메릴랜드 대학교와 UMass Amherst 연구진이 26개 언어로 대형 언어 모델의 긴 맥락 처리 능력을 평가한 원룰러(OneRuler) 벤치마크를 공개했다. 해당 연구 논문에 따르면, 한국어는 26개 언어 중 22위로 하위권에 머물렀으며, 맥락 길이가 늘어날수록 성능 저하가 더욱 심각해지는 것으로 나타났다. 폴란드어가 1위를 차지한 가운데, 영어조차 6위에 그쳤다는 점에서 언어별 성능 격차가 예상을 뛰어넘는다.
한국어 성능 22위… 폴란드어는 1위
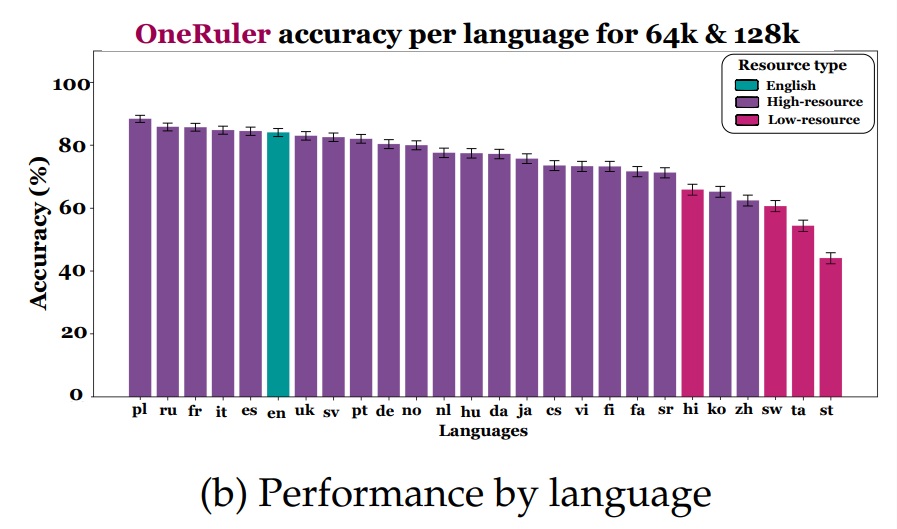
연구진이 6만 4천~12만 8천 토큰 길이의 긴 맥락 과제를 평가한 결과, 한국어는 26개 언어 중 22위를 기록했다. 원룰러 벤치마크의 니들 인 헤이스택(NIAH) 과제 평가에서 한국어는 중국어, 타밀어, 스와힐리어, 세소토어와 함께 하위권에 속했다. 흥미롭게도 폴란드어가 평균 정확도 88%로 1위를 차지했고, 영어는 83.9%로 6위에 머물렀다. 중국어는 62.1%로 하위 4위를 기록했다. 대부분의 AI 모델이 영어와 중국어 데이터로 주로 학습된다는 점을 고려하면 이는 매우 의외의 결과다. 상위 10개 언어는 대부분 슬라브어, 로망스어, 게르만어 계통으로 위키피디아 문서 수가 많고 라틴 문자를 사용하는 언어들이었다.
맥락 8K→128K로 늘면 언어 격차 3배 확대
맥락 길이가 8천 토큰일 때 상위 5개 언어와 하위 5개 언어 간 정확도 차이는 11%에 불과했다. 그러나 맥락이 12만 8천 토큰으로 늘어나자 이 격차는 34%로 세 배 이상 확대됐다. 한국어는 위키피디아 문서 수 기준으로 약 70만 개를 보유해 공식적으로는 저자원 언어로 분류되지 않지만, 실제 평가에서는 하위권에 머물렀다. 논문에서 저자원 언어로 정의한 힌디어, 세소토어, 스와힐리어, 타밀어는 모두 하위 6위 안에 포함됐으며, 짧은 맥락에서도 어려움을 겪었고 긴 맥락에서는 성능 저하가 더욱 두드러졌다. 연구진은 이러한 현상이 긴 맥락 확장 학습 데이터에서 비영어권 언어가 부족하기 때문으로 추정한다. 제미나이 1.5 플래시(Gemini 1.5 Flash)와 큐엔 2.5 72B(Qwen 2.5 72B)만이 12만 8천 토큰에서도 비교적 우수한 성능을 보였다.
한국어 지시문 사용하면 성능 20% 하락
연구진은 지시문과 맥락의 언어가 다른 교차 언어 시나리오를 영어, 폴란드어, 한국어 3개 언어로 테스트했다. 영어 맥락에 한국어 지시문을 사용하면 6만 4천 토큰 기준 평균 정확도가 91%에서 71%로 20% 하락했다. 반대로 한국어 맥락에 영어 지시문을 사용하면 12만 8천 토큰 기준 정확도가 61%에서 77%로 향상됐다. 폴란드어 지시문을 사용했을 때도 유사하게 향상됐다. 이는 지시 언어의 선택이 전체 성능에 최대 20%의 차이를 만들 수 있음을 보여준다. 현재로서는 한국어 지시문보다 영어 지시문을 사용하는 것이 더 나은 결과를 제공할 수 있다.
‘답이 없다’ 선택지만 추가해도 o3-미니 성능 32% 급락
연구진은 기존 니들 인 헤이스택(NIAH) 과제에 ‘답이 존재하지 않을 수 있음’이라는 선택지를 추가했다. 이 간단한 변경만으로 o3-미니-하이(o3-mini-high) 모델의 경우 영어 기준 12만 8천 토큰에서 정확도가 32% 하락했다. 모든 모델이 답이 실제로 존재함에도 불구하고 ‘없음’으로 잘못 응답하는 경우가 빈번했다. 특히 o3-미니-하이는 다른 모델들에 비해 ‘없음’ 오답을 훨씬 더 많이 생성했다. 제미나이 1.5 플래시도 일부 고자원 언어에서 상당한 수의 ‘없음’ 오류를 보였다. 중국어에 특화된 큐엔(Qwen) 모델도 중국어 단일 NIAH 과제에서 다수의 ‘없음’ 오류를 생성했다.
단어 빈도 집계는 모든 모델이 실패
단어 빈도 추출(Common Word Extraction, CWE) 과제에서는 모든 모델이 고전했다. 가장 빈번한 단어 10개를 찾는 쉬운 버전에서 영어 평균 정확도는 31.5%에 불과했다. 빈도 차이를 줄인 어려운 버전에서는 모든 모델이 1% 미만의 정확도를 기록했다. 라마 3.3 70B(Llama 3.3 70B), 큐엔 2.5 72B, 제미나이 1.5 플래시 세 모델만이 8천 토큰에서 80% 이상의 성능을 달성했지만, 맥락 길이가 늘어나면서 급격히 하락했다. o3-미니-하이와 딥시크-R1(Deepseek-R1)은 이 과제에서 설정된 최대 출력 토큰 한도를 초과하는 경우가 빈번했으며, 틀린 답변을 생성할 때 정답보다 훨씬 더 많은 추론 토큰을 사용했다.
다국어 AI의 한계
이번 연구는 현재 대형 언어 모델들이 다국어, 특히 비영어권 언어의 긴 맥락 처리에서 상당한 한계를 가지고 있음을 보여준다. 한국어를 포함한 많은 언어가 짧은 맥락에서는 비교적 괜찮은 성능을 보이지만, 실제 업무에서 자주 필요한 긴 문서 처리에서는 크게 뒤처진다. 연구진은 원룰러 벤치마크 공개를 통해 다국어 및 교차 언어 긴 맥락 학습 파이프라인 개선 연구가 활성화되기를 기대한다고 밝혔다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. 한국어가 이렇게 낮은 성능을 보이는 이유는 무엇인가요?
A. 연구진은 긴 맥락 확장 학습 데이터의 부족을 주요 원인으로 지목했습니다. 대부분의 AI 모델은 영어와 중국어를 중심으로 학습되며, 한국어는 위키피디아 문서 수가 약 70만 개로 중간 수준이지만 긴 맥락 학습에는 충분한 데이터가 제공되지 않은 것으로 보입니다. 긴 맥락 처리 능력이 언어 간에 쉽게 전이되지 않는다는 점도 영향을 미쳤습니다.
Q. 니들 인 헤이스택(NIAH) 과제는 무엇인가요?
A. 긴 문서 속에 특정 정보(‘바늘’)를 숨기고 AI 모델이 이를 찾아낼 수 있는지 테스트하는 과제입니다. 실제 문서 요약이나 질의응답 과제를 평가하기 어렵고 비용이 많이 들기 때문에, 긴 맥락 처리 능력을 측정하는 대용 지표로 널리 사용됩니다. 한국어 계약서에서 특정 조항을 찾거나, 긴 회의록에서 결정 사항을 추출하는 실무 작업과 유사합니다.
Q. 왜 영어보다 폴란드어가 더 높은 성능을 보였나요?
A. 명확한 이유는 밝혀지지 않았지만, 위키피디아 문서 수가 많고 라틴 문자를 사용하는 슬라브어, 로망스어, 게르만어 계통 언어들이 상위권을 차지했습니다. 단순한 데이터양보다는 언어 계통, 사용 문자, 그리고 긴 맥락 학습 파이프라인에서의 언어별 처리 방식이 복합적으로 영향을 미친 것으로 추정됩니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: One ruler to measure them all: Benchmarking multilingual long-context language models
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.