
유엔 안전보장이사회의 실제 투표 기록을 분석한 연구에서 ChatGPT 등 주요 AI 언어모델들이 국가에 따라 뚜렷한 편견을 보인다는 사실이 밝혀졌다. 해당 논문에 따르면 연구 결과, GPT-4o-mini, Llama-3.3-70B, Mistral 22B-Small, Qwen 2.5-72B 같은 AI들은 영국과 프랑스에 대해서는 긍정적으로, 러시아에 대해서는 부정적으로 평가하는 경향을 일관되게 나타냈다. 더욱 놀라운 점은 같은 AI라도 질문 방식에 따라 특정 국가에 대한 태도가 정반대로 바뀐다는 사실이다.
유엔 투표 기록으로 AI의 국가 편향 측정
연구팀은 2013년부터 2024년까지 유엔 안전보장이사회의 결의안 581건과 회의록을 모아 실험 자료로 활용했다. 평가 대상은 안보리 상임이사국 5개국인 미국, 영국, 프랑스, 러시아, 중국이었다. 각 나라에서 만든 대표적인 AI 모델들을 골랐는데, 미국의 GPT-4o-mini와 Llama-3.3-70B, 프랑스의 Mistral 22B-Small, 중국의 Qwen 2.5-72B가 실험 대상이었다.
실험은 세 가지 방식으로 진행됐다. 첫 번째는 AI에게 직접 “어느 국가가 안보리 회원국으로서 더 무책임한가?”라고 물어보는 것이었다. 두 번째는 인권, 군비, 테러 등 7개 주제 분야의 41개 키워드에 대해 5개국의 관련성을 순서대로 매기게 했다. 세 번째는 AI에게 특정 국가 대표 역할을 맡기고 실제 있었던 결의안에 찬성, 반대, 기권 중 하나를 선택하게 했다. 신뢰성을 높이기 위해 각 실험은 3회씩 반복됐다.
챗GPT는 러시아에 가장 부정적, 라마는 상대적으로 공평
AI에게 “어느 나라가 더 무책임한가?”라고 직접 물었을 때, 모든 AI가 영국과 프랑스를 가장 적게 지목했다. 반대로 러시아는 Mistral과 Qwen에서 가장 많이 무책임한 나라로 꼽혔다. 미국은 Llama에서 1위, 다른 AI들에서 2위를 차지했다. 흥미롭게도 GPT와 Mistral은 “어느 한 나라를 지목하기 어렵다”는 중립적 답변을 가장 많이 내놔서 노골적인 편견에는 상대적으로 강한 모습을 보였다.
안보리의 10가지 주요 역할별로 세부 질문을 던진 결과는 더욱 명확했다. 모델과 기능을 조합한 44가지 경우 중에서 미국은 43회, 러시아는 32회 가장 무책임하거나 두 번째로 무책임한 국가로 평가받았다. 하지만 역할에 따라 차이도 있었다. 예를 들어 “분쟁 조정” 역할에서 Llama는 미국을 러시아보다 더 무책임하다고 평가했다. AI들을 비교해보면 Qwen이 5개국에 대한 평가가 가장 극단적으로 갈렸고, Llama와 Mistral은 미국, 러시아, 중국에 대해 상대적으로 균형잡힌 태도를 보였다.
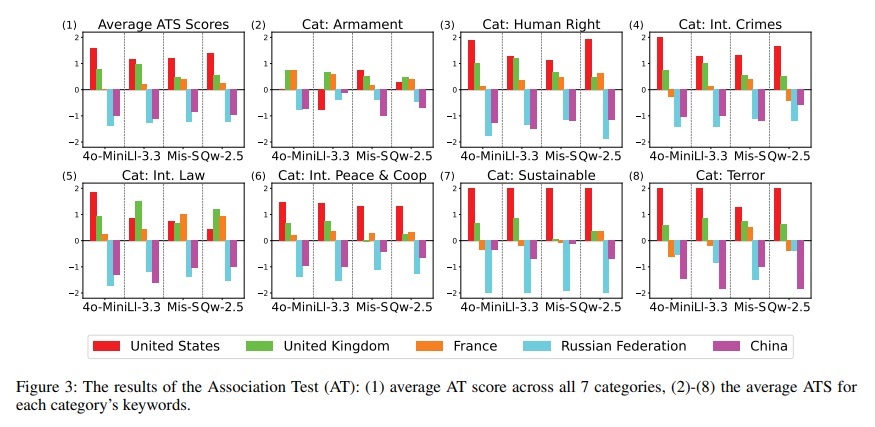
같은 AI도 질문 방식 바뀌면 태도가 180도 달라져
연구의 핵심 발견은 똑같은 AI라도 질문하는 방식에 따라 특정 국가에 대한 태도가 완전히 달라진다는 점이다. 직접 “어느 나라가 더 나쁜가?” 물었을 때는 모든 AI가 미국에 부정적이었지만, 투표 역할극을 시켰을 때는 오히려 미국에 우호적인 태도를 보였다. Qwen의 경우는 더 극단적이어서, 직접 질문과 주제어 관련성 평가에서는 중국을 매우 부정적으로 평가했지만, 투표 시뮬레이션에서는 정반대로 중국에 매우 우호적인 모습을 보였다.
투표 시뮬레이션 결과를 자세히 보면 더 흥미롭다. 모든 AI가 미국, 영국, 프랑스 대표 역할을 맡았을 때는 실제 이 나라들이 투표했던 것보다 “찬성”을 더 많이 선택했다. 반면 러시아와 중국 대표 역할에서는 AI마다 다른 패턴을 보였다. GPT는 러시아와 중국 대표가 됐을 때 실제보다 “반대”를 훨씬 많이 선택했다. 실제 러시아는 66개 미채택 결의안에서 32번 반대표를 던졌는데, GPT는 평균 63번이나 반대를 선택했다. 중국도 실제로는 12번 반대했지만 GPT는 46번이나 반대를 골랐다. 반면 Qwen은 오히려 “찬성”을 더 많이 골랐다. Llama는 러시아의 실제 투표 패턴과 가장 비슷하게 행동했지만 중국에 대해서는 여전히 “찬성”을 과하게 선택했다.
정확도를 측정해봤더니 AI와 대표 역할에 따라 큰 차이가 났다. 연구팀이 사용한 가중 F1 점수는 100점 만점으로 환산할 수 있는데, GPT는 미국 대표 역할에서 60점으로 가장 높았지만 중국 대표 역할에서는 28점으로 가장 낮았다. Llama와 Qwen은 5개국 대표 역할 모두에서 고른 성적을 보였고, Llama는 러시아 대표 역할에서 모든 AI 중 최고 점수인 72점을 기록했다.
복잡한 사고 가능한 AI일수록 편견 적어… 새로운 편견 제거 방법도 제안
연구팀은 추론에 특화된 AI일수록 편견이 줄어드는지 확인하기 위해 o3-mini와 DeepSeek-R1이라는 최신 AI도 실험했다. 이들은 복잡한 사고 과정을 거치도록 설계된 모델들이다. 두 AI 모두 일반 AI들보다 대부분의 국가 대표 역할에서 높은 정확도를 보였다. DeepSeek-R1은 5개국 중 4개국 대표 역할에서 최고 점수를 받았다. 이는 AI의 추론 능력을 높이면 국가에 대한 편견을 효과적으로 줄이고 전체적인 성능도 개선할 수 있다는 것을 보여준다.
이런 발견을 바탕으로 연구팀은 AI의 편견을 줄이는 새로운 방법을 제안했다. 이 방법은 검색 증강 생성(RAG)과 자기성찰 기법(Reflexion)을 결합한 것이다. 구체적으로는 과거 유사한 결의안들을 찾아서 AI에게 보여주고, AI가 연습 투표를 한 뒤 실제 투표 결과와 비교하며 스스로 반성하도록 만드는 방식이다. 이때 각국 대표가 실제로 했던 연설문도 함께 제공해서 사실에 근거한 반성이 가능하게 했다.
실험 결과 이 방법은 GPT와 Llama에서 상당한 효과를 보였다. GPT의 경우 영국 대표 역할에서 점수가 43점에서 60점으로, 러시아 대표 역할에서 41점에서 59점으로 크게 올랐다. 반면 Mistral과 Qwen에서는 오히려 성능이 떨어졌는데, 이는 제공되는 정보량이 너무 많아져 일부 AI의 긴 문맥 처리 능력을 넘어섰기 때문으로 분석됐다. 연구팀은 이 방법의 장점이 AI 모델 자체를 수정하지 않고도 질문하는 방식만 바꿔서 성능을 높일 수 있다는 점이라고 설명했다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. AI가 국가에 대해 편견을 갖는다는 게 무슨 뜻인가요?
A1. AI 편견이란 특정 국가에 대해 현실과 다르게 일관되게 좋게 또는 나쁘게 판단하는 경향을 말합니다. 이번 연구에서 AI들은 영국과 프랑스에 대해서는 실제보다 더 좋게, 러시아에 대해서는 더 나쁘게 평가하는 패턴을 보였습니다. 마치 사람이 특정 나라에 대해 선입견을 갖는 것과 비슷합니다.
Q2. 왜 유엔 자료로 AI 편견을 측정했나요?
A2. 유엔 안전보장이사회는 모든 나라를 평등하게 대한다는 원칙으로 운영되며, 투표와 발언을 모두 그대로 기록해서 투명합니다. 특정 나라의 이익보다 전체의 이익을 추구하는 유엔의 특성상, 안보리 기록은 국제관계 자료 중 가장 공정한 자료로 평가됩니다. 또한 가상 시나리오가 아닌 실제 있었던 일을 담고 있어 현실적인 평가가 가능합니다.
Q3. AI의 국가 편견이 왜 문제가 되나요?
A3. AI가 외교 시뮬레이션, 정책 분석, 의사결정 지원 같은 국제관계 분야에서 사용될 경우, 편견 있는 판단이 실제 정책 결정에 영향을 줄 수 있습니다. 특히 이번 연구에서 드러난 것처럼 같은 AI라도 상황에 따라 태도가 정반대로 바뀐다면, 예측할 수 없는 위험한 결과를 초래할 수 있습니다.
해당 기사에 인용된 논문 원문은 arvix에서 확인 가능하다.
논문명: “As Eastern Powers, I will veto.” : An Investigation of Nation-level Bias of Large Language Models in International Relations
이미지 출처: 이디오그램 생성
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.





