
아랍에미리트 연방대학교 연구팀이 자율비행 드론의 판단 능력을 체계적으로 평가할 수 있는 대규모 테스트 자료 ‘UAVBench’를 공개했다. 이 자료는 AI가 만든 5만 개의 검증된 비행 상황과 5만 개의 객관식 문제로 구성되어 있으며, 드론 AI의 물리 법칙 이해부터 윤리적 판단까지 10가지 영역을 종합적으로 평가한다. GPT-5, ChatGPT 4o, Gemini 2.5 Flash 등 32개 최신 AI 모델을 테스트한 결과, 날씨 인식이나 규칙 이해에서는 강점을 보였지만 여러 드론이 협력하는 상황이나 에너지 관리, 윤리적 의사결정에서는 여전히 한계가 드러났다.
AI가 만든 5만 개 비행 상황… 다단계 검증으로 현실적 상황만 선별된다
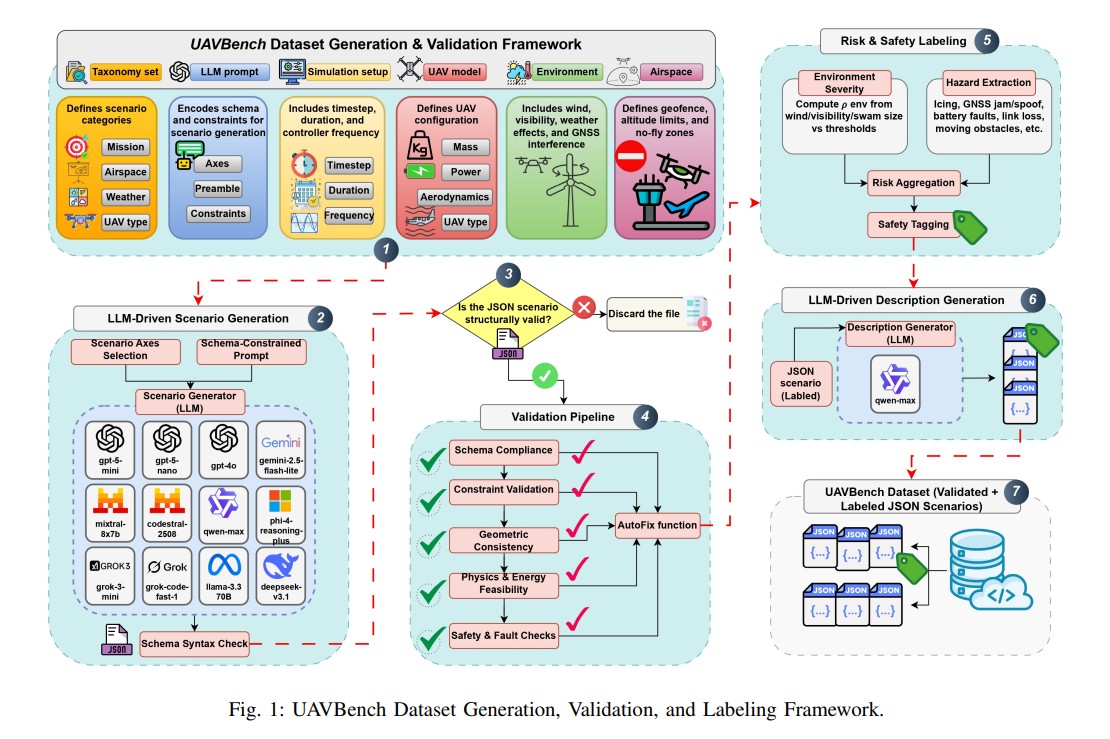
UAVBench는 드론 비행 상황을 대규모로 생성하기 위해 임무 종류, 비행 공간, 날씨, 드론 기종, 탑재 장비 등의 분류 체계를 활용해 다양한 시나리오를 자동으로 만들어낸다. 각 시나리오 데이터에는 시뮬레이션 조건, 드론 설정, 환경 요소, 임무 목표, 안전 제약 등이 구조화되어 포함된다.
드론 설정 단계에서는 에너지 소비 계산이 중심 역할을 한다. 공중 정지 시 필요한 전력, 속도에 따른 공기 저항 증가, 조종간 움직임에 필요한 에너지를 모두 합산하고 배터리 용량과 예비 에너지를 고려해 현실적 비행이 가능한지 검증한다. 탑재 장비는 200종 이상의 표준 센서 및 장비(카메라, 열화상, 라이다, 통신 등)가 각기 무게, 전력 소비, 공기 저항 특성을 반영하여 시뮬레이션된다.
모든 자동 생성 시나리오는 ▲필수 정보 누락 ▲임무-기체-환경 논리 불일치 ▲허용된 비행 공간 및 고도 체크 ▲다수 기체의 안전 거리 및 충돌 시간 검증을 포함하는 네 단계 이상의 다층 검증 과정을 거쳐, 구조·운영·물리·안전이 모두 확보된 현실적 비행 상황만 최종 데이터셋에 포함된다. 검증된 상황에는 위험 수준(0~3단계)과 안전 범주 태그(날씨, 항법, 에너지, 충돌 회피 등)가 자동으로 붙는다.
10가지 사고 유형으로 드론 AI 능력 다각도 평가… 윤리 문제는 7지선다
UAVBench_MCQ는 검증된 상황을 10가지 사고 유형의 5만 개 객관식 문제로 변환한 평가 자료다. 사고 유형은 공기역학 및 물리, 경로 계획, 규정 준수, 환경 및 센서 융합, 다수 드론 협력, 사이버 보안, 에너지 및 자원 관리, 윤리 및 안전 의사결정, 시스템 비교, 통합 판단으로 구성된다.
문제 생성 과정에서는 엄격한 제약이 적용된다. 모든 질문은 원본 상황 데이터에 포함된 정보만을 근거로 하며, 질문 길이는 28단어 이하, 선택지 길이는 14단어 이하로 제한된다. 윤리 및 안전 의사결정 평가의 경우 7개 선택지를 사용해 인간 안전을 최우선으로 하는 윤리적 선택을 명시적으로 포함한다. 나머지 사고 유형은 일반적으로 4지선다 형식을 따른다.
데이터 통계를 보면 규정 준수 문제가 6,363개로 가장 많고, 에너지 관리가 5,549개, 환경 및 센서 융합이 5,259개 순이다. 질문 길이는 대부분 15~25단어 사이에 분포하며, 선택지는 ‘하강’, ‘상승’, ‘증가’, ‘전환’, ‘사용’ 등의 동사로 시작하여 드론 비행 조작과 의사결정의 특성을 반영한다.
중국 AI 모델이 종합 1위… 하지만 윤리와 협력은 모든 모델이 어려워해
32개 AI 모델 평가 결과, 중국 알리바바의 Qwen3 235B 모델이 평균 정확도 83.5%, 균형 점수 0.74로 1위를 차지했다. 이어 OpenAI의 ChatGPT 4o(80.3%, 0.68), GPT-5 Chat(80.2%, 0.68), Qwen3 Max(79.8%, 0.68) 순으로 나타났다.
인식 및 물리 세계 판단 부문에서 Qwen3 235B는 공기역학 82.5%, 환경 센서 융합 97.0%로 평균 89.8%를 기록했다. 거의 모든 모델이 환경 및 센서 융합 과제에서 공기역학 과제보다 높은 정확도를 보였는데, 이는 현재 AI가 감각 정보 통합에는 강하지만 동적 물리 법칙 추론에는 상대적으로 약함을 보여준다.
계획 및 자원 판단 부문에서 Qwen3 235B는 경로 계획 81.5%, 다수 드론 협력 76.5%, 에너지 관리 71.5%로 평균 76.5%를 달성했으나, 최고 성능 모델도 다수 드론 협력과 에너지 관리에서는 80%를 넘지 못했다. 이는 여러 드론이 함께 작동하며 에너지를 효율적으로 쓰는 판단이 여전히 어렵다는 것을 보여준다.
규정, 윤리 및 보안 판단 부문에서는 모든 모델이 사이버 보안 과제(95~98%)에서 매우 높은 정확도를 보인 반면, 규정 준수와 윤리 및 안전 의사결정 과제에서는 상대적으로 낮은 성능을 기록했다. Qwen3 235B는 규정 준수 76.0%, 윤리 의사결정 75.5%, 사이버 보안 96.5%로 평균 82.7%를 달성했다. 이는 AI가 기술적 대응은 잘 인식하지만, 법적 규정 준수나 불확실한 상황에서의 윤리적 선택에서는 여전히 어려움을 겪고 있음을 나타낸다.
시스템 비교 및 통합 판단 부문에서 Qwen3 235B는 시스템 비교 95.5%, 통합 판단 83.0%로 평균 89.3%를 기록했으나, 서로 다른 판단 영역을 하나로 통합하는 것은 여전히 어려운 과제로 남아 있다.
FAQ ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. UAVBench는 어떤 종류의 드론 임무를 평가할 수 있나요?
A: UAVBench는 시설물 점검, 배송, 정찰, 수색 구조, 여러 대 협력, 안전 중요 상황, 화재·유해물질 대응, 해양 작전 등 다양한 임무를 포함합니다. 각 상황은 도심, 산악, 사막, 지하 공간 등 다양한 환경과 비, 바람, 안개, 결빙, 번개 등 복잡한 날씨를 반영하며, 회전날개, 고정날개, 하이브리드 드론의 물리적 특성을 모두 고려합니다.
Q2. 왜 대부분의 AI 모델이 다수 드론 협력과 윤리 판단에서 낮은 점수를 받았나요?
A: 여러 대의 드론이 함께 작동할 때는 서로 부딪히지 않으면서 임무를 나눠야 하므로 복잡한 협력 판단이 필요합니다. 윤리 판단은 인간 안전, 법적 규정, 자원 제약 등 여러 가치를 동시에 고려해야 합니다. 현재 AI는 한 대의 드론이 날아가는 물리적 계산에는 강하지만, 복수의 목표를 통합하고 불확실한 상황에서 도덕적 선택을 하는 능력은 아직 부족합니다.
Q3. 균형 점수는 일반 정확도와 무엇이 다른가요?
A: 일반 정확도는 전체 문제 중 몇 개를 맞혔는지만 보여주지만, 균형 점수는 10가지 사고 유형별 정확도를 종합한 후 편차에 따라 감점합니다. 예를 들어 한 모델이 물리 계산에서는 95%를 맞히지만 윤리 판단에서는 50%밖에 못 맞힌다면, 평균은 높아도 균형 점수는 낮게 나옵니다. 안전이 중요한 드론 AI는 특정 영역에 치우치지 않고 모든 상황에서 고르게 잘 판단해야 하므로, 균형 점수가 더 신뢰할 수 있는 지표가 됩니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: UAVBench: An Open Benchmark Dataset for Autonomous and Agentic AI UAV Systems via LLM-Generated Flight Scenarios
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





