이 평균적인 패턴과 더 유사했다. 또한 독특하고 창의적인 터치 영역의 비율도 36.6%로, 기존 방식의 54.3%보다 현저히 낮았다.
특히 사회적 관계를 위한 의사소통 기능이 크게 줄어든 점도 문제였다. 기존 방식에서는 “안녕”, “고마워” 같은 사회적 상호작용을 위한 단어가 5.3% 포함되었지만, 인공지능 도움을 받은 경우에는 0.7%에 불과했다. 이는 아이들이 다른 사람과 관계를 맺고 사회적 기술을 익히는 데 중요한 부분이 빠질 수 있음을 의미한다.
효율성과 개인화 사이의 딜레마, 안전장치 마련이 시급
이 연구는 인공지능이 언어치료 분야에서 효율성을 높일 수 있지만, 동시에 주의깊게 접근해야 할 위험성도 있음을 보여준다. 인공지능의 도움으로 언어치료사들이 더 빠르고 자신감 있게 의사소통 도구를 만들 수 있게 되었지만, 각 아이에게 맞는 개별화된 접근과 다양한 의사소통 옵션 제공이라는 핵심 가치가 약화될 수 있다는 것이다.
연구진은 이런 문제들을 해결하기 위해서는 인공지능 시스템에 적절한 안전장치를 마련하고, 언어치료사들이 인공지능의 제안을 비판적으로 검토할 수 있도록 돕는 기능이 필요하다고 제안했다.
FAQ
Q: 시각 장면 디스플레이가 일반적인 의사소통 보조 기기와 어떻게 다른가요?
A: 기존 기기들은 추상적인 그림 기호들을 격자 형태로 배열했다면, 시각 장면 디스플레이는 실제 사진을 사용해서 아이들이 친숙한 상황에서 언어를 배울 수 있도록 돕습니다.
Q: 인공지능이 의사소통 보조 기기에 사용될 때 왜 획일화가 문제가 되나요?
A: 의사소통 보조 기기는 각 사용자의 관심사, 생활환경, 발달 수준에 맞춰 개인화되어야 효과적인데, 모든 사용자에게 비슷한 옵션을 제공하면 개별 아이의 특성을 반영하지 못해 효과가 떨어집니다.
Q: 이런 연구 결과가 실제 언어치료 현장에 어떤 영향을 미칠까요?
A: 인공지능 기술을 도입할 때 효율성뿐만 아니라 개인화와 다양성도 함께 고려해야 한다는 중요한 지침을 제공하며, 기술과 전문가의 판단이 균형있게 결합되어야 함을 보여줍니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문 명: Helping or Homogenizing? GenAI as a Design Partner to Pre-Service SLPs for Just-in-Time Programming of AAC
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.