여러 AI가 함께 문제를 풀면 더 정확한 답을 낼 수 있다는 아이디어가 주목받고 있다. 하지만 미국 버지니아공대 연구진이 발표한 논문에 따르면, 모든 질문에 AI끼리 토론을 시키면 연산 비용만 폭증하고 오히려 정답률이 떨어질 수 있다. 이에 연구진은 ‘iMAD’라는 시스템을 개발했다. iMAD는 토론이 실제로 도움이 될 때만 선택적으로 작동해서, 비용은 92%까지 줄이면서 정답률은 오히려 13.5%나 높였다.
AI 여러 개 쓰면 좋다던데, 비용은 5배 정확도는 고작 5%
요즘 대형 언어모델 기반 AI 시스템은 혼자서도 복잡한 문제를 단계별로 풀어낼 수 있다. 하지만 한 AI만 쓰면 생각의 폭이 좁아서 다른 해결 방법을 놓칠 수 있다. 그래서 등장한 게 ‘멀티 에이전트 토론’ 방식이다. 여러 AI가 각자 답을 내고 서로 비판하면서 더 나은 답을 찾아가는 것이다.
그런데 문제가 있었다. 연구진이 6개 데이터셋으로 실험해보니, 이 토론 방식은 혼자 푸는 것보다 토큰을 3배에서 5배나 더 많이 썼다. 토큰은 AI가 글자를 처리하는 단위인데, 많이 쓸수록 비용이 늘어난다. 특히 이미지가 포함된 질문에서는 비용이 더 컸다. 정답률은 1.5%에서 5.3% 정도 올랐지만, 비용 대비 효율이 떨어졌다.
더 심각한 건 토론이 항상 도움이 되는 게 아니라는 점이다. 연구진이 분석해보니 토론으로 오답이 정답으로 바뀌는 경우는 전체의 5%에서 19%뿐이었다. 나머지는 이미 정답이거나, 토론해도 못 푸는 문제거나, 심지어 정답을 오답으로 바꿔버리는 경우도 있었다. 예를 들어 수학 문제 데이터에서는 19.1%가 토론으로 정답이 됐지만, 14%는 정답이 오답으로 뒤집혔다.
“확신 있으면 혼자, 헷갈리면 토론” 판단하는 AI 분류기
기존 방식은 AI가 내놓은 ‘확신도 점수’로 토론 여부를 결정했다. 확신도가 낮으면 토론시키고, 높으면 그냥 넘어가는 식이다. 하지만 연구진은 이 점수가 믿을 만하지 않다는 걸 발견했다. 오답인데도 확신도가 높게 나오는 경우가 많았고, 답변 내용이 불확실해 보여도 점수는 높게 나왔다.
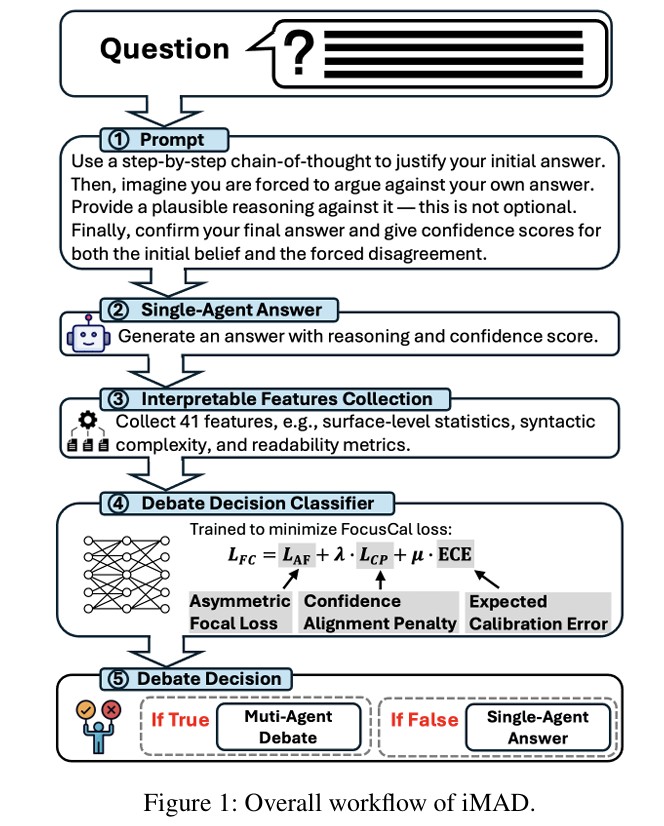
iMAD는 이 문제를 새로운 방식으로 해결했다. AI에게 답을 내게 한 뒤, 반드시 자기 답변을 반박하는 다른 의견도 내놓으라고 시킨다. “이렇게 생각하지만, 저렇게 볼 수도 있다”는 식이다. 양쪽 의견이 비슷하게 그럴듯하면 AI가 헷갈리고 있다는 뜻이니 토론이 도움이 될 수 있다. 반대로 한쪽이 명확하게 강하면 이미 답이 정해진 거라 토론할 필요가 없다.
이 과정에서 연구진은 41가지 특징을 뽑아낸다. 답변이 얼마나 길고 복잡한지, “아마도” 같은 망설이는 표현은 얼마나 쓰는지, 문장 구조는 어떤지 등을 분석한다. 이 특징들을 작은 인공신경망에 넣어서 토론을 할지 말지 판단한다. 이 신경망은 ‘FocusCal’이라는 특별한 학습 방법으로 훈련됐는데, 과신하는 오류에 큰 벌점을 주고, 확신도 점수와 실제 내용의 불일치도 처벌한다.
6개 실험에서 모두 1등, 비용은 10분의 1 수준으로
연구진은 의료 시험 문제, 전문 자격증 문제, 초등 수학 문제, 이미지 보고 답하는 문제 등 6가지 종류로 실험했다. 비교 대상은 혼자 푸는 방식 2개, 무조건 토론하는 방식 2개, 확신도로 선택하는 방식 1개였다.
결과는 놀라웠다. iMAD는 모든 실험에서 비용을 대폭 줄이면서도 정답률을 높였다. 의료 문제에서는 무조건 토론 방식보다 토큰을 68%에서 92%까지 줄였는데도 정답률이 가장 높았다. 수학 문제에서는 기존 토론 방식보다 정답률이 8.4%나 높았다. 전체적으로 혼자 푸는 것보다 최대 13.5% 정답률이 올랐다.
확신도 기반 방식과 비교하면, 비슷한 비용으로 더 높은 정답률을 냈다. 확신도 방식은 평가 데이터로 기준값을 조정해야 하는데, iMAD는 그럴 필요 없이 새로운 문제에서도 잘 작동했다. 신경망을 단 2개 데이터로만 학습시켰는데도 6개 새로운 데이터에서 모두 효과가 있었다.
토론 결정 95.9%가 적중, “쓸데없는 연산 안 했다”
iMAD의 판단이 얼마나 정확한지 분석해봤더니, 최대 95.9%가 올바른 결정이었다. 토론을 건너뛴 경우 65%에서 80%는 이미 정답이었고, 최대 13%는 토론해도 못 푸는 문제라 연산 낭비를 피한 것이었다. 토론을 시킨 경우에는 수학 문제에서 16.2%, 의료 문제에서 7.1%의 오답을 정답으로 바꿨다.
잘못된 결정, 즉 정답을 오답으로 바꾸거나 필요 없는 토론을 시킨 경우는 5%에서 10%에 불과했다. 연구진은 이 시스템을 구글의 Gemini뿐 아니라 OpenAI의 GPT-5, 중국의 Qwen 3.0에서도 테스트했는데 모두 비슷한 성과를 냈다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. AI 토론 시스템이 뭔가요?
A: 여러 AI가 같은 문제를 각자 풀고, 서로의 답을 비판하면서 더 나은 답을 찾아가는 방식입니다. 사람들이 회의에서 토론하듯이 AI끼리도 의견을 주고받으면 더 정확한 결론에 도달할 수 있다는 아이디어입니다.
Q2. iMAD는 언제 토론을 시키나요?
A: AI가 답변할 때 자기 의견과 반대 의견을 모두 내놓게 한 뒤, 둘 다 그럴듯하면 헷갈리고 있다고 판단해 토론을 시킵니다. 한쪽이 명확하게 강하면 이미 답이 정해진 거라 토론 없이 그냥 답을 냅니다.
Q3. 어떤 문제에서 가장 효과가 좋나요?
A: 복잡한 수학 문제나 의료 지식처럼 단계별로 생각해야 하는 문제에서 특히 효과적입니다. 반대로 사진을 보고 답하는 문제인데 중요한 단서가 없으면, 토론해도 답을 못 찾아서 효과가 적습니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: iMAD: Intelligent Multi-Agent Debate for Efficient and Accurate LLM Inference
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





