생성형 AI 기술이 급속도로 발전하면서 누구나 손쉽게 사실적인 이미지를 만들 수 있는 시대가 됐다. 어도비 파이어플라이(Adobe Firefly), 달리(DALL·E), 미드저니(Midjourney) 같은 도구들이 널리 보급되면서 기술적 전문성 없이도 고품질의 합성 이미지 제작이 가능해졌다. 하지만 이런 도구들이 창작 활동에 도움을 주는 반면, 가짜뉴스와 허위정보 제작에도 악용되고 있어 심각한 사회적 우려를 낳고 있다.
기존의 AI 이미지 탐지 기술은 주로 ‘진짜인지 가짜인지’를 구분하는 이진 분류에 집중해 왔다. 그러나 그리스 아리스토텔레스 대학교 연구팀이 발표한 연구에 따르면, AI가 생성한 이미지라고 해서 모두 악의적인 목적으로 만들어진 것은 아니다. 같은 AI 이미지라도 예술적 표현을 위해 만들어진 것인지, 유머나 풍자를 위한 것인지, 아니면 의도적으로 사람들을 속이려는 허위정보인지에 따라 그 의미와 위험성이 완전히 달라진다는 것이다.
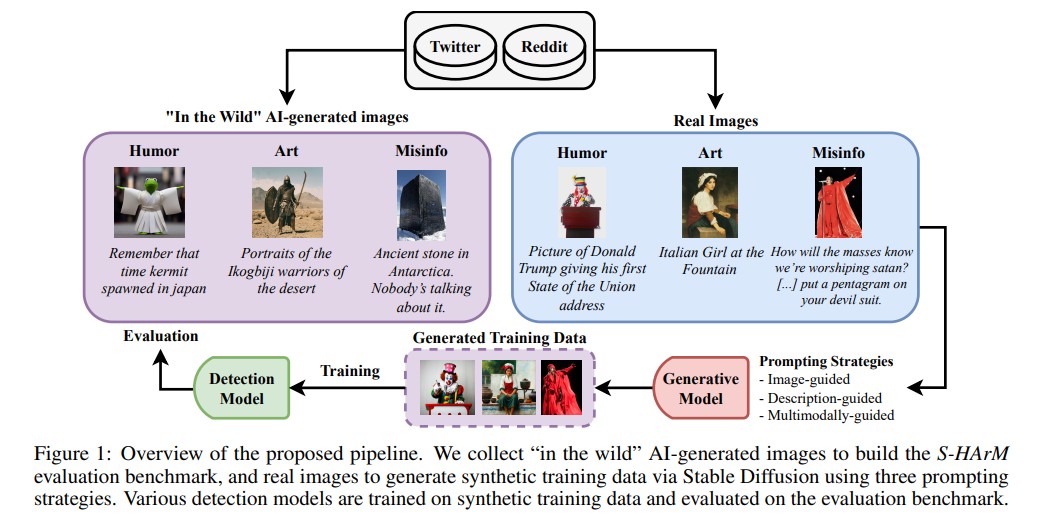
트위터와 레딧에서 수집한 9,576개 실제 사례로 구축한 S-HArM 데이터셋
연구팀은 AI 생성 이미지의 의도를 분석하기 위해 ‘S-HArM’이라는 새로운 데이터셋을 구축했다. 이는 ‘Synthetic-Humor, Art, Misinformation’의 줄임말로, AI가 만든 이미지를 유머·풍자, 예술, 허위정보의 세 가지 카테고리로 분류한다. 연구팀은 트위터(현 X)의 커뮤니티 노트와 레딧의 여러 서브레딧에서 총 9,576개의 실제 이미지-텍스트 쌍을 수집했다.
특히 허위정보 카테고리의 경우 트위터의 커뮤니티 노트 시스템을 활용했는데, 이는 사용자들이 직접 오해를 불러일으킬 수 있는 콘텐츠나 풍자성 콘텐츠를 표시하는 크라우드소싱 방식이다. 예술 카테고리는 AI 생성 예술 전용 트위터 커뮤니티와 미드저니, 스테이블 디퓨전 관련 레딧 커뮤니티에서 수집했다. 유머·풍자 카테고리는 AI 생성 밈과 농담을 다루는 여러 온라인 커뮤니티에서 가져왔다.
이미지만으론 의도 파악 불가능, 텍스트와 함께 봐야 진실 보인다
연구에서 가장 흥미로운 발견은 이미지만으로는 제작 의도를 알 수 없다는 점이다. 예를 들어 “남극의 고대 석조물. 아무도 이에 대해 말하지 않는다. 왜일까?”라는 텍스트와 함께 올라온 AI 생성 이미지가 있다고 하자. 이 이미지만 보면 단순한 예술 작품처럼 보일 수 있지만, 함께 올라온 텍스트를 보면 근거 없는 음모론을 뒷받침하려는 허위정보임을 알 수 있다.
연구팀은 실제 이미지를 바탕으로 스테이블 디퓨전(Stable Diffusion XL) 모델을 사용해 87,000개 이상의 합성 훈련 데이터를 생성했다. 이때 세 가지 생성 전략을 사용했는데, 이미지 기반 생성은 원본 이미지에 90% 비중을 두고 텍스트에 10% 비중을 둔 방식이고, 설명 기반 생성은 BLIP 모델로 이미지를 설명한 텍스트만을 사용하는 방식이다. 마지막으로 멀티모달 기반 생성은 이미지와 텍스트 설명에 각각 50%씩 동일한 비중을 두는 방식이다.
최신 AI 모델도 71.6% 정확도 한계, 의도 분석의 복잡성 드러나
연구팀은 다양한 머신러닝 모델을 테스트했다. 이미지 전용 모델, 텍스트 전용 모델부터 시작해 두 정보를 결합한 멀티모달 모델, 대조 학습 기법, 재구성 네트워크, 어텐션 메커니즘, 그리고 대규모 비전-언어 모델까지 광범위한 비교 연구를 진행했다.
실험 결과 이미지와 텍스트를 단순히 연결한 다층 퍼셉트론(MLP) 모델이 71.6%의 가장 높은 정확도를 보였다. 흥미롭게도 텍스트만 사용한 모델이 이미지만 사용한 모델보다 일관되게 높은 성능을 보였는데, 이는 AI가 생성한 이미지들이 시각적으로는 비슷해 보이지만 함께 올라온 텍스트에서 제작자의 의도가 더 명확하게 드러나기 때문이다.
합성 데이터로 훈련한 모델을 실제 소셜미디어 데이터로 테스트했을 때 성능 격차가 컸다. 합성 검증 데이터에서는 96.6%의 높은 정확도를 보였지만, 실제 ‘야생’ 데이터에서는 71.6%로 떨어졌다. 특히 트위터의 풍자·유머 콘텐츠에서는 13.56%라는 매우 낮은 정확도를 보였는데, 이는 해당 카테고리 데이터가 부족했기 때문으로 분석된다.

대형 언어모델도 제로샷으론 66.65% 그쳐, 전문 모델에 뒤처져
라마 3.2-11B(Llama-3.2-11B) 같은 대형 비전-언어 모델도 테스트했지만 결과는 아쉬웠다. 기본적인 직접 분류 방식으로는 50.09%에 그쳤고, 모델이 풍자와 허위정보 사이에서 헷갈릴 때 허위정보 쪽으로 편향되도록 유도한 ‘넛지’ 방식을 적용하면 62.28%로 향상됐다.
가장 좋은 결과는 2단계 프롬프팅 전략에서 나왔는데, 먼저 이미지를 자세히 분석한 후 분류하는 방식으로 66.65%의 정확도를 달성했다. 하지만 이는 여전히 전용 모델에 비해 낮은 수치로, 제로샷 설정의 한계를 보여준다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1: AI 생성 이미지의 의도 분석이 왜 중요한가요?
A1: 단순히 AI가 만든 이미지인지 아닌지를 구분하는 것만으로는 부족합니다. 같은 AI 이미지라도 예술 작품으로 만든 것과 사람들을 속이려는 허위정보로 만든 것은 완전히 다른 의미를 갖습니다. 의도 분석을 통해 콘텐츠 조정 시스템에서 우선적으로 검토해야 할 위험한 허위정보를 식별할 수 있어 더 효율적인 대응이 가능합니다.
Q2: 현재 기술로는 AI 이미지의 의도를 정확히 파악하기 어려운가요?
A2: 네, 아직 기술적 한계가 명확합니다. 최고 성능 모델도 실제 소셜미디어 데이터에서 71.6% 정확도에 그쳤습니다. 유머, 허위정보, 예술적 표현이라는 추상적 개념을 구분하는 것은 미묘한 맥락적 단서들을 이해해야 하는 복잡한 작업이어서 현재 AI 기술로는 한계가 있습니다.
Q3: 이미지만 보고도 의도를 알 수 있나요?
A3: 아니요, 이미지만으로는 의도 파악이 거의 불가능합니다. 연구 결과 텍스트 정보가 이미지보다 의도 분석에 더 중요한 단서를 제공하는 것으로 나타났습니다. 따라서 AI 이미지와 함께 올라온 캡션, 제목, 설명 등을 종합적으로 분석하는 멀티모달 접근법이 필요합니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문 명: “Humor, Art, or Misinformation?”: A Multimodal Dataset for Intent-Aware Synthetic Image Detection
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





