메타(Meta), 텍사스대학교 오스틴, UC버클리, 하버드대학교 등 공동 연구진이 인공지능 학습의 성능을 미리 예측할 수 있는 방법을 찾아냈다. 연구진은 40만 GPU 시간 이상을 투입한 대규모 실험을 통해, 컴퓨터 자원을 얼마나 투입하면 어느 정도 성능이 나올지 예측하는 수학 공식을 개발했다. 이를 바탕으로 10만 GPU 시간 규모까지 안정적으로 작동하는 새로운 학습 방법 ‘ScaleRL’도 함께 선보였다.
AI가 스스로 학습하는 과정, 이제 예측 가능해졌다
연구 논문에 따르면, 연구진은 AI의 ‘강화학습’ 성능을 예측하기 위해 S자 곡선 모양의 그래프를 제안했다. 강화학습이란 AI가 시행착오를 거치며 스스로 학습하는 방식이다. 이 그래프는 세 가지 중요한 값으로 구성된다. 첫째, A는 아무리 많은 컴퓨터 자원을 투입해도 도달할 수 있는 최고 성능을 뜻한다. 둘째, B는 컴퓨터 자원 대비 얼마나 효율적으로 학습하는지를 나타낸다. 셋째, Cmid는 목표 성능의 절반에 도달하는 데 필요한 컴퓨터 자원의 양이다.
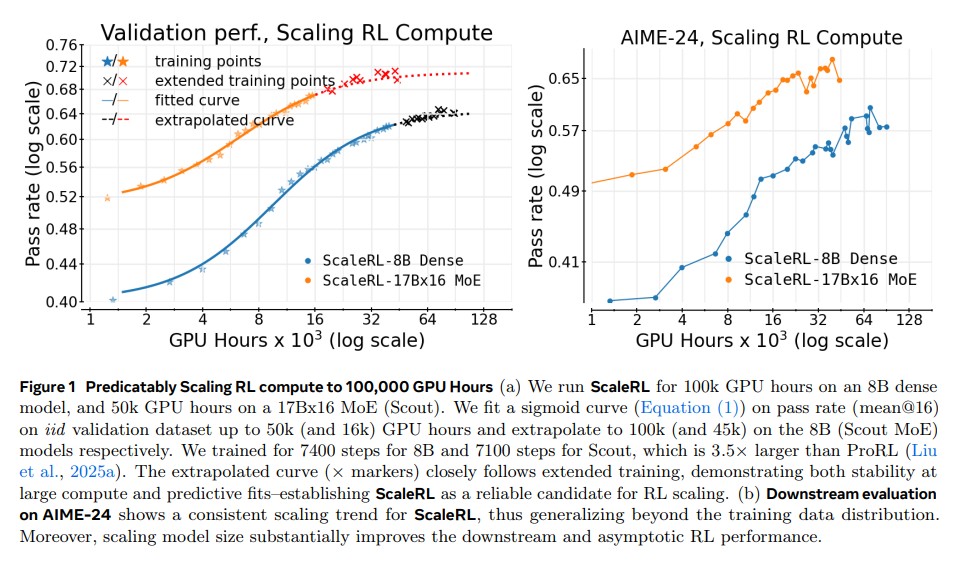
이 방법의 가장 큰 장점은 미래를 내다볼 수 있다는 점이다. 연구진은 80억 개 파라미터 모델과 17B×16 MoE 모델을 대상으로 실험했다. 80억 파라미터 모델의 경우, 학습 초반 5만 GPU 시간까지의 데이터만으로 10만 GPU 시간까지의 최종 성능을 예측했는데, 실제 결과가 예측과 거의 일치했다. 이는 연구자들이 비용과 시간이 많이 드는 전체 실험을 끝까지 하지 않아도, 어떤 방법이 효과적일지 미리 알 수 있다는 의미다.
같은 노력, 다른 결과: 학습 방법마다 성능 한계가 다르다
연구에서 밝혀진 중요한 사실은 AI 학습 방법마다 도달할 수 있는 최고 성능이 다르다는 점이다. 연구진이 개발한 ScaleRL은 최종 점수 0.61을 기록했다. 반면 중국 딥시크(DeepSeek)의 방식은 0.490, 중국 큐웬(Qwen)의 방식은 0.515에 그쳤다. 이는 단순히 속도 차이가 아니라, 근본적으로 도달 가능한 성능의 천장이 다르다는 뜻이다.
어떤 요소가 이런 차이를 만들까? 연구진은 몇 가지 기술적 선택이 최고 성능을 바꿀 수 있다는 것을 발견했다. 특히 AI 모델이 계산할 때 더 정밀한 방식을 사용하자 최종 성능이 0.52에서 0.61로 크게 향상됐다. 이는 학습 과정에서 발생하는 미세한 오차를 줄였기 때문이다.
처음엔 좋아 보여도 끝은 다를 수 있다… 초기 성능의 함정
“작은 실험에서 좋았던 방법이 큰 실험에서도 최선은 아니다”라는 원칙이 AI 학습에서도 적용된다는 사실이 확인됐다. 적은 컴퓨터 자원으로 실험할 때 더 나아 보이는 방법이, 자원을 크게 늘렸을 때 오히려 더 나쁜 결과를 낼 수 있다. 따라서 초기 성능만 보고 어떤 방법이 좋을지 판단해선 안 된다.
연구진의 예측 공식은 이 문제를 해결한다. 학습 초반 데이터에서 성능 한계값 A와 효율성 지표 B를 계산하면, 전체 실험을 끝내지 않아도 어떤 방법이 최종적으로 더 나을지 알 수 있다. 예를 들어, 어떤 방법은 초반에 빠르게 좋아지지만 낮은 한계에 멈추고, 다른 방법은 천천히 개선되지만 결국 더 높은 성능에 도달한다.
ScaleRL: 대규모로 키워도 안정적인 새로운 학습법
연구진은 가장 효과적인 설정들을 모아 ScaleRL이라는 학습 방법을 만들었다. ScaleRL의 가장 큰 장점은 조건이 바뀌어도 예측대로 작동한다는 점이다. 한 번에 학습하는 데이터 양을 2.5배 늘리거나, AI가 생성하는 답변 길이를 32배 확장하거나, 수학과 코딩 문제를 동시에 풀게 하거나, 더 큰 모델을 사용해도 모두 예측대로 결과가 나왔다.
80억 파라미터 모델의 10만 GPU 시간 실험에서, 절반만 학습한 시점의 데이터로 최종 성능을 예측했는데 실제 결과와 거의 일치했다. 이는 ScaleRL이 대규모 학습에서도 믿고 쓸 수 있는 방법임을 증명한다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 강화학습 예측 공식이란 무엇이고 왜 필요한가요?
A: 강화학습 예측 공식은 컴퓨터 자원을 얼마나 쓰면 AI 성능이 어느 정도 나올지 미리 계산하는 수학 공식입니다. 이를 쓰면 연구자들이 비싼 실험을 끝까지 하지 않아도 초반 데이터만으로 최종 결과를 예측할 수 있어, 시간과 비용을 크게 절약할 수 있습니다.
Q2. ScaleRL이 기존 방법보다 좋은 이유는 무엇인가요?
A: ScaleRL은 도달 가능한 최고 성능(0.61점)과 학습 효율성(1.97) 모두에서 우수합니다. 딥시크나 큐웬 같은 기존 방법보다 최종 성능이 높고, 10만 GPU 시간 규모까지 안정적으로 작동하는 것이 검증됐습니다.
Q3. 이 연구가 실제 AI 개발에 어떤 도움이 되나요?
A: 이 연구는 AI의 추론 능력을 높이는 강화학습을 더 예측 가능하고 저렴하게 만듭니다. 연구자들은 이제 작은 실험으로 큰 실험의 성공 가능성을 미리 평가할 수 있어, 대학과 기업 모두에서 AI 발전 속도가 빨라질 것으로 예상됩니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: The Art of Scaling Reinforcement Learning Compute for LLMs
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.