
문서를 읽고 질문에 답하는 AI가 크게 발전했지만, 정작 “이 질문은 답할 수 없다”는 사실을 알아채는 능력은 형편없는 것으로 드러났다. 이탈리아 토리노 공대 연구팀이 GPT-4를 포함한 최신 AI 모델 12종을 테스트한 결과, 문법도 맞고 내용도 그럴듯해 보이지만 실제로는 답이 없는 질문 앞에서 대부분 헷갈려 했다. 가장 성적이 좋은 AI도 정확도가 60%에 불과했고, 최악의 경우 7%에 그쳤다. 이는 AI가 틀린 정보를 마치 맞는 것처럼 자신 있게 말할 위험이 크다는 뜻이다.
최고 성적 60점, 모델 크기보다 학습 방식이 중요
연구팀은 Qwen, GPT-4.1-mini, Gemma, LLaMA 등 12종의 AI를 두 종류의 문서 데이터로 시험했다. ‘문서 정확도’라는 기준으로 보면 점수가 7%에서 60% 사이였다. 이는 100개 질문 중 7~60개만 제대로 “답할 수 없다”고 판단했다는 의미다. 가장 잘한 건 중국 알리바바가 만든 Qwen 2.5 VL 72B 모델로, DUDE라는 테스트에서 59.9%, MPDocVQA 테스트에서 58.1%를 받았다. 흥미로운 점은 같은 회사의 작은 모델(7B)도 각각 46%, 49%를 받으며 선전했다는 것이다. 연구팀은 이를 통해 AI 크기를 키우는 것보다 어떻게 학습시키느냐가 더 중요하다고 분석했다.
‘페이지 정확도’로 보면 점수가 더 높았다. Qwen 7B는 83.5%와 88.1%를 기록했다. 하지만 이건 페이지 하나씩 볼 때 얘기고, 문서 전체를 일관되게 판단하는 능력은 훨씬 떨어졌다. 특히 8페이지가 넘는 긴 문서에서는 모든 AI의 성적이 뚝 떨어졌다.
“그림이에요, 표에요?” 질문에 AI 혼란…구조 정보 바꾸면 속아 넘어가
연구팀은 질문 속 단어를 다섯 종류로 나눠 각각 바꿔치기했다. 숫자, 시간, 기타 정보, 위치, 문서 구조가 그것이다. AI들은 위치나 숫자를 바꾼 질문은 비교적 잘 알아챘다.
하지만 문서 구조 관련 단어를 바꾸면 쉽게 속았다. 예를 들어 원래 질문이 “그림에서 바다 수위 전망은?”이었는데, 이걸 “표에서 바다 수위 전망은?”으로 바꾸면 AI가 헷갈렸다. 문서에 바다 수위 그림은 있지만 표는 없는 상황에서도 AI는 “답이 없다”고 제대로 판단하지 못했다.
문서 요소별로 보면, 머리글·꼬리글·각주 같은 부가 정보에 대한 질문은 AI가 잘 처리했다. Qwen 72B는 DUDE 테스트에서 67.5%, MPDocVQA에서 83.3%를 받았다. 반면 표에 대한 질문에서는 성적이 떨어졌고, 특히 제목 관련 질문은 더 어려워했다.
같은 페이지 안에서 단어를 바꾼 경우가 다른 페이지의 단어로 바꾼 것보다 더 어려웠다. Qwen 7B의 경우 같은 페이지 변조는 75.3%, 다른 페이지 변조는 87.3%의 정확도를 보였다. 비슷한 정보가 가까이 있으면 AI가 더 헷갈린다는 뜻이다. 또 페이지 수가 8장을 넘어가면 모든 AI의 성적이 떨어졌다.
“답 모를 수도 있다”고 미리 알려주니 성적 껑충
연구팀은 AI에게 힌트를 줬을 때 어떻게 달라지는지 실험했다. 프롬프트(AI에게 주는 지시문)에 “이 질문은 답이 없을 수도 있습니다”라고 미리 알려주거나, 문서의 텍스트를 글자로 풀어서 함께 제공하는 방식이다. 결과는 놀라웠다. 힌트만 줘도 성적이 올랐고, 텍스트 정보를 더하면 더욱 좋아졌다. 두 가지를 다 쓰면 가장 효과가 컸다. DUDE 테스트에서 Qwen 72B는 기본 상태보다 이 두 방법을 합쳤을 때 성적이 크게 올랐다. 텍스트 정보는 특히 글이 많은 문서에서 효과적이었지만, 그림이나 표가 많은 문서에서는 도움이 덜했다.
재미있는 건 한 번에 보는 페이지 수를 늘리면 오히려 성적이 떨어진다는 점이다. 1페이지씩 볼 때보다 3페이지를 한꺼번에 보면 대부분 AI의 정확도가 낮아졌다. 정보가 많으면 오히려 헷갈린다는 뜻이다.
연구팀이 만든 ‘가짜 질문’ 생성 시스템
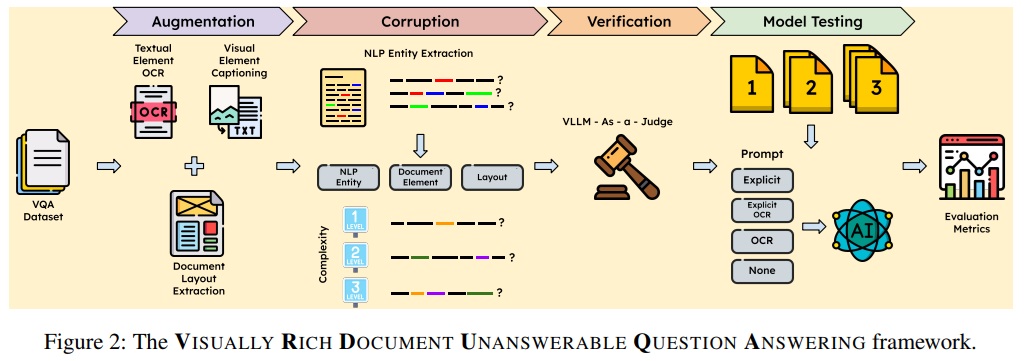
VRD-UQA라는 이름의 이 평가 시스템은 진짜 같은 가짜 질문을 자동으로 만든다. 과정은 4단계다. 먼저 문서를 분석하고, 질문 속 단어를 교묘하게 바꾸고, 정말 답이 없는지 확인하고, 마지막으로 AI를 평가한다.
첫 단계에서는 DocLayout-YOLO라는 도구로 문서 구조를 분석하고, Qwen AI로 그림 설명을 만들고, GOT-OCR 2로 글자를 읽는다. 두 번째 단계에서는 GliNER라는 도구가 질문에서 핵심 단어를 찾아내고, 같은 종류의 다른 단어로 바꾼 뒤, Qwen AI가 자연스러운 문장으로 다듬는다. 세 번째 단계에서는 구글의 Gemini 2.5 Flash AI가 판사처럼 “이 질문이 정말 답이 없나?”를 검증한다.
연구팀은 DUDE와 MPDocVQA라는 두 데이터셋에서 각각 300개 질문을 뽑아 총 2,176개의 가짜 질문 후보를 만들었다. 검증 과정을 거쳐 593개의 진짜 답 없는 질문을 확정했다. 이 중 단순한 것(1개 단어 변조)이 318개, 중간 난이도(2개 단어 변조)가 201개, 어려운 것(3개 단어 변조)이 74개였다. 사람 전문가가 검토한 결과 96.97%가 정확하게 답 없는 질문이었다.
AI에게도 “모른다”고 말할 용기가 필요해
이번 연구는 요즘 AI가 답을 잘 찾는 건 뛰어나지만, 정작 답이 없는 상황을 알아채는 건 서툴다는 점을 보여준다. 실제 상황에서 사람들은 오타를 치거나, 잘못 기억하거나, 문서 내용을 착각해서 답 없는 질문을 자주 한다. 이럴 때 AI가 틀린 답을 자신있게 말하는 것보다는 “모르겠습니다”라고 솔직하게 말하는 게 훨씬 안전하다.
연구 결과를 보면 AI를 크게 만드는 것만으로는 이 문제를 해결할 수 없다. 대신 학습 방법과 설계 방식이 더 중요하다. 특히 문서 구조를 이해하는 능력과 공간 정보를 처리하는 능력을 키워야 한다. 실무에서는 AI에게 질문할 때 “답이 없을 수도 있다”고 미리 말해주고, 문서 텍스트를 함께 제공하면 성능이 올라간다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q: VRD-UQA가 기존 AI 평가와 다른 점은 뭔가요?
A: 기존 평가는 AI가 질문에 정확히 답하는지만 봤습니다. VRD-UQA는 “이 질문은 답이 없다”는 걸 AI가 알아채는지 평가합니다. 문법도 맞고 내용도 그럴듯하지만 실제로는 답이 없는 질문을 만들어서, AI가 속는지 안 속는지 테스트하는 겁니다.
Q: AI 정확도를 높이려면 어떻게 해야 하나요?
A: 질문할 때 “답이 없을 수도 있어”라고 미리 알려주고, 문서 내용을 글자로 풀어서 함께 제공하면 좋습니다. 연구 결과 이 두 방법을 함께 쓰면 AI 성적이 가장 많이 올랐습니다. 또 한 번에 너무 많은 페이지를 주지 말고 적당히 나눠서 주는 것도 도움이 됩니다.
Q: AI가 가장 어려워하는 질문 유형은 뭔가요?
A: “그림”을 “표”로 바꾸는 등 문서 구조 관련 단어를 바꾼 질문이 가장 어렵습니다. 또 같은 페이지 안에서 단어를 바꾼 경우, 표에 대한 질문, 그리고 8페이지 넘는 긴 문서의 질문을 특히 어려워합니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: Benchmarking Visual LLMs Resilience to Unanswerable Questions on Visually Rich Documents
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





