애플이 이미지와 텍스트를 함께 이해하는 새로운 AI 모델 ‘FastVLM’을 공개했다. 이 모델은 기존 AI보다 3.2배 빠르게 이미지를 분석하고 답변을 생성할 수 있으면서도 정확도는 그대로 유지한다. FastVLM의 핵심은 고화질 이미지를 효율적으로 처리하는 새로운 기술 ‘FastViTHD’다.
실제 하드웨어에서 85배 빠른 속도 구현, 다양한 모델 크기 지원
FastVLM의 가장 인상적인 특징은 M1 맥북 프로에서 실제 측정한 놀라운 속도 개선이다. 같은 크기의 언어 모델을 사용했을 때 기존 LLaVA-OneVision AI 모델보다 85배 빠르게 첫 번째 답변을 생성한다. 이는 TTFT(Time-to-First-Token)라고 불리는 지표로 측정되는데, 이미지를 이해하는 시간과 언어 모델이 답변을 준비하는 시간을 합친 것이다.
더욱 놀라운 점은 이 성능을 모델 크기를 3.4배나 줄이면서 달성했다는 것이다. FastVLM은 0.5B부터 7B까지 다양한 크기의 언어 모델과 결합하여 사용할 수 있으며, 각각에서 우수한 성능을 보였다.
5단계 구조로 설계된 FastViTHD, 64배 압축 기술 적용
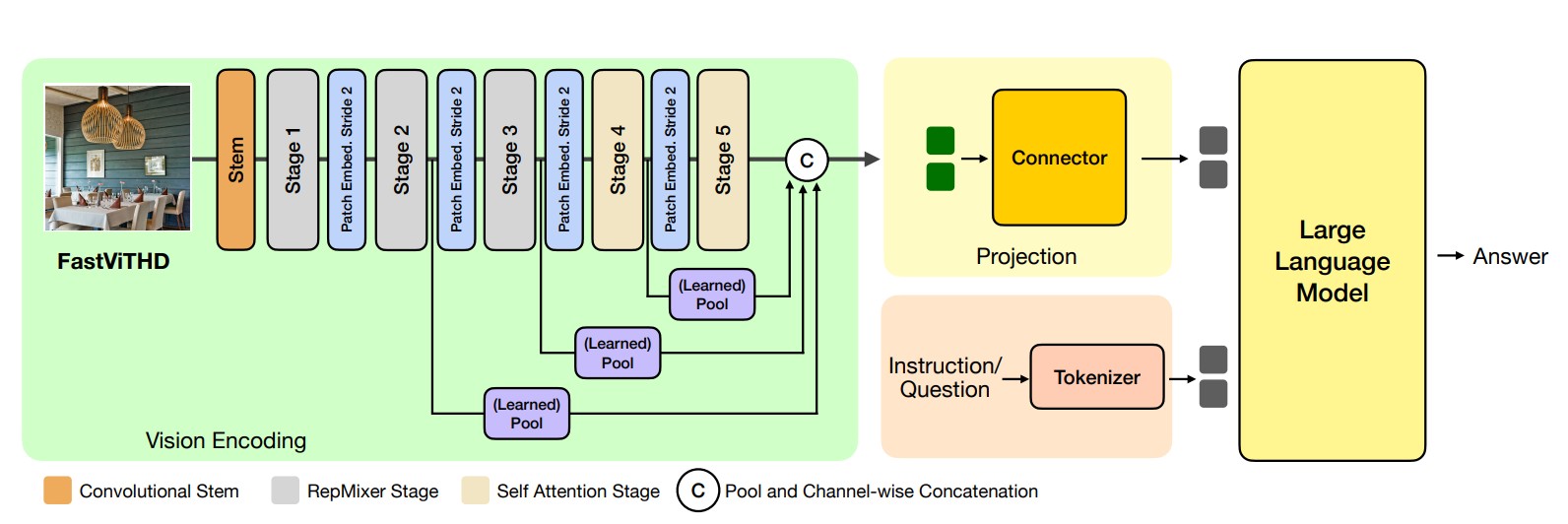
FastVLM의 핵심 기술인 FastViTHD는 이미지에서 추출하는 정보량을 기존 모델의 16분의 1로 줄였다. 이 기술은 5단계로 구성된 독특한 구조를 가지고 있다. 처음 3단계에서는 RepMixer라는 효율적인 처리 방식을 사용하고, 마지막 2단계에서는 셀프 어텐션이라는 정교한 분석 방식을 적용한다.
단계별로 2개, 12개, 24개, 4개, 2개의 계층을 가지며, 정보 처리 용량도 96차원부터 1536차원까지 점진적으로 확장된다. 특히 기존 모델이 16배 압축을 했다면, FastViTHD는 64배 압축을 통해 더욱 효율적인 처리가 가능하다. 이 모델은 DataCompDR-1B라는 대규모 데이터셋으로 미리 훈련되었다.
구체적인 수치로 입증된 뛰어난 성능
FastVLM은 텍스트가 많이 포함된 이미지를 이해하는 데 탁월한 능력을 보였다. 주요 AI 성능 평가에서 구체적인 수치로 우수성을 입증했다. GQA 일반 지식 평가에서 63.1점, 과학 문제 해결에서 81.5점, 텍스트 인식에서 62.9점, 문서 분석에서 70.4점을 기록했다.
특히 기존에 널리 사용되던 ConvNeXT-L 모델과 비교했을 때 2.3배 빠른 속도와 1.7배 작은 크기를 달성했고, SigLIP-SO400M 모델 대비해서는 3.2배 빠른 속도와 3.6배 작은 크기를 기록했다. 토큰 프루닝이라는 기존 속도 개선 방법들과 비교해도 FastVLM이 더 나은 성능을 보였다.
정적 해상도 방식으로 최적화, 최대 2048×2048 처리 가능
FastVLM은 이미지를 여러 단계로 나누어 각각 다른 크기의 정보를 추출한 후 이를 종합해 최종 결과를 만든다. 연구진이 정적 해상도와 동적 해상도 방식을 비교한 결과, 이미지를 작은 조각으로 나누는 타일링 방식보다는 전체 이미지를 한 번에 처리하는 정적 방식이 더 효과적임을 발견했다.
FastVLM은 간단한 2×2 그리드 방식을 사용해 최대 2048×2048 해상도까지 처리할 수 있다. 이는 기존 InternVL2 모델이 36개의 조각으로 나누어 처리하는 것과 달리, 단 4개의 조각만으로 고해상도 이미지를 처리할 수 있다는 의미다. 동적 해상도는 메모리 용량이 제한적인 상황에서만 유리한 것으로 나타났다.
체계적인 훈련 과정과 대규모 데이터 활용
FastVLM의 뛰어난 성능은 체계적인 훈련 과정에서 나온다. 2단계 또는 3단계로 나누어 훈련하는데, 첫 번째 단계에서는 이미지와 텍스트를 연결하는 부분만 학습시키고, 두 번째 단계에서는 전체 모델을 함께 훈련시킨다.
특히 대규모 데이터를 활용한 효과가 두드러진다. 1500만 개의 이미지-텍스트 쌍으로 사전 훈련하고, 110만 개에서 1250만 개까지 다양한 크기의 지시 학습 데이터를 사용했다. 데이터 양이 증가할수록 성능도 비례해서 향상되는 것을 확인했다. 이는 FastVLM이 더 큰 모델들과 경쟁할 수 있는 기반이 되었다.
복수 AI 모델 조합보다 단일 모델로 더 나은 성능
최근 AI 업계에서는 여러 개의 서로 다른 AI 모델을 조합해 성능을 높이는 방식이 유행하고 있다. 하지만 FastVLM은 단일 모델만으로도 이런 복합 모델들을 능가하는 성능을 보였다. 4개의 서로 다른 AI 모델을 조합한 Cambrian-1과 비교했을 때, FastVLM이 7.9배 빠른 속도를 보이면서도 더 나은 정확도를 기록했다. 또한 MiniGemini처럼 복수의 비전 처리 기술을 사용하는 모델들과 비교해도 우수한 성능을 보였다. 이는 효율적인 단일 모델 설계가 복잡한 조합보다 더 실용적일 수 있음을 보여준다.
동시 발표 모델들과의 치열한 경쟁에서 우위 확보
FastVLM과 비슷한 시기에 발표된 다른 AI 모델들과의 비교에서도 경쟁력을 입증했다. SmolVLM2와 비교했을 때 8.2배 적은 정보량으로도 차트 분석과 텍스트 인식에서 더 나은 성능을 보였다. FlorenceVL과 비교해서는 2.3배 적은 정보량과 6.2배 작은 모델 크기로 문서 분석에서 우수한 결과를 달성했다. 특히 지식 기반 평가에서는 모든 경쟁 모델을 앞섰다. 가장 작은 크기의 FastVLM도 비슷한 크기의 SmolVLM2보다 4.3배 적은 정보량으로 더 나은 성능을 보여 효율성의 우수함을 입증했다.
FAQ
Q: FastVLM은 어떤 용도로 활용할 수 있나요?
A: 문서나 차트가 포함된 이미지를 분석하거나, 사진 속 글자를 읽어야 하는 작업에 특히 유용합니다. 예를 들어 영수증 정보 추출, 그래프 데이터 분석, 문서 내용 요약 등에 활용할 수 있습니다.
Q: FastVLM은 어떤 해상도까지 처리할 수 있나요?
A: FastVLM은 최대 2048×2048 해상도까지 처리할 수 있습니다. 간단한 2×2 그리드 방식을 사용해 고해상도 이미지를 효율적으로 분석합니다.
Q: FastVLM은 언제 실제 사용할 수 있나요?
A: 애플은 FastVLM을 오픈소스로 공개했습니다. 연구자와 개발자들은 GitHub를 통해 코드와 모델을 다운로드하여 사용할 수 있습니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문 명: FastVLM: Efficient Vision Encoding for Vision Language Models
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.