
스탠퍼드 대학 연구팀이 이미 만들어진 AI를 나중에라도 안전하게 만들 수 있는 새로운 방법을 개발했다. 이 기술의 핵심은 AI가 위험한 상황을 스스로 판단해 사람에게 도움을 요청하도록 학습시키는 것이다. 동시에 안전한 상황에서는 혼자서도 일을 처리할 수 있게 균형을 맞춘다.
AI와 사람이 동시에 선택하는 ‘감독 게임’
연구팀은 ‘Oversight Game(감독 게임)’이라는 시스템을 만들었다. 이 시스템에서 AI와 사람은 매 순간 동시에 선택을 한다. AI는 “혼자 할래(play)” 아니면 “도와줘(ask)” 중에서 고르고, 사람은 “믿을게(trust)” 아니면 “내가 확인할게(oversee)” 중에서 고른다.
이 게임의 특별한 점은 수학적으로 증명된 안전 보장이 있다는 것이다. 연구팀은 이 게임을 ‘마르코프 포텐셜 게임’이라는 특수한 게임 구조로 설계했다. 쉽게 말하면, AI와 사람이 공유하는 점수판이 있어서 둘 다 이 점수를 높이려고 노력한다는 뜻이다.
연구팀이 증명한 ‘로컬 정렬 정리’는 다음을 보장한다. AI가 특정 상황에서 ‘도와줘’에서 ‘혼자 할래’로 변경해 자기 점수를 올릴 때, 논문에서 제시한 조건이 충족된다면 사람의 점수도 낮아지지 않는다는 것이 수학적으로 증명됨. 다만, 이러한 안전은 일정한 구조적 가정하에서만 보장된다.
복잡한 AI 원리 몰라도 작동하는 시스템
실제로 AI를 제어할 때 큰 문제가 있다. AI는 이미 학습이 끝난 상태이고, 어떤 원리로 판단하는지 우리가 이해할 수 없을 만큼 복잡하다. 연구팀은 이런 복잡한 원리를 몰라도 작동하는 제어 장치를 개발했다.
이 시스템은 사람이 알 수 있는 두 가지만 필요하다. 첫째, 각 상황에서 어떤 행동이 위험한지 판별할 수 있어야 한다. 예를 들어 “중요한 파일을 삭제하면 안 돼” 같은 간단한 규칙이다. 둘째, AI가 질문할 때와 사람이 확인할 때 드는 노력의 크기를 알아야 한다.
연구팀이 설계한 점수 계산 방식은 이렇다. 위험한 행동을 하면 큰 감점을 받고, AI가 질문하면 작은 감점, 사람이 확인하면 또 다른 작은 감점을 받는다. AI와 사람 모두 이 동일한 점수를 높이려고 노력하기 때문에, 자연스럽게 “안전하면서도 질문을 최소화하는” 방향으로 협력하게 된다.
연구팀은 이 점수 계산 방식만으로도 최적의 상태에서는 반드시 안전하게 작동하고, 불필요한 감독을 최소화한다는 것을 수학적으로 증명했다. 또한 사람이 개입할 때 성능 손실이 있더라도, 전체적으로 얼마나 성능이 떨어지는지 정확한 한곗값도 제시했다.
미로 실험에서 실제로 안전하게 학습 성공
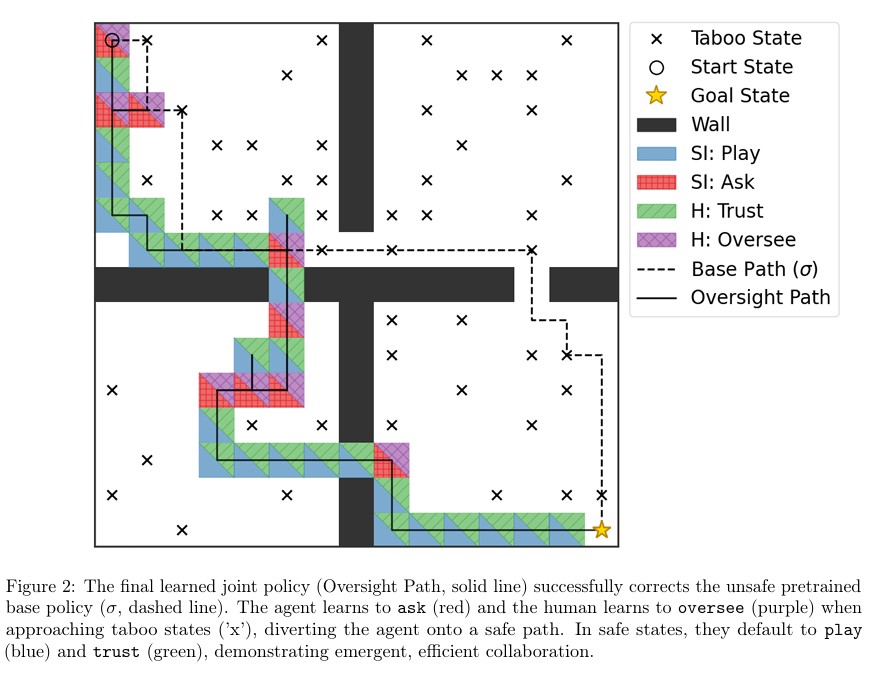
연구팀은 15×15 크기의 방 네 개가 있는 미로 게임에서 이 기술을 테스트했다. 먼저 AI를 학습시켜서 출발점에서 목표점까지 가는 효율적인 방법을 익히게 했다. 그런데 학습이 끝난 후에 미로의 25%를 “가면 안 되는 위험 지역”으로 새로 지정했다. 이미 학습이 끝난 AI는 이 새로운 규칙을 모르기 때문에 위험 지역을 지나가는 문제가 생겼다.
여기서 중요한 점이 있다. 사람의 역할을 아주 단순하게 설정했다는 것이다. AI가 도움을 요청하고 사람이 확인하기로 하면, 사람은 그냥 “아무 안전한 방향”으로 무작위로 보낸다. 최적의 길을 알려주는 게 아니다. 이는 사람이 전문가가 아닌 상황, 즉 “AI가 뭘 해야 최선인지는 모르지만 위험한 건 알 수 있는” 상황을 가정한 것이다.
학습 과정 초기에는 AI와 사람이 모두 조심스럽게 행동하며 질문·확인을 자주 하다가, 대략 3,500회 학습 이후부터 안전 구역에서 독립적으로 행동하는 비율이 크게 증가하여 효율적이고 안전한 경로로 수렴함을 관찰했다. AI와 사람 모두 어느 지역이 안전한지 학습했고, 안전한 곳에서는 독립적으로 일하고 위험한 곳에 가까워질 때만 선택적으로 도움을 요청하는 효율적인 방법을 찾아냈다.
최종 결과를 보면 원래 AI의 경로(점선)는 위험 지역을 여러 번 지나갔다. 하지만 새로 학습한 ‘감독 경로'(실선)는 완전히 안전하다. 안전한 구역에서는 AI가 혼자 판단하고(파란색) 사람도 믿고(녹색), 위험 구역에 가까워지면 AI가 도움을 요청하고(빨간색) 사람이 확인해서(보라색) 새로운 안전한 길로 우회시킨다. 둘이 협력해서 위험을 피하는 방법을 스스로 찾아낸 것이다.
전문가 있으면 좋지만, 없어도 어느 정도 작동
연구팀은 이 기술이 두 가지 상황에서 쓰일 수 있다고 설명했다. 첫째는 ‘능력 격차 상황’이다. 예를 들어 프로그래밍을 잘 모르는 초보자가 매우 뛰어난 AI 코딩 도우미를 쓰는 경우다. 사람은 올바른 코드를 짤 줄 모르지만 “중요한 파일 지우면 안 돼” 같은 간단한 안전 규칙은 확인할 수 있다. 미로 실험이 바로 이 상황을 재현한 것이다.
둘째는 ‘전문가 참여 상황’이다. 전문 의사가 AI에게 간단한 행정 업무를 맡기는 경우처럼, 사람이 전문가인 상황이다. 이 경우 전문가가 모든 행동을 제대로 확인할 수 있기 때문에 이 기술을 적용하기가 더 쉽다.
하지만 한계도 분명하다. 가장 큰 문제는 ‘샌드박스 문제’다. AI와 사람이 함께 학습하려면 안전한 연습 환경이 필요한데, 능력 격차 상황에서는 사람이 제공하는 교정 신호가 제한적이다. 미로 실험의 “무작위 안전 방향”처럼 말이다. 실제 코딩 상황이라면 “파일 지우지 말고 그냥 아무것도 하지 마”가 될 텐데, 이러면 AI가 질문하면 할수록 일이 멈춰버린다. 결국 AI가 질문을 꺼리게 될 수 있다. 앞으로 이 문제를 해결할 더 똑똑한 방법을 연구해야 한다.
연구팀은 다른 한계들도 언급했다. 실제로 이 기술을 적용하려면 점수 계산 방식을 신중하게 설계해야 하고, 무엇보다 매우 뛰어나거나 초지능일 수도 있는 AI에게 이 제어 장치를 강제로 적용할 수 있어야 한다는 기술적 과제가 있다. 또한 지금은 간단한 미로 게임에서만 테스트했기 때문에, 더 복잡하고 실제적인 환경에서도 작동하는지 확인하는 것이 중요한 다음 연구 과제다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 기존 ‘Off-Switch Game’과 뭐가 다른가요?
A: Off-Switch Game은 AI가 전원을 끄게 놔둘지 말지를 한 번만 선택하는 단순한 게임이었습니다. 이번 연구는 이를 두 가지로 확장했습니다. 첫째, 상황이 계속 바뀌는 동적인 게임으로 만들었습니다. 둘째, AI가 사전에 가진 불확실성이 아니라 경험을 통해 배우도록 했습니다. 결과적으로 AI는 사람의 감독 방식을 보면서 언제 어떻게 도움을 요청할지 스스로 배웁니다.
Q2. 왜 AI와 사람이 같은 점수를 공유하나요?
A: 같은 점수를 공유하면 AI와 사람이 자연스럽게 같은 목표를 향해 협력하게 됩니다. 이렇게 하면 AI가 더 독립적으로 일하려는 선택이 자기에게 좋으면서도 사람에게 해롭지 않다는 것을 수학적으로 보장할 수 있습니다. 또한 독립적인 학습 알고리즘을 써도 둘의 전략이 안정적인 균형점으로 수렴한다는 것이 보장됩니다.
Q3. 실제로 이 기술을 쓰려면 뭐가 필요한가요?
A: 두 가지가 필요합니다. 첫째, 어떤 행동이 위험한지 판별할 수 있는 규칙이 있어야 합니다. 둘째, 질문하고 확인하는 데 드는 노력의 크기를 수치로 표현할 수 있어야 합니다. 또한 AI와 사람이 안전하게 연습할 수 있는 환경도 필요합니다. 가장 큰 과제는 매우 뛰어난 AI에게 이 제어 장치를 강제로 적용할 기술적 방법을 찾는 것입니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: The Oversight Game: Learning to Cooperatively Balance an AI Agent’s Safety and Autonomy
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





